훈련 데이터를 더 많이 줘도 소형 LLM은 배우지 못하는 능력들이 있습니다. 단지 학습 속도가 느린 게 아니라, 사전훈련 과정에서 구조적으로 학습 자체가 불가능한 상태에 빠지기 때문입니다.

Stanford, Harvard Kempner Institute, MIT, Anthropic 연구자들이 공동으로 발표한 논문이 대형 LLM이 소형 모델은 배우지 못하는 태스크를 습득하는 이유를 훈련 역학 관점에서 규명했습니다. 단순히 “큰 모델이 더 빠르게 배운다”는 기존 설명을 넘어, 소형 모델이 사전훈련 중 특정 태스크를 학습하지 못하는 메커니즘을 이론과 실험 양면에서 보여줍니다.
출처: Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention – Huang et al., arXiv
소형 모델이 빠지는 그래디언트 간섭 루프
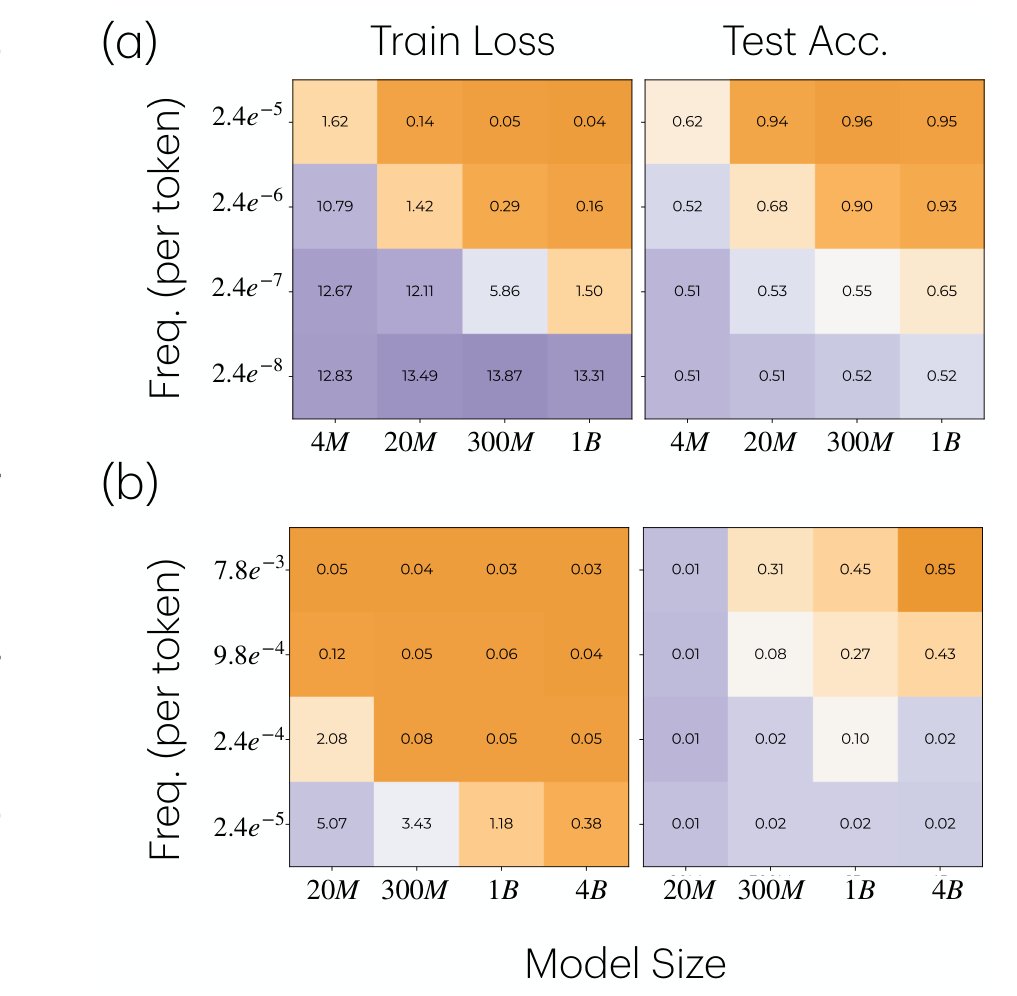
연구팀이 발견한 핵심 메커니즘은 그래디언트 간섭(gradient interference)입니다. 모델을 훈련할 때는 수많은 태스크가 뒤섞인 데이터가 사용되는데, 자주 등장하는 태스크는 매 학습 단계마다 모델 파라미터를 강하게 자신의 방향으로 끌어당깁니다.
