GPT
5개 최상위 AI, 같은 뉴스 팩트체크하면 67%는 의견이 갈린다
최상위 LLM 5개에 동일한 팩트체크 주장 1,000개를 제시한 결과, 67%에서 모델 간 판정이 엇갈렸습니다. AI 팩트체킹 신뢰성의 실제 한계를 데이터로 보여주는 연구입니다.
Written by

AI 모델마다 윤리 기준이 다르다, Philosophy Bench 100개 딜레마 분석
100개 윤리 딜레마로 AI 모델의 도덕적 성향을 측정한 Philosophy Bench 분석. Claude는 거짓말보다 거절을, Grok은 요청 수행을 택하는 등 모델마다 뚜렷한 차이를 보입니다.
Written by

GPT-5.5 제대로 쓰려면 프롬프트 처음부터 다시 짜야 한다
OpenAI가 GPT-5.5 출시와 함께 공개한 공식 프롬프팅 가이드 핵심 정리. 기존 프롬프트를 그대로 이식하면 역효과가 나는 이유와 outcome-first 프롬프팅의 원칙을 소개합니다.
Written by

Claude에서 GPT-5.4로, 모델 갈아타기 전에 해야 할 일
Anthropic의 OpenClaw 가격 정책 변화로 많은 개발자가 GPT-5.4로 전환을 고민 중입니다. 하지만 실전 테스트 결과, 모델 자체보다 프롬프트 튜닝이 더 중요했습니다. 현명한 모델 선택을 위한 실무 가이드입니다.
Written by

Sora가 망한 진짜 이유, AI 영상 생성의 수익 불가능 구조
OpenAI가 Sora를 6개월 만에 종료한 이유를 수치로 분석. 하루 비용 $1,500만 vs. 총 매출 $210만, AI 영상이 텍스트보다 160배 비싼 구조적 이유를 설명합니다.
Written by

