AI 검색이 중요해지면서 많은 기업들이 새로운 실험을 하고 있습니다. 사람은 절대 보지 않을 페이지, 오직 AI만을 위한 콘텐츠를 만드는 거죠. 마크다운 파일, JSON 피드, 심지어 /ai/ 경로 아래 사이트 전체를 복제하는 경우도 있습니다. ChatGPT나 Perplexity, Google AI Overviews에서 더 많이 인용되려는 시도입니다.
논리는 그럴듯합니다. AI가 읽기 쉽게 만들면 더 잘 인용되지 않을까요? 광고를 빼고, 메뉴를 제거하고, 순수한 텍스트만 제공하면요.

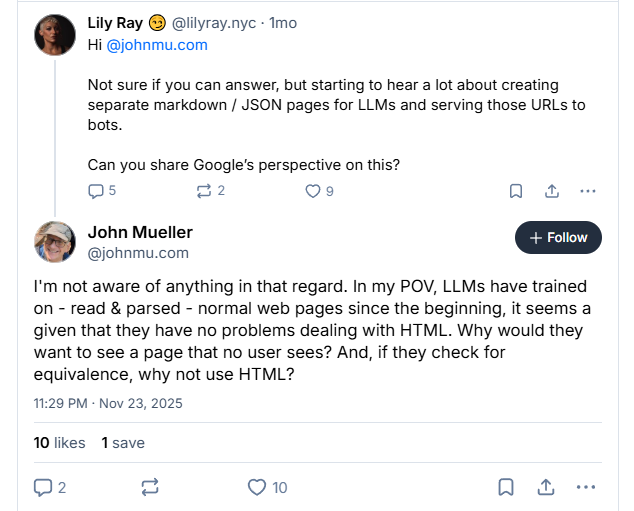
하지만 Google의 John Mueller는 이 접근법에 회의적입니다. “LLM은 처음부터 일반 웹페이지를 학습하고 파싱해왔습니다. 왜 사용자가 보지 않는 페이지를 보고 싶어 하겠어요?” 그는 LLM 전용 페이지를 오래전 사라진 keywords meta tag에 비유했습니다. 누구나 쓸 수 있지만, 실제로는 무시되는 기술이라는 거죠.
Search Engine Land가 LLM 전용 페이지 트렌드를 분석한 글을 발표했습니다. 실제 인용 데이터를 들여다보니 흥미로운 패턴이 발견됐습니다.
출처: Why LLM-only pages aren’t the answer to AI search – Search Engine Land
LLM 전용 페이지란 무엇인가
기업들이 시도하는 방식은 크게 네 가지입니다.
llms.txt 파일은 도메인 루트에 마크다운 형식으로 중요한 페이지 목록을 제공하는 방식입니다. Answer.AI 공동 창업자 Jeremy Howard가 2024년 9월에 제안했죠. Stripe, Cloudflare, Anthropic 같은 기술 기업들이 채택했습니다. docs.stripe.com/llms.txt에 가면 API 문서와 테스트 가이드 링크가 깔끔하게 정리되어 있습니다.
마크다운(.md) 페이지 복사본도 인기 있는 방법입니다. 일반 URL 뒤에 .md만 붙이면 됩니다. docs.stripe.com/testing이 있으면 docs.stripe.com/testing.md도 만드는 식이죠. CSS, JavaScript, 메뉴, 푸터를 모두 제거하고 순수한 텍스트만 남깁니다.
/ai나 /llm 경로로 콘텐츠 전체를 별도로 구축하는 곳도 있습니다. /about 페이지 옆에 /ai/about을 만들고, /products 옆에 /llm/products를 두는 거죠. 사람이 실수로 들어가면 2005년 웹사이트처럼 보입니다.
JSON 메타데이터 파일은 Dell 같은 이커머스 기업이 선호하는 방식입니다. 제품 스펙, 가격, 재고를 구조화된 JSON으로 제공합니다. “1000달러 이하 Dell 노트북 추천해줘” 같은 질문에 AI가 바로 답할 수 있도록요.
