Apple Machine Learning Research와 매사추세츠대가 개발한 ARTER는 모든 케이스에 LLM을 사용하는 대신, 쉬운 문제는 빠른 모델로, 어려운 문제만 LLM으로 처리하는 적응형 라우팅을 통해 비용을 절반 이하로 줄이면서도 정확도는 오히려 향상시켰습니다.

핵심 포인트:
- 선택적 LLM 사용으로 토큰 58% 절감: 전체 케이스의 50~67%를 빠른 모델로 처리하고 복잡한 케이스만 LLM으로 라우팅하여 입력 토큰 58%, 출력 토큰 59% 감소
- 정확도는 오히려 향상: ReFinED 대비 평균 2.53% 성능 향상. MSNBC 데이터셋에서는 4.47%까지 개선되며, 모든 케이스에 LLM을 쓰는 방식과 비교해도 1% 이내 차이
- 파인튜닝 없이 즉시 적용 가능: 대규모 데이터셋과 모델 재학습 없이 프롬프트 기반으로 작동해 새로운 도메인에 빠르게 적응
Entity Linking, 왜 어려운가
Entity Linking은 텍스트에서 언급된 단어가 실제로 무엇을 가리키는지 정확히 찾아내는 기술입니다. “Target이 1.52달러 하락했다”는 문장에서 ‘Target’이 기업인지, 목표물인지, 다른 의미인지 판단하는 것이죠. 간단해 보이지만 실제로는 여러 도전 과제가 있습니다.
맥락 부족 문제. 짧은 텍스트에서는 충분한 단서를 얻기 어렵습니다. “NPR news in Washington”에서 Washington이 워싱턴 D.C.인지, 워싱턴주인지, 조지 워싱턴인지 확신하기 어렵습니다.
어휘 모호성. 같은 단어가 여러 의미를 가집니다. Apple은 과일, 기업, 레코드 레이블일 수 있습니다. Java는 프로그래밍 언어, 인도네시아 섬, 커피를 의미할 수 있습니다.
배경지식 요구. “Big Apple”이 뉴욕시를 뜻한다는 건 텍스트에 명시되지 않은 배경지식입니다. 이런 경우 단순 텍스트 매칭으로는 해결이 안 됩니다.
전통적인 Entity Linking 시스템은 대규모 레이블 데이터셋과 광범위한 파인튜닝에 의존했습니다. 새로운 도메인에 적응하기 어렵고, 복잡한 케이스를 제대로 처리하지 못했죠. 최근에는 LLM을 활용한 프롬프트 기반 방식이 등장했지만, 모든 케이스에 LLM을 호출하면 비용이 급증하고 처리 속도가 느려지는 문제가 있었습니다.
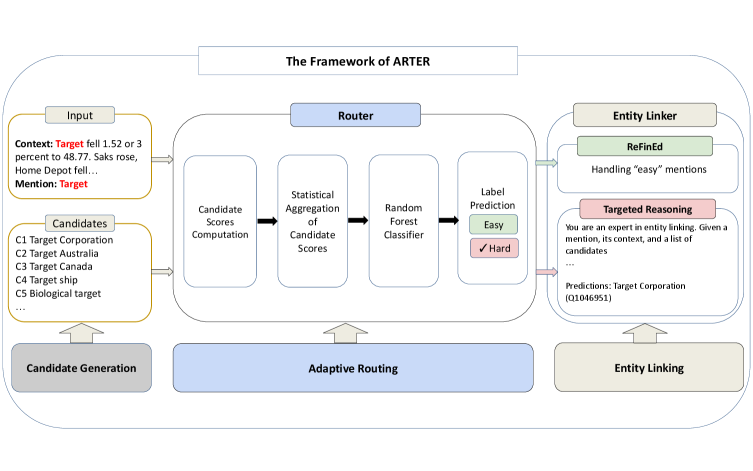
ARTER의 3단계 전략
ARTER는 이 문제를 해결하기 위해 간단하면서도 효과적인 접근법을 택했습니다. 모든 케이스를 동일하게 처리하는 대신, 난이도에 따라 다른 전략을 적용하는 것입니다.
1단계: 후보 생성
먼저 ReFinED의 후보 생성 모듈을 활용해 각 언급(mention)마다 30개의 후보 개체를 추출합니다. Wikipedia를 지식 베이스로 사용하며, Wikidata에서 추가 메타데이터를 가져옵니다. 예를 들어 “Target”이라는 단어가 나오면 Target Corporation, Target Australia, Target Canada 등 가능한 개체들을 모두 찾아냅니다.
2단계: 라우터가 난이도 분류
여기가 ARTER의 핵심입니다. 라우터는 각 케이스를 ‘쉬운’ 케이스와 ‘어려운’ 케이스로 분류합니다. 이를 위해 네 가지 신호를 계산합니다.
맥락-개체 유사도는 주변 문장과 후보 개체의 설명이 얼마나 일치하는지 측정합니다. 멘션-개체 유사도는 언급된 단어와 개체 이름의 유사성을 봅니다. 후보 간 유사도는 후보들끼리 얼마나 비슷한지 확인합니다. 이게 높으면 구분하기 어렵다는 뜻이죠. 마지막으로 작은 LLM(Llama 3.1 8B)이 각 후보에 대한 신뢰도 점수를 제공합니다.
