AI 에이전트 튜토리얼은 넘쳐나지만, 실제 회사에서 매일 쓰는 에이전트를 만든 이야기는 드뭅니다. 대부분은 데모 수준에 그치죠. 하지만 Tiger Data팀은 다릅니다. 그들은 6주 만에 회사 직원 50%가 매일 사용하는 Slack 에이전트 Eon을 구축했고, 그 과정에서 배운 모든 것을 오픈소스로 공개했습니다.
더 흥미로운 점은 이들이 부딪힌 문제가 “어떻게 LLM을 호출하는가”가 아니라 “어떻게 프로덕션 수준의 안정성을 확보하는가”였다는 겁니다. 에이전트가 대화 맥락을 잃으면? API가 다운되면? 동시에 수십 명이 질문하면? 실제 서비스에서는 이런 문제들이 끊임없이 발생합니다.
시간을 이해하는 메모리
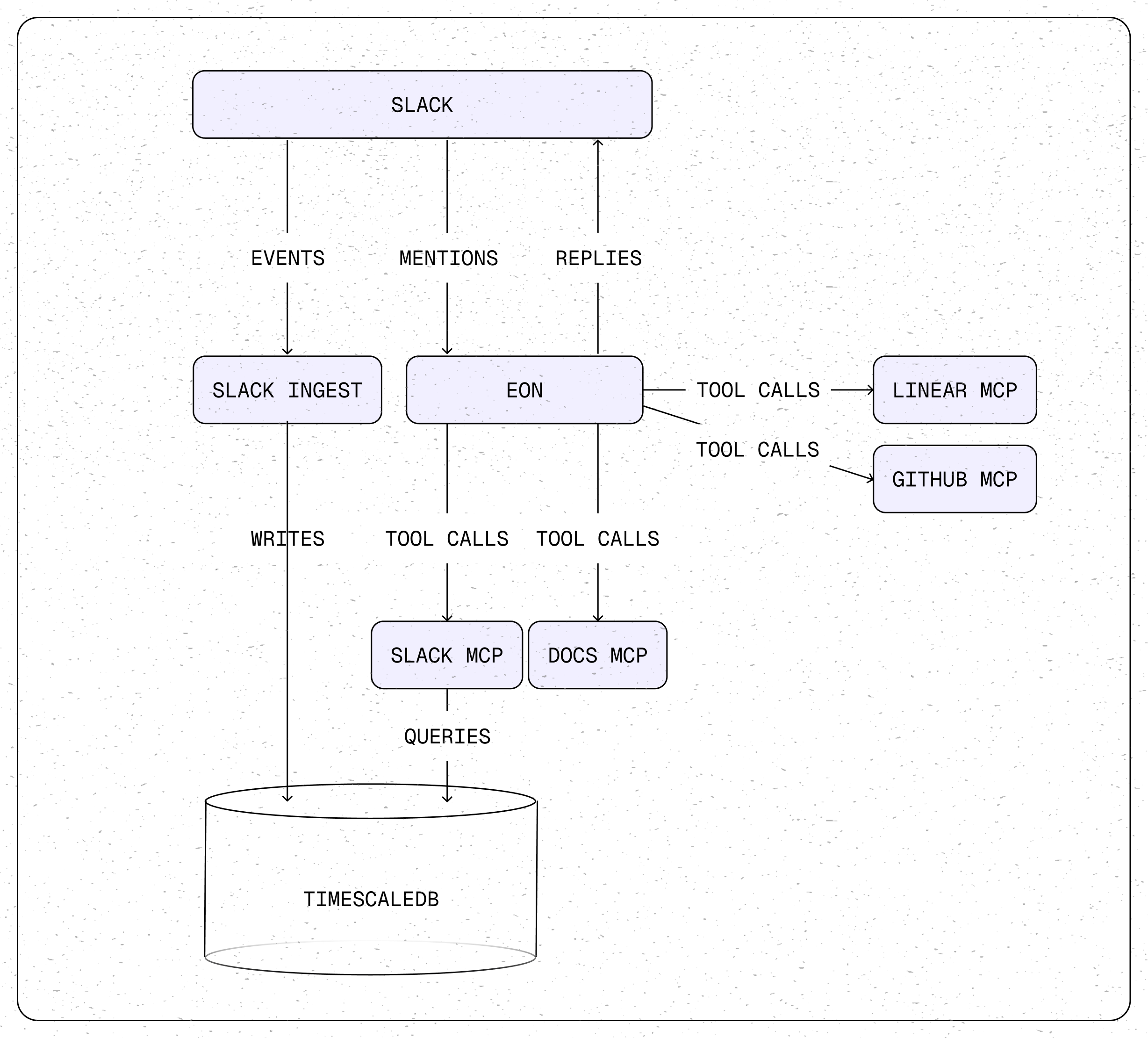
첫 번째 도전은 대화의 흐름을 이해하는 것이었습니다. Slack에서 누군가 Eon을 멘션하면, Slack은 그 단일 메시지만 전송합니다. 이전 대화 내용은 없죠. “그거 어떻게 됐어?”라는 질문은 맥락 없이는 무의미합니다.