희귀하거나 복잡한 태스크는 잠깐 학습되더라도 곧바로 다음 스텝의 빈번한 태스크 업데이트에 덮어쓰여 버립니다. 다음에 해당 태스크 예시가 나타나면 모델은 처음부터 다시 시작해야 합니다. 소형 모델은 파라미터 수가 적어 빈번한 태스크를 완전히 소화하지 못한 채로 계속 강한 간섭을 받기 때문에, 희귀하고 복잡한 태스크의 학습 신호는 쌓이지 않고 계속 지워집니다. 한 가지 중요한 맥락은, 이 한계가 사전훈련 단계에 국한된다는 점입니다. 논문은 소형 모델이 같은 태스크를 파인튜닝으로는 여전히 학습할 수 있음을 명시합니다.
대형 모델이 같은 문제를 피하는 이유
대형 모델에서는 같은 상황이 다르게 전개됩니다. 파라미터가 충분히 많으면 빈번한 태스크를 먼저 대부분 소화해 버립니다. 그 시점부터 빈번한 태스크의 그래디언트 간섭이 약해지고, 여유 용량이 생겨 희귀하고 복잡한 태스크의 학습 신호가 배치 사이에 축적되기 시작합니다.
연구팀은 4백만~40억 파라미터의 OLMo 모델들을 Dolma v1.7 코퍼스로 훈련하며 이를 직접 측정했습니다. 2,000만 파라미터 소형 모델에서는 희귀 태스크의 학습 신호가 다른 언어 훈련의 그래디언트 잡음 속에 완전히 묻혔습니다. 10억 파라미터 모델에서는 같은 상황에서 잡음 수준이 거의 0에 가까웠고, 신호가 온전히 살아남았습니다.
모듈식 덧셈 태스크에서는 그로킹(grokking) 현상도 관찰됐습니다. 모델이 먼저 개별 예시들을 암기한 뒤, 충분한 훈련 후 어느 순간 태스크의 실제 원리를 갑자기 깨닫는 현상입니다. 이 전환점에 도달한 건 대형 모델뿐이었고, 그것도 태스크가 충분히 자주 등장했을 때만 가능했습니다.
암기는 일반화로 가는 길목
그로킹 실험에서 드러나는 또 다른 시각은 암기의 역할입니다. 일반적으로 암기는 진짜 이해가 아닌 것, 피해야 할 것으로 여겨집니다. 하지만 이 연구에서 암기는 일반화의 선행 조건입니다. 모델이 개별 예시들을 충분히 오래 기억해야 여러 배치에 걸쳐 패턴이 형성되기 때문입니다. 그 기억을 유지하는 데 필요한 게 바로 그래디언트 간섭 없이 신호를 쌓아갈 수 있는 파라미터 용량입니다.
이 원리는 실용적인 대안도 열어줍니다. 특정 능력을 모델에 심으려면 반드시 더 큰 모델이 필요한 건 아닙니다. 해당 태스크를 훈련 데이터에서 더 자주 등장하도록 구성하는 것도 효과적인 방법이 될 수 있습니다.
창발 능력 논쟁에 새로운 단서
이 연구는 스케일링 논의에 “데이터 중심적(data-centric)” 관점을 추가합니다. 큰 모델이 더 잘하는 건 단순히 표현력이 더 크기 때문이 아니라, 주어진 데이터 혼합에서 그래디언트 기반 최적화를 통해 무엇을 학습할 수 있는가의 문제라는 것입니다.
지난 5월 MIT 연구팀은 모델이 차원 이상으로 개념들을 중첩(superposition)해서 저장하는 기하학적 구조로 스케일링 법칙을 설명했습니다. 이번 연구는 그와 다른 각도, 훈련 데이터 구성이 학습 역학에 미치는 영향에서 출발합니다. 큰 모델에서의 능력이 진짜 창발인지 아니면 측정 방식의 문제인지를 둘러싼 논쟁은 아직 정리되지 않았습니다. 하지만 이번 연구는 그 현상의 배경에 있는 훈련 역학의 한 조각을 명확히 보여주고, 모델 크기 이외의 경로도 가능성으로 제시합니다.
참고자료:
답글 남기기