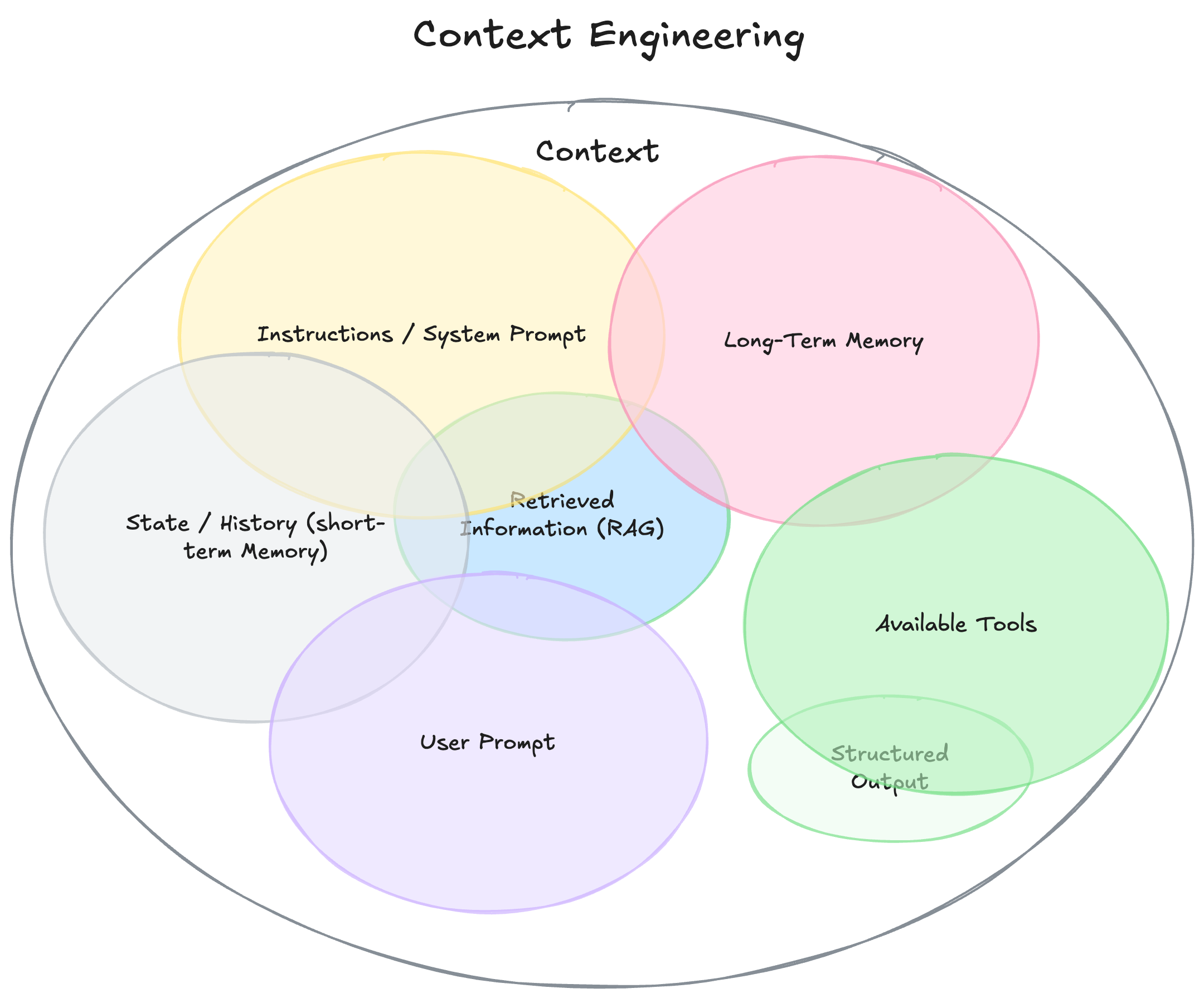
AI 에이전트의 컨텍스트 구성 요소들 (출처: Philipp Schmid)
당신의 AI 에이전트가 기대만큼 똑똑하게 작동하지 않는다면, 문제는 모델 자체가 아닐 가능성이 높습니다. 실제로 최신 LLM들의 성능은 이미 충분히 뛰어나지만, 대부분의 에이전트가 실패하는 이유는 컨텍스트 설계에 있습니다.