실제로 인용될까, 18,000개 데이터 분석
Peec AI의 Malte Landwehr는 이런 전략을 쓰는 5개 웹사이트를 대상으로 테스트를 진행했습니다. LLM 친화적 콘텐츠를 찾아낼 수 있도록 설계된 프롬프트를 만들었죠. 일부 질문에는 특정 소스를 유도하기 위해 20단어 이상의 직접 인용문까지 포함했습니다.
거의 18,000개의 인용을 분석한 결과는 놀라웠습니다.
llms.txt 인용률: 0.03%. 18,000개 중 단 6개만 llms.txt 파일을 인용했습니다. 그나마 인용된 6개는 공통점이 있었어요. API 사용법과 추가 문서를 찾는 곳처럼 진짜 유용한 정보가 들어 있었던 거죠. 검색 최적화를 위해 키워드를 채워넣은 llms.txt는 인용이 0건이었습니다.
마크다운(.md) 페이지: 0%. .md 복사본을 만든 사이트들은 3,500회 이상 인용됐습니다. 하지만 마크다운 버전을 인용한 경우는 단 한 건도 없었어요. 유일한 예외는 GitHub인데, 여기는 .md가 원래 표준 URL이고 HTML 대안이 없습니다.
/ai 페이지: 0.5%~16%. 결과가 엄청나게 달랐습니다. 어떤 사이트는 0.5%만 /ai 페이지로 인용됐고, 다른 곳은 16%까지 나왔어요. 차이는 뭘까요? 높은 성과를 낸 사이트는 /ai 페이지에 다른 곳에 없는 정보를 훨씬 더 많이 넣었습니다. 프롬프트가 이 콘텐츠를 찾도록 특별히 설계됐는데도 대부분의 질문은 /ai 버전을 무시했습니다.
JSON 메타데이터: 5%. 한 브랜드는 1,800개 인용 중 85개(5%)가 JSON 파일에서 나왔습니다. 중요한 건 이 파일에 웹사이트 다른 곳에는 없는 정보가 들어 있었다는 점입니다. 질문도 그 정보를 구체적으로 물어봤고요.

SE Ranking은 다른 방식으로 접근했습니다. 30만 개 도메인을 분석해서 llms.txt 채택과 인용 빈도 사이에 상관관계가 있는지 봤죠. 결과는? llms.txt가 있는 도메인은 10.13%뿐이었습니다. robots.txt나 XML 사이트맵처럼 보편적인 표준과는 거리가 멀었어요.
흥미로운 건 트래픽 수준에 따른 차이였습니다. 월 방문자 0~100명인 사이트의 9.88%가 llms.txt를 썼는데, 10만 명 이상 사이트는 8.27%만 썼습니다. 큰 사이트일수록 오히려 덜 쓰더군요.
머신러닝 모델로 인용 빈도를 예측했을 때, llms.txt를 변수에서 제거하니 정확도가 올라갔습니다. 이 파일이 예측에 도움이 되기는커녕 노이즈만 추가했던 거죠.
패턴은 명확합니다
두 분석 모두 같은 결론을 가리킵니다. LLM 전용 페이지가 인용되는 건 형식 때문이 아니라 독점적이고 유용한 정보가 들어 있기 때문입니다.
Landwehr의 결론은 직설적이었습니다. “12345.txt 파일을 만들어도 유용하고 독특한 정보만 있으면 인용됩니다.”
잘 구조화된 about 페이지는 /ai/about 페이지와 똑같은 효과를 냅니다. API 문서는 llms.txt에 있든 일반 문서 페이지에 묻혀 있든 인용됩니다.
파일 자체는 AI 시스템에게 특별 대우를 받지 못합니다. 안에 든 내용이 중요한데, 그것도 일반 페이지보다 실제로 나을 때만 효과가 있습니다.
Google과 AI 플랫폼의 입장
주요 AI 기업 중 어디도 llms.txt 파일을 크롤링이나 인용 과정에 사용한다고 확인하지 않았습니다.
Google의 John Mueller는 2025년 4월 가장 신랄한 비판을 했습니다. llms.txt를 구식이 된 keywords meta tag에 비유하며 이렇게 말했죠. “제가 아는 한 AI 서비스 중 LLMs.TXT를 쓴다고 말한 곳은 없습니다. 서버 로그를 보면 확인조차 하지 않는 게 보여요.”
