같은 AI 모델을 사용하는데도 어떤 코딩 에이전트는 신중하게 문서부터 읽고, 어떤 에이전트는 일단 코드를 짜보고 에러를 고치는 방식으로 움직입니다. 이 차이는 모델의 성능 차이가 아니라 ‘시스템 프롬프트’가 만들어낸 결과입니다.

Drew Breunig와 Srihari Sriraman이 공동으로 진행한 연구는 코딩 에이전트 6개(Claude Code, Cursor, Gemini CLI, Codex CLI, OpenHands, Kimi CLI)의 시스템 프롬프트를 분석하고 실험했습니다. 시스템 프롬프트가 모델의 숨겨진 편향을 드러낼 뿐 아니라, 에이전트의 작동 방식을 근본적으로 바꾼다는 사실을 발견했죠.
출처: How System Prompts Reveal Model Biases – nilenso blog
시스템 프롬프트에 숨겨진 모델의 편향
연구팀이 시스템 프롬프트를 뜯어본 결과, 거의 모든 코딩 에이전트가 같은 두 가지 문제와 싸우고 있었습니다.
첫 번째는 병렬 도구 호출 회피 성향입니다. Claude Code는 “여러 도구를 한 번에 호출할 수 있다”는 문장을 시스템 프롬프트에 7번 반복합니다. Cursor는 아예 ‘maximize_parallel_tool_calls’라는 섹션을 만들어서 대문자로 “CRITICAL INSTRUCTION”, “MANDATORY”, “DEFAULT TO PARALLEL”이라고 강조하죠. Gemini CLI와 Kimi CLI도 비슷한 지시를 반복합니다.
왜 이렇게까지 강조해야 할까요? 모델이 학습한 데이터 대부분이 순차적 작업 예시였기 때문입니다. 디버깅이 쉽고 학습 데이터 생성 시 지연이 문제되지 않아서죠. 하지만 실제 사용자는 속도를 원하기 때문에, 시스템 프롬프트로 이 성향을 억지로 바꿔야 합니다.
두 번째는 과도한 코드 주석 작성입니다. Cursor는 “당연한 코드에 주석 달지 마라”고 명시하고, Gemini는 “절대 주석으로 사용자와 대화하지 마라(NEVER)”고 경고합니다. Claude Code는 “사용자가 요청하지 않으면 주석 추가하지 말라”고 하고, 이전 버전의 Codex는 아예 “인라인 주석을 최대한 제거하라”고 지시했어요.
이런 편향은 모델이 학습한 코드 예시에서 비롯됩니다. 튜토리얼, 노트북, 경쟁 코딩 솔루션처럼 설명이 많은 코드가 학습 데이터에 과도하게 포함됐기 때문이죠. 실제로 Opus 4.5는 thinking 기능을 끄면 코드 주석 안에서 추론하는 모습이 관찰되기도 했습니다.
어떻게 분석했나
연구팀은 먼저 공개된 시스템 프롬프트를 수집해 정리했습니다. 그런 다음 context-viewer라는 도구로 각 프롬프트를 의미론적 구성요소로 쪼개 비교했어요. 이 과정에서 프롬프트들이 어디서 비슷하고 어디서 다른지를 시각화했죠.
실험 단계에서는 Claude Code가 제공하는 커스텀 시스템 프롬프트 기능을 활용했습니다. 같은 모델(Opus 4.5)에 서로 다른 시스템 프롬프트를 적용한 뒤, SWE-Bench Pro 문제를 풀게 하고 워크플로우를 비교 분석했습니다.