최근 AI 개발 현장에서는 “컨텍스트 엔지니어링”이라는 새로운 접근법이 주목받고 있습니다. 이는 단순히 좋은 프롬프트를 작성하는 것을 넘어서, AI가 올바른 판단을 내릴 수 있도록 시스템 차원에서 정보 흐름을 설계하는 것입니다. 이번 글에서는 실무에서 바로 적용할 수 있는 구체적인 컨텍스트 엔지니어링 전략들을 소개합니다.
컨텍스트 윈도우: AI 에이전트의 작업 메모리
컨텍스트 엔지니어링을 이해하려면 먼저 컨텍스트 윈도우의 개념을 알아야 합니다. 이는 LLM이 한 번에 처리할 수 있는 정보의 범위로, 사람의 작업 메모리와 유사합니다.
문제는 이 “작업 메모리”가 제한적이라는 점입니다. 현재 최고 성능의 모델도 컨텍스트 윈도우에는 한계가 있으며, 여기에 어떤 정보를 담느냐에 따라 성능이 극명하게 갈립니다. 컨텍스트 관리가 부실하면 비용 증가, 응답 지연, 부정확한 결과라는 3중고에 시달리게 됩니다.
성공하는 에이전트 vs 실패하는 에이전트
같은 모델을 사용해도 결과가 천차만별인 이유를 구체적인 시나리오로 살펴보겠습니다.
시나리오: 고객이 채팅봇에 “최근 주문이 언제 배송되나요?”라고 문의
기본형 에이전트 (단순 RAG 방식):
컨텍스트: 배송 정책 문서 3개 조각
응답: "일반적으로 주문 후 3-5일 내에 배송됩니다. 주문번호를 알려주시면 더 정확한 정보를 드릴 수 있습니다."고도화된 에이전트 (컨텍스트 엔지니어링 적용):
수집된 컨텍스트:
- 고객 ID: C001 (VIP 등급)
- 최근 주문: #ORD-2024-1234 (어제 결제)
- 현재 상태: 포장 완료, 오늘 출고 예정
- 배송지: 서울 (익일 배송 가능 지역)
- 고객 이력: 배송 관련 문의 2회 (신경쓰는 타입)
응답: "안녕하세요! 어제 주문해주신 #ORD-2024-1234번 상품이 현재 포장이 완료되어 오늘 오후에 출고 예정입니다. VIP 회원님이시니 내일 오전에 받아보실 수 있을 것 같습니다. 배송 추적은 출고 후 1시간 내에 SMS로 발송해드리겠습니다."두 번째 응답이 훨씬 더 유용한 이유는 시스템적으로 수집된 풍부한 컨텍스트 때문입니다.
실전 구현: 7가지 핵심 전략
이제 실무에서 바로 적용할 수 있는 구체적인 전략들을 살펴보겠습니다. 각 전략은 독립적으로도 효과적이지만, 조합하여 사용할 때 시너지 효과를 발휘합니다.
전략 1: 적응형 컨텍스트 라우팅
핵심 아이디어: 요청의 특성에 따라 동적으로 컨텍스트 소스를 선택
class ContextRouter:
def route_context(self, user_query, user_profile):
context_sources = []
# 쿼리 분석을 통한 동적 라우팅
if self.is_product_inquiry(user_query):
context_sources.extend([
'product_catalog',
'inventory_status',
'user_purchase_history'
])
if self.requires_personal_info(user_query):
context_sources.extend([
'user_profile',
'preference_history',
'recent_interactions'
])
return self.fetch_context(context_sources, user_profile.priority)실제 적용 사례:
- 기술 지원 요청 → 제품 매뉴얼 + 최근 버그 리포트 + 사용자 환경
- 일반 문의 → FAQ + 이전 대화 + 사용자 선호도
- 주문 관련 → 주문 이력 + 배송 정보 + 프로모션 데이터
전략 2: 계층적 메모리 아키텍처
핵심 아이디어: 정보를 중요도와 접근 빈도에 따라 계층화
class HierarchicalMemory:
def __init__(self):
self.immediate_context = {} # 현재 대화
self.session_memory = {} # 세션 범위
self.long_term_memory = {} # 영구 저장
def get_context(self, query, max_tokens=4000):
context = []
remaining_tokens = max_tokens
# 우선순위: 즉시 → 세션 → 장기
for memory_layer in [self.immediate_context,
self.session_memory,
self.long_term_memory]:
relevant_info = self.retrieve_relevant(query, memory_layer)
token_cost = self.estimate_tokens(relevant_info)
if token_cost <= remaining_tokens:
context.append(relevant_info)
remaining_tokens -= token_cost
else:
# 토큰 한계에 도달하면 요약
context.append(self.summarize(relevant_info, remaining_tokens))
break
return context전략 3: 지능형 컨텍스트 압축
핵심 아이디어: 정보 손실 최소화하면서 토큰 사용량 최적화
class ContextCompressor:
def compress_context(self, raw_context, target_tokens):
# 1단계: 중복 제거
deduplicated = self.remove_duplicates(raw_context)
# 2단계: 중요도 기반 필터링
scored_content = self.score_relevance(deduplicated)
# 3단계: 계층적 요약
if self.estimate_tokens(scored_content) > target_tokens:
return self.hierarchical_summarize(scored_content, target_tokens)
return scored_content
def hierarchical_summarize(self, content, target_tokens):
# 세부사항 → 요약 → 핵심 사실 순으로 압축
summary_levels = [
self.detailed_summary,
self.key_points_summary,
self.essential_facts_only
]
for summarizer in summary_levels:
compressed = summarizer(content)
if self.estimate_tokens(compressed) <= target_tokens:
return compressed
return compressed # 마지막 레벨까지 압축전략 4: 실시간 컨텍스트 품질 모니터링
핵심 아이디어: 컨텍스트 효과성을 실시간으로 측정하고 개선
class ContextQualityMonitor:
def __init__(self):
self.metrics = {
'relevance_score': 0.0,
'completeness_score': 0.0,
'freshness_score': 0.0,
'cost_efficiency': 0.0
}
def evaluate_context_quality(self, context, query, response):
# 관련성 평가
relevance = self.calculate_relevance(context, query)
# 완성도 평가 (응답에서 "정보가 부족합니다" 등의 표현 탐지)
completeness = self.check_information_gaps(response)
# 신선도 평가 (컨텍스트 정보의 최신성)
freshness = self.evaluate_data_freshness(context)
# 비용 효율성 (토큰 대비 품질)
efficiency = self.calculate_cost_efficiency(context, response)
return {
'overall_score': (relevance + completeness + freshness + efficiency) / 4,
'improvement_suggestions': self.generate_suggestions()
}전략 5: 도구 기반 동적 컨텍스트 확장
핵심 아이디어: 필요시에만 외부 정보를 실시간으로 가져와 컨텍스트에 추가
class DynamicContextExpander:
def expand_context(self, initial_context, query, available_tools):
expanded_context = initial_context.copy()
# 컨텍스트 갭 분석
missing_info = self.analyze_context_gaps(query, initial_context)
for gap in missing_info:
if gap.type == 'real_time_data':
tool_result = self.call_tool('fetch_live_data', gap.parameters)
expanded_context.append(self.format_tool_result(tool_result))
elif gap.type == 'user_specific':
user_data = self.call_tool('get_user_profile', gap.user_id)
expanded_context.append(self.format_user_context(user_data))
elif gap.type == 'domain_knowledge':
domain_info = self.call_tool('search_knowledge_base', gap.domain)
expanded_context.append(self.format_domain_context(domain_info))
return expanded_context전략 6: 컨텍스트 캐싱 및 재사용
핵심 아이디어: 자주 사용되는 컨텍스트 패턴을 캐시하여 성능 향상
class ContextCache:
def __init__(self):
self.cache = {}
self.usage_patterns = {}
def get_cached_context(self, context_key, ttl=3600):
if context_key in self.cache:
cached_item = self.cache[context_key]
if time.time() - cached_item['timestamp'] < ttl:
self.update_usage_pattern(context_key)
return cached_item['context']
return None
def store_context(self, context_key, context_data):
self.cache[context_key] = {
'context': context_data,
'timestamp': time.time(),
'usage_count': 1
}
def optimize_cache(self):
# 사용 빈도 기반 캐시 최적화
sorted_items = sorted(
self.cache.items(),
key=lambda x: x[1]['usage_count'],
reverse=True
)
# 상위 20% 항목만 유지
keep_count = max(1, len(sorted_items) // 5)
self.cache = dict(sorted_items[:keep_count])전략 7: 멀티모달 컨텍스트 통합
핵심 아이디어: 텍스트, 이미지, 구조화된 데이터를 통합한 풍부한 컨텍스트 구성
class MultimodalContextBuilder:
def build_context(self, text_data, image_data, structured_data):
unified_context = []
# 텍스트 컨텍스트 처리
text_context = self.process_text_context(text_data)
unified_context.append({
'type': 'text',
'content': text_context,
'weight': 0.4
})
# 이미지 컨텍스트 처리 (시각적 정보 추출)
if image_data:
image_context = self.extract_visual_context(image_data)
unified_context.append({
'type': 'visual',
'content': image_context,
'weight': 0.3
})
# 구조화된 데이터 처리
if structured_data:
structured_context = self.format_structured_data(structured_data)
unified_context.append({
'type': 'structured',
'content': structured_context,
'weight': 0.3
})
return self.merge_contexts(unified_context)실제 도구와 프레임워크 활용
앞서 소개한 전략들을 실제로 구현할 때 도움이 되는 주요 도구들과 그 활용법을 살펴보겠습니다.