Google의 Gary Illyes는 2025년 7월 방콕에서 열린 Search Central Deep Dive에서 이를 재확인했습니다. Google은 “LLMs.txt를 지원하지 않으며 계획도 없다”고 명시했어요.
Google Search Central 문서는 더 명확합니다. “SEO 모범 사례는 Google 검색의 AI 기능에도 유효합니다. AI Overviews나 AI Mode에 나타나기 위한 추가 요구사항은 없고, 특별한 최적화도 필요 없습니다.”
OpenAI, Anthropic, Perplexity는 모두 자사 API 문서를 위해 llms.txt를 운영합니다. 개발자들이 AI 어시스턴트에 쉽게 로드할 수 있도록요. 하지만 크롤러가 다른 웹사이트에서 이런 파일을 실제로 읽는다고 발표한 곳은 없습니다.
모든 주요 플랫폼의 메시지는 일관됩니다. 표준 웹 퍼블리싱 관행이 AI 검색 가시성을 높입니다. 특수 파일도, 새로운 마크업도, 별도 버전도 필요 없습니다.
SEO 팀이 해야 할 것
증거는 하나의 결론을 가리킵니다. 기계만 볼 콘텐츠 만들기를 멈추세요.
Mueller의 질문이 핵심을 찌릅니다. “사용자가 보지 않는 페이지를 왜 보고 싶어 하겠어요?” AI 기업들이 특수 형식이 필요했다면 말했을 겁니다. 그의 말대로 “AI 기업들은 수줍어하는 걸로 유명하지 않으니까요.”
데이터가 그를 뒷받침합니다. Landwehr의 18,000 인용 중 LLM 최적화 형식은 사이트 다른 곳에 없는 독점 정보가 포함된 경우를 제외하면 아무 이점도 보이지 않았습니다. SE Ranking의 30만 도메인 분석에서 llms.txt는 인용 예측 모델에 혼란만 가중시켰어요.
콘텐츠의 섀도우 버전을 만드는 대신 실제로 효과 있는 것에 집중하세요.
사람과 AI 모두 쉽게 파싱할 수 있는 깔끔한 HTML을 만드세요. 핵심 콘텐츠의 JavaScript 의존성을 줄이세요. Mueller가 지적한 진짜 기술적 장벽이 바로 이겁니다. “JavaScript를 제외하면요. 많은 시스템이 여전히 어려워하는 것 같습니다.” 무거운 클라이언트 사이드 렌더링은 AI 파싱에 실제 문제를 만듭니다.
플랫폼이 공식 사양을 발표했을 때만 구조화된 데이터를 쓰세요. OpenAI의 이커머스 제품 피드처럼요. 핵심 콘텐츠를 발견하기 쉽고 잘 정리되도록 정보 구조를 개선하세요.
AI 인용에 가장 좋은 페이지는 사용자에게도 좋은 페이지입니다. 잘 구조화되고, 명확하게 쓰여 있고, 기술적으로 건전한 페이지요. AI 기업들이 다른 공식 요구사항을 발표하기 전까지는 여기에 최적화 에너지를 쏟아야 합니다.
참고자료
- /llms.txt—a proposal to provide information to help LLMs use websites – Answer.AI (Jeremy Howard의 원본 제안)
- The /llms.txt file – llms.txt 공식 사이트
- AI Features and Your Website – Google Search Central 공식 문서
- Google says normal SEO works for ranking in AI Overviews and LLMS.txt won’t be used – Search Engine Land (Gary Illyes 발언)
- LLMs.txt Shows No Clear Effect On AI Citations, Based On 300k Domains – Search Engine Journal (SE Ranking 연구)
- LLMs.txt: Why Brands Rely On It and Why It Doesn’t Work – SE Ranking
- Google’s Mueller Questions Need For LLM-Only Markdown Pages – Search Engine Journal (John Mueller 발언)
- Optimizing for ChatGPT Shopping: How product feeds power GEO – Search Engine Land (OpenAI 제품 피드)
- Product Feed Spec – OpenAI 개발자 문서
답글 남기기