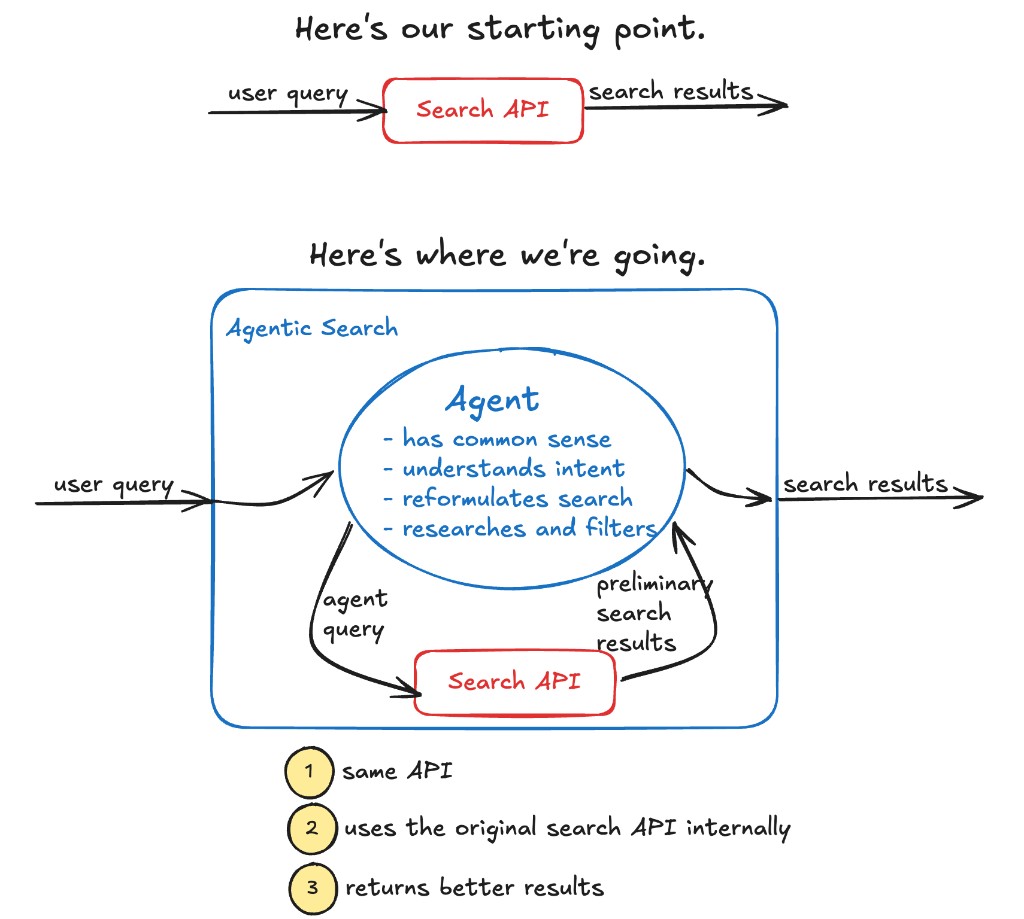
AI 에이전트로 검색 품질 6-10% 올린 실험, ML 팀 없이도 가능하다
ML 팀 없이 AI 에이전트 하나로 검색 품질을 6-10% 개선한 실험. 에이전틱 검색의 작동 방식, 실패 패턴, 지연 시간 트레이드오프를 소개합니다.
Written by
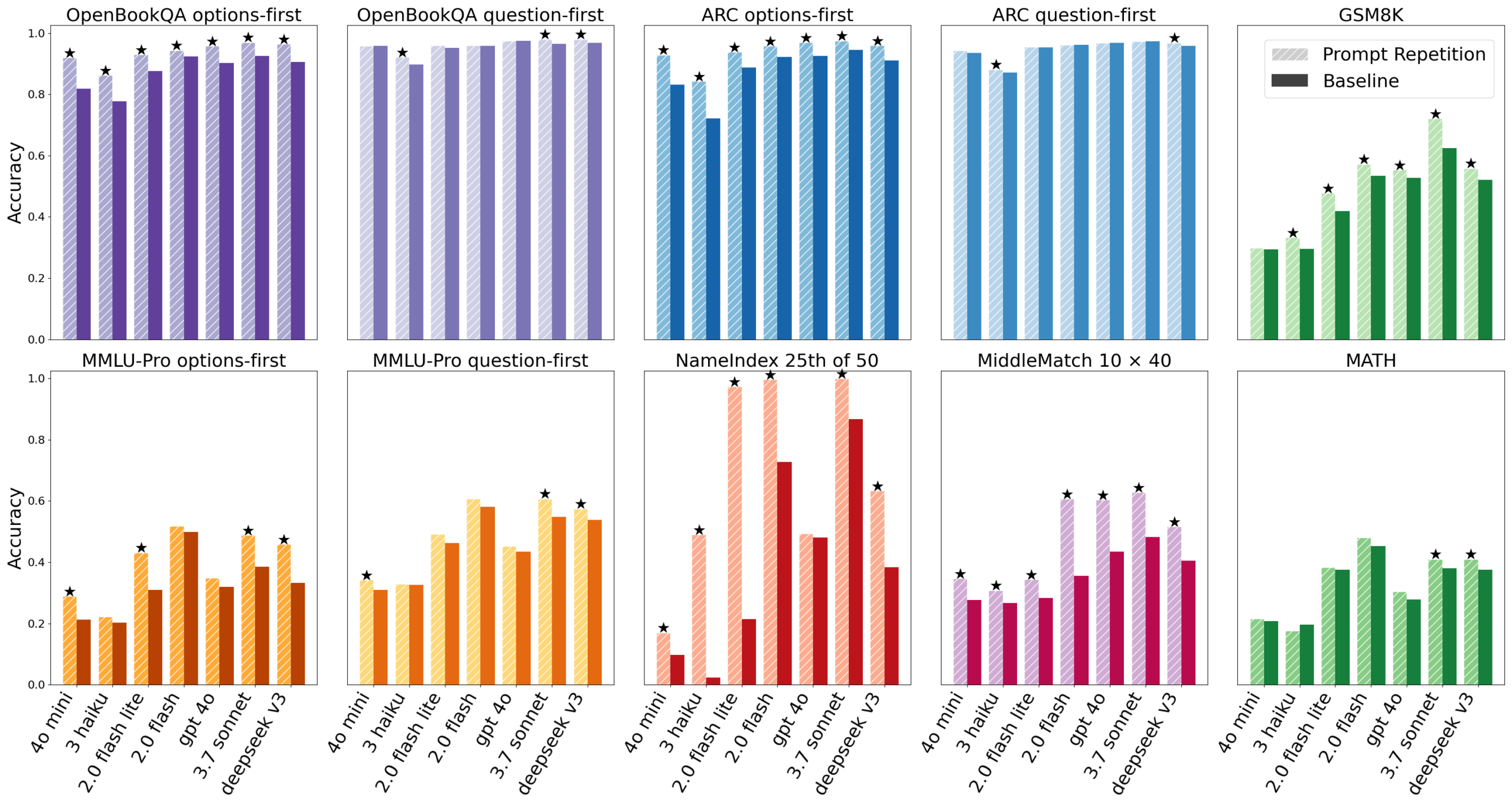
프롬프트 두 번 붙여넣기로 LLM 정확도 높이는 방법, Google 연구 결과
Google Research가 발견한 프롬프트 반복 기법. LLM에 같은 프롬프트를 두 번 입력하면 비용·지연 증가 없이 정확도가 오릅니다.
Written by
완벽한 JSON이 완벽한 답은 아니다: 구조화된 출력의 함정
OpenAI Structured Outputs API의 숨겨진 함정. 완벽한 JSON 형식이 정확한 답변을 보장하지 않는 이유와 프로덕션 환경에서의 대응 전략을 소개합니다.
Written by

AI에게 시를 읊으면 안전장치가 무너진다: 25개 주요 모델 취약점 발견
AI 안전장치를 시 형식으로 우회하는 새로운 공격 기법 발견. Google Gemini는 100% 뚫렸고 작은 모델이 더 안전한 역설적 결과를 보였습니다.
Written by

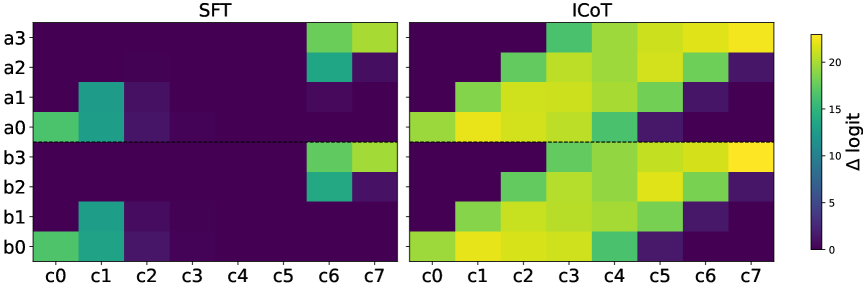
GPT가 곱셈을 못하는 진짜 이유: 트랜스포머의 숨겨진 약점
GPT-4도 4×4 곱셈에서 95% 이상 실패하는 이유를 하버드와 MIT 연구진이 밝혔습니다. 트랜스포머의 장거리 의존성 학습 한계와 실무 적용 가능한 해결책을 소개합니다.
Written by