이 네 가지 신호를 통계적으로 집계해서 Random Forest 분류기에 입력합니다. 분류기는 AIDA 학습 데이터셋에서 ReFinED의 예측 결과를 바탕으로 학습됩니다. ReFinED가 맞힌 케이스는 ‘쉬움’, 틀린 케이스는 ‘어려움’으로 레이블링하죠.

3단계: 선택적 LLM 추론
쉬운 케이스는 ReFinED가 직접 처리합니다. 빠르고 효율적이며 대부분의 경우 정확합니다. 어려운 케이스만 LLM으로 보냅니다. 이때 few-shot 예시와 Chain-of-Thought 추론을 결합한 프롬프트를 사용합니다.
구체적인 예를 볼까요. “Target fell 1.52 or 3 percent to 48.77″이라는 문장에서 ‘Target’을 판단해야 한다면, LLM은 이렇게 추론합니다. 맥락이 주식 시장 관련이고, Home Depot, Saks 같은 소매업체와 함께 언급됩니다. 1.52달러 하락은 주가 변동을 나타냅니다. 후보 중 Target Corporation만 미국 증시에 상장된 기업입니다. 따라서 정답은 Target Corporation입니다.
벤치마크 결과가 말하는 것
ARTER는 6개의 표준 벤치마크에서 테스트되었습니다. AIDA, MSNBC, ACE2004, AQUAINT, CWEB, WIKI 데이터셋이죠. 결과는 명확했습니다.
정확도 향상. ReFinED 단독 사용 대비 ACE2004에서 3.52%, MSNBC에서 4.47%, AIDA에서 2.46%, CWEB에서 2.09% 개선되었습니다. 6개 데이터셋 중 5개에서 평균 2.53% 향상을 보였습니다.
비용 절감. 데이터셋에 따라 전체 케이스의 50.4%에서 67.3%가 쉬운 케이스로 분류되었습니다. 이들은 LLM 없이 처리되어 입력 토큰 사용량이 평균 58.25%, 출력 토큰 사용량이 59.25% 감소했습니다. 출력 토큰이 일반적으로 더 비싸다는 점을 고려하면 실제 비용 절감은 더 큽니다.
모델 선택의 자유. 연구팀의 테스트(약 2천만 개 입력 토큰, 80만 개 출력 토큰 처리)에서 Claude 3 Haiku는 87.5% 정확도에 약 6달러, DeepSeek은 85.58% 정확도에 약 4.5달러가 소요되었습니다. 반면 Claude Opus 4(360달러)나 GPT-4.1(46달러) 같은 프리미엄 모델은 비용이 수십 배 높지만 정확도는 소폭만 개선됩니다.
흥미로운 점은 모든 케이스에 LLM을 쓰는 ‘Full Prompting’ 방식과 비교해도 성능 차이가 1% 이내라는 것입니다. 절반의 비용으로 거의 같은 성능을 낸다는 의미죠.
실무 적용을 위한 고려사항
ARTER의 접근법은 Entity Linking을 넘어 더 넓은 함의를 갖습니다. 모든 작업에 동일한 컴퓨팅 리소스를 쓸 필요가 없다는 것이죠.
검색 엔진에서는 대부분의 쿼리를 빠른 모델로 처리하고, 복잡한 질문만 LLM으로 보낼 수 있습니다. 질문-답변 시스템은 사실 확인이 간단한 질문과 추론이 필요한 질문을 구분할 수 있습니다. 지식 추출 플랫폼은 명확한 개체와 애매한 개체를 다르게 처리할 수 있죠.
라우터 설계는 목적에 따라 조정 가능합니다. ARTER는 쉬운 케이스의 정확도를 우선시했습니다. 어려운 케이스를 쉽다고 잘못 판단하면 틀릴 가능성이 높지만, 쉬운 케이스를 어렵다고 판단하면 비용만 약간 더 들 뿐 여전히 맞힐 수 있기 때문입니다.
파인튜닝이 필요 없다는 점도 큰 장점입니다. 새로운 도메인이나 업데이트된 지식 베이스에 바로 적용할 수 있습니다. 프롬프트만 조정하면 되니까요.
앞으로의 과제
ARTER는 효율적이지만 몇 가지 한계도 있습니다. 연구팀은 예산과 컴퓨팅 제약으로 더 많은 LLM을 테스트하지 못했습니다. LLM을 후보 생성 단계에도 활용하는 실험은 아직 하지 않았죠. 라우터의 다양한 파라미터 설정이 정확도에 미치는 영향도 체계적으로 연구하지 못했습니다.
그럼에도 ARTER가 제시한 방향은 명확합니다. 적응형 컴퓨팅이 효율과 성능을 동시에 잡을 수 있다는 것입니다. 모든 문제에 최고 성능의 모델을 쓸 필요는 없습니다. 문제의 난이도를 정확히 판단하고, 적절한 도구를 선택하는 것이 더 현명한 전략입니다.
참고자료:
답글 남기기