LlamaIndex: 종합 컨텍스트 관리 플랫폼
핵심 기능:
- LlamaExtract: 복잡한 문서에서 구조화된 데이터 추출
- Workflows: 멀티스텝 에이전트 워크플로우 관리
- Memory Blocks: 다양한 메모리 패턴 지원
# LlamaIndex를 활용한 컨텍스트 파이프라인
from llama_index.core import VectorStoreIndex, ServiceContext
from llama_index.memory import VectorMemoryBlock
class LlamaContextPipeline:
def __init__(self):
self.vector_memory = VectorMemoryBlock()
self.fact_extractor = FactExtractionMemoryBlock()
def build_context(self, query, user_id):
# 1. 벡터 검색으로 관련 문서 찾기
relevant_docs = self.vector_memory.retrieve(query)
# 2. 사용자별 사실 추출
user_facts = self.fact_extractor.get_facts(user_id)
# 3. 컨텍스트 조합 및 최적화
return self.optimize_context(relevant_docs + user_facts)LangChain & LangSmith: 관찰 가능한 컨텍스트 시스템
from langchain.callbacks import LangChainTracer
from langchain.memory import ConversationSummaryBufferMemory
class ObservableContextSystem:
def __init__(self):
self.tracer = LangChainTracer()
self.memory = ConversationSummaryBufferMemory(
max_token_limit=2000,
return_messages=True
)
def process_with_tracing(self, query):
# 모든 컨텍스트 단계를 추적
with self.tracer:
context = self.build_context(query)
response = self.generate_response(context, query)
# LangSmith에서 컨텍스트 품질 분석 가능
return responseAutoGen: 멀티 에이전트 컨텍스트 협업
import autogen
class MultiAgentContextSystem:
def setup_agents(self):
# 컨텍스트 수집 전문 에이전트
context_agent = autogen.AssistantAgent(
name="context_collector",
system_message="당신은 사용자 요청에 필요한 모든 컨텍스트 정보를 수집하는 전문가입니다."
)
# 응답 생성 전문 에이전트
response_agent = autogen.AssistantAgent(
name="response_generator",
system_message="수집된 컨텍스트를 바탕으로 최적의 응답을 생성합니다."
)
return [context_agent, response_agent]성능 측정과 최적화
컨텍스트 효율성 지표
컨텍스트 엔지니어링의 효과를 측정할 수 있는 핵심 지표들:
class ContextMetrics:
def calculate_metrics(self, context, response, user_feedback):
return {
'context_utilization': self.measure_context_usage(context, response),
'relevance_score': self.calculate_relevance(context, response),
'cost_efficiency': self.calculate_cost_per_quality_unit(context),
'user_satisfaction': user_feedback.rating,
'response_accuracy': self.verify_factual_accuracy(response),
'context_freshness': self.measure_data_recency(context)
}
def measure_context_usage(self, context, response):
"""컨텍스트 중 실제로 활용된 부분의 비율"""
used_info = self.extract_referenced_info(context, response)
total_info = len(context)
return len(used_info) / total_info if total_info > 0 else 0A/B 테스트를 통한 컨텍스트 최적화
class ContextABTester:
def run_experiment(self, control_strategy, test_strategy, user_queries):
results = {'control': [], 'test': []}
for query in user_queries:
# 50:50 분할
if random.random() < 0.5:
context = control_strategy.build_context(query)
group = 'control'
else:
context = test_strategy.build_context(query)
group = 'test'
response = self.generate_response(context, query)
metrics = self.evaluate_response(response, query)
results[group].append(metrics)
return self.analyze_significance(results)실제 적용 사례: 업종별 베스트 프랙티스
E-commerce 고객 서비스
class EcommerceContextBuilder:
def build_customer_context(self, customer_id, query):
context_layers = [
self.get_customer_profile(customer_id), # 기본 정보
self.get_order_history(customer_id), # 구매 이력
self.get_recent_interactions(customer_id), # 최근 문의