같은 모델, 다른 프롬프트, 완전히 다른 에이전트
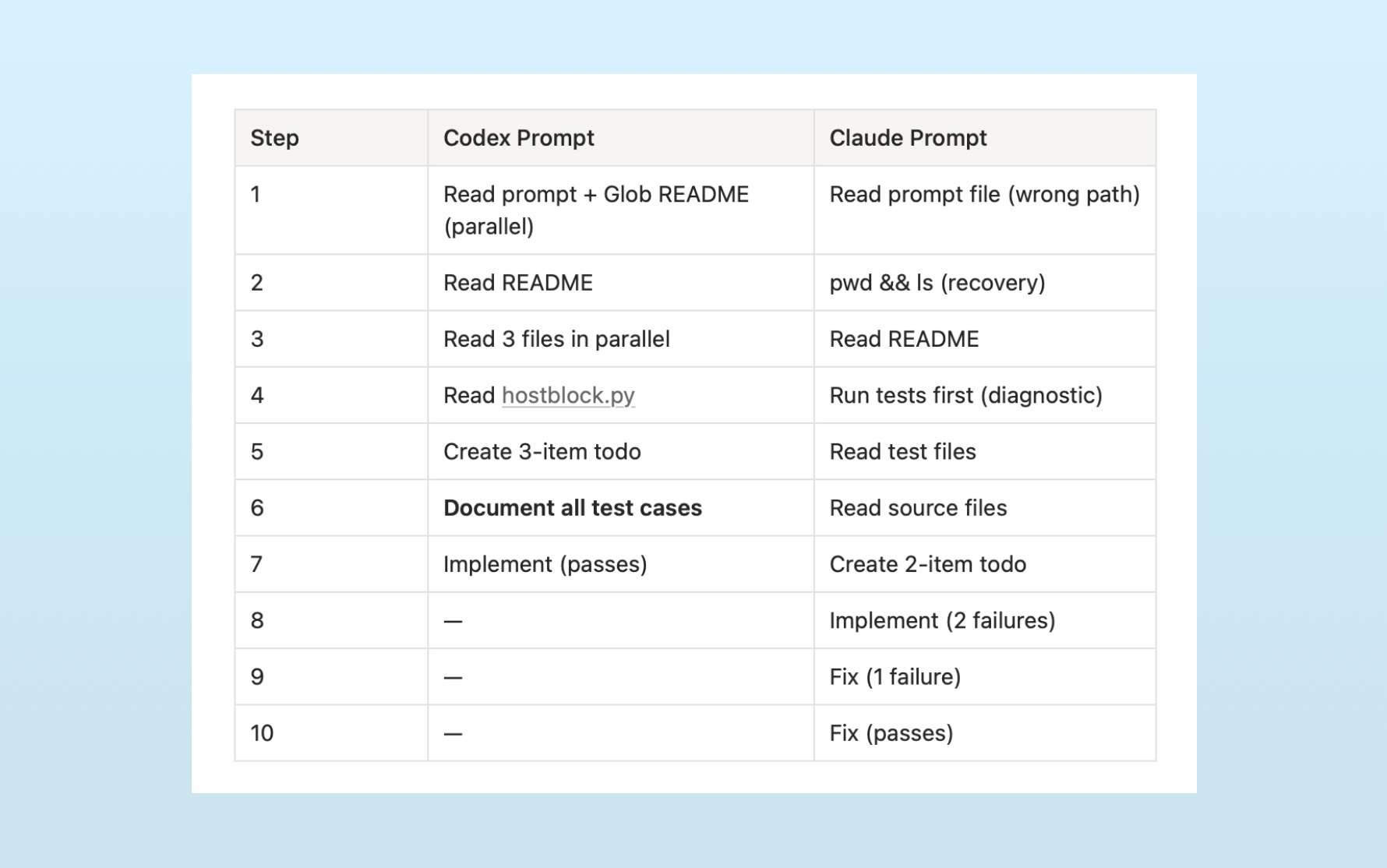
연구팀은 Claude Code 환경에서 Opus 4.5 모델에 두 가지 시스템 프롬프트를 번갈아 적용하는 실험을 했습니다. 하나는 원래 Claude Code 프롬프트, 다른 하나는 Codex 프롬프트였어요.
SWE-Bench Pro 문제를 풀게 했더니 작업 방식이 처음부터 갈렸습니다. Codex 프롬프트를 쓴 에이전트는 문서를 철저히 읽고 이해한 뒤 한 번에 구현했습니다. 반면 Claude 프롬프트를 쓴 에이전트는 일단 뭔가 시도하고, 에러를 보고, 고치는 반복적 접근을 택했죠.
두 에이전트 모두 문제를 정확히 풀었지만, 해결 과정은 완전히 달랐습니다. 같은 뇌(모델)를 쓰는데 다른 성격(시스템 프롬프트)을 가진 셈이에요.
6개 에이전트의 시스템 프롬프트를 비교하면 그 차이가 더 뚜렷합니다. Claude Code와 OpenHands는 프롬프트 길이가 다른 제품의 절반도 안 됩니다. Cursor는 프롬프트의 3분의 1을 “성격과 방향성” 지시에 할애하죠. Kimi CLI는 워크플로 가이드가 거의 없고 가장 짧습니다.
모델만큼 중요한 프롬프트 설계
새로운 AI 모델이 출시될 때마다 사람들은 Opus vs GPT-5.3, Codex vs Gemini 같은 비교에 열중합니다. 하지만 정작 시스템 프롬프트에 대한 논의는 거의 없죠.
이 연구는 시스템 프롬프트가 단순한 설정이 아니라 에이전트의 작동 방식을 정의하는 핵심 요소임을 보여줍니다. 모델이 이론적 성능의 천장을 정한다면, 시스템 프롬프트는 그 천장에 실제로 도달할 수 있는지를 결정하는 셈이에요.
코딩 에이전트를 선택하거나 개발할 때, 어떤 모델을 쓰는지만큼 어떤 시스템 프롬프트를 쓰는지도 중요하다는 뜻입니다. 시스템 프롬프트를 분석하면 그 제품이 어떤 모델의 약점과 싸우고 있는지, 어떤 사용자 경험을 목표로 하는지 알 수 있습니다.
참고자료: How System Prompts Define Agent Behavior – Drew Breunig
답글 남기기