해결책은 의외로 간단했습니다. Slack 대화는 본질적으로 시계열 데이터입니다. 각 메시지는 타임스탬프, 발신자, 채널, 스레드 정보를 가지고 있죠. Tiger Data팀은 모든 Slack 메시지를 TimescaleDB에 실시간으로 수집하는 시스템을 구축했습니다. 이제 Eon은 SQL로 대화 기록을 조회하며, API 속도 제한이나 복잡한 REST 호출 없이 완벽한 맥락을 파악합니다.
메모리를 구축한다는 것은 단순히 저장하는 게 아니라 시간의 순서와 관계를 이해하는 시스템을 만드는 것이었습니다.
범용 MCP 서버의 함정
Eon은 Slack뿐 아니라 GitHub, Linear, 문서 등 여러 데이터 소스에 접근해야 했습니다. 여기서 Model Context Protocol(MCP)이 등장합니다. MCP는 에이전트가 외부 도구와 데이터에 접근하는 표준 방식을 제공하죠.
문제는 공식 MCP 서버들이 범용으로 설계되어 있다는 점입니다. 예를 들어 공식 GitHub MCP 서버는 수십 개의 도구를 제공하지만, 실제로 Eon에 필요한 건 “PR 검색”과 “이슈 토론 조회” 정도였습니다. 불필요한 도구들은 토큰만 낭비하고 모델에 혼란을 주죠.
더 큰 문제는 API 구조 자체입니다. 공식 Linear MCP 서버로 이슈 정보를 가져오려면 여러 번의 API 호출이 필요합니다. 먼저 이슈 목록을 가져오고, 각 이슈마다 댓글, 첨부파일, 라벨, 프로젝트 정보를 따로 조회해야 하죠. LLM이 이 작업을 수행할 수는 있지만, 느리고 비용이 많이 듭니다.
Tiger Data팀의 해결책은 사용자가 실제로 묻는 질문에 최적화된 MCP 서버를 직접 만드는 것이었습니다. 그들의 tiger-linear-mcp-server는 단 하나의 get_issues 도구로 모든 필요한 정보를 한 번에 가져옵니다. 내부적으로는 여러 API 호출을 하지만, 결과를 깔끔하게 정리해서 반환하죠. 이것이 컨텍스트 엔지니어링입니다.
프로덕션은 실패를 전제로 설계한다
회사 직원 절반이 의존하는 시스템은 “대부분 잘 작동”으로는 부족합니다. 모든 질문이 중요하고, 모든 답변이 누군가의 업무 흐름에 영향을 미치죠.
문제는 예측 불가능한 상황이 끊임없이 발생한다는 겁니다. 에이전트가 답변 중간에 크래시하면? GitHub API가 다운되면? 동시에 수십 명이 질문하면?
Tiger Data팀의 답은 데이터베이스 회사답게 내구성 있는 시스템 설계였습니다. 그들이 만든 tiger-agents-for-work 프레임워크는 네 가지 핵심 기능을 제공합니다:
내구성 있는 이벤트 처리: 모든 Slack 이벤트를 처리 전에 PostgreSQL에 기록합니다. 봇이 크래시해도 이벤트는 손실되지 않고 큐에 남아 재처리됩니다.
자동 재시도: 실패한 이벤트는 10분 간격으로 최대 3번 자동 재시도됩니다. 일시적 오류는 대부분 이 과정에서 해결되죠.
제한된 동시성: 고정 크기 워커 풀로 트래픽이 급증해도 시스템이 다운되지 않습니다. 요청은 PostgreSQL 큐에 차곡차곡 쌓이고, 워커가 가능할 때 순차적으로 처리됩니다.
밀리초 단위 응답: 폴링 대신 비동기 시그널링으로 새 이벤트가 도착하면 즉시 워커에 알립니다. 사용자는 즉각적인 응답을 느끼지만, 실제로는 내구성 있는 큐 위에서 작동하죠.
10분이면 시작할 수 있습니다
Tiger Data는 Eon의 전체 코드를 tiger-eon이라는 레퍼런스 구현으로 공개했습니다. 대화형 설치 스크립트가 포함되어 있어, git clone부터 Slack에서 작동하는 에이전트까지 약 10분이면 완성됩니다.
더 흥미로운 건 모듈식 설계입니다. 각 컴포넌트(Slack 메모리, GitHub/Linear MCP 서버, 에이전트 프레임워크)는 독립적으로 사용할 수 있습니다. 전체를 쓸 수도, 필요한 부분만 가져다 쓸 수도 있죠. 문서 검색 MCP 서버(tiger-docs-mcp-server)는 공개 서버로도 제공되어, Claude Desktop에 바로 추가하면 PostgreSQL 전문가를 옆에 둔 것처럼 작업할 수 있습니다.
이들이 증명한 것은 명확합니다. AI 에이전트는 특별한 인프라가 필요한 게 아니라 내구성 있는 이벤트 처리, 구조화된 메모리, 집중된 도구만 있으면 됩니다. 그리고 그 모든 것을 PostgreSQL 위에 구축할 수 있다는 것이죠.
참고자료:
- We Built a Production Agent (and Open-Sourced Everything We Learned)
- tiger-eon GitHub 저장소
- tiger-agents-for-work – 프로덕션 Slack 에이전트 프레임워크
- tiger-slack – Slack 대화 메모리 시스템
- tiger-docs-mcp-server – PostgreSQL 문서 검색 MCP 서버
답글 남기기