self.get_product_context(query), # 상품 관련 정보
self.get_current_promotions(), # 현재 프로모션
self.get_inventory_status(query) # 재고 상태
]
# 중요도 가중치 적용
weighted_context = self.apply_weights(context_layers, {
'customer_profile': 0.2,
'order_history': 0.25,
'recent_interactions': 0.2,
'product_context': 0.15,
'current_promotions': 0.1,
'inventory_status': 0.1
})
return self.compress_to_token_limit(weighted_context, 3000)의료 진단 지원 시스템
class MedicalContextBuilder:
def build_diagnostic_context(self, patient_id, symptoms):
# HIPAA 규정 준수하면서 컨텍스트 구성
context = {
'patient_demographics': self.get_anonymized_demographics(patient_id),
'medical_history': self.get_relevant_history(patient_id, symptoms),
'current_medications': self.get_current_prescriptions(patient_id),
'lab_results': self.get_recent_lab_results(patient_id),
'clinical_guidelines': self.get_relevant_guidelines(symptoms),
'drug_interactions': self.check_drug_interactions(patient_id)
}
# 의료 정보 특성상 모든 컨텍스트가 중요하므로 압축보다는 분할 처리
return self.segment_context_by_priority(context)코딩 어시스턴트
class CodingContextBuilder:
def build_coding_context(self, repository_path, current_file, user_intent):
context = {
'project_structure': self.analyze_project_structure(repository_path),
'current_file_content': self.get_file_content(current_file),
'related_files': self.find_related_files(current_file),
'recent_changes': self.get_git_history(repository_path, days=7),
'dependencies': self.analyze_dependencies(repository_path),
'test_files': self.find_relevant_tests(current_file),
'documentation': self.extract_relevant_docs(user_intent)
}
# 코딩 컨텍스트는 정확성이 중요하므로 압축보다는 정확한 정보 제공
return self.prioritize_by_relevance(context, user_intent)성공 사례와 ROI
실제 기업들이 컨텍스트 엔지니어링을 도입하여 얻은 성과:
사례 1: SaaS 고객지원 개선
- Before: 평균 응답 정확도 65%, 고객 만족도 3.2/5
- After: 평균 응답 정확도 89%, 고객 만족도 4.4/5
- 핵심 전략: 고객별 사용 패턴과 이전 문의 이력을 컨텍스트에 통합
사례 2: 금융 리스크 분석
- Before: 분석 시간 평균 45분, 놓치는 리스크 요소 20%
- After: 분석 시간 평균 12분, 놓치는 리스크 요소 5%
- 핵심 전략: 실시간 시장 데이터와 고객 포트폴리오 정보의 동적 통합
사례 3: 콘텐츠 개인화 추천
- Before: 클릭률 2.3%, 구매 전환율 0.8%
- After: 클릭률 7.1%, 구매 전환율 2.4%
- 핵심 전략: 사용자 행동 패턴, 선호도, 실시간 상황 정보의 멀티레이어 컨텍스트
미래 전망: 차세대 컨텍스트 시스템
예측 컨텍스트 (Predictive Context)
class PredictiveContextSystem:
def predict_future_needs(self, user_pattern, current_context):
# 사용자 패턴 분석을 통해 미래 컨텍스트 요구사항 예측
predicted_needs = self.ml_model.predict(user_pattern)
# 예측된 정보를 미리 캐시
for need in predicted_needs:
if need.probability > 0.7:
self.pre_cache_context(need.context_type, need.parameters)
return predicted_needs자가 진화 컨텍스트 (Self-Evolving Context)
class SelfEvolvingContext:
def evolve_context_strategy(self, success_metrics, user_feedback):
# 성공 패턴 학습
successful_patterns = self.analyze_success_patterns(success_metrics)
# 컨텍스트 전략 자동 조정
self.context_strategy = self.genetic_algorithm.evolve(
current_strategy=self.context_strategy,
fitness_function=self.calculate_fitness,
success_patterns=successful_patterns
)
return self.context_strategy컨텍스트 엔지니어링은 단순한 기술적 개선이 아닙니다. 이는 AI와 인간의 협업 방식을 근본적으로 바꾸는 패러다임 전환입니다. 앞서 소개한 7가지 전략을 단계적으로 적용하면서, 여러분만의 컨텍스트 시스템을 구축해보세요.
가장 중요한 것은 측정 가능한 지표를 설정하고 지속적으로 개선해나가는 것입니다. 완벽한 컨텍스트 시스템은 하루아침에 만들어지지 않습니다. 하지만 올바른 방향으로 꾸준히 발전시켜 나간다면, 진정으로 똑똑하고 유용한 AI 에이전트를 만날 수 있을 것입니다.
참고자료:
답글 남기기