AI 에이전트가 실제로 얼마나 자율적으로 작동하고 있을까요? 실험실 벤치마크가 아닌, 실제 사용 데이터로 이 질문에 답한 연구가 나왔습니다.

Anthropic이 수백만 건의 Claude Code 세션과 공개 API 툴 호출을 분석해 AI 에이전트의 자율성·위험도·사용 패턴을 측정한 연구를 발표했습니다. 에이전트가 얼마나 오래 혼자 작동하는지, 사람은 어떻게 감독하는지, 어떤 분야에서 쓰이는지를 실제 배포 환경에서 측정한 것으로, 이런 규모의 실증 연구는 흔치 않습니다.
출처: Measuring AI agent autonomy in practice – Anthropic
자율 실행 시간이 3개월 만에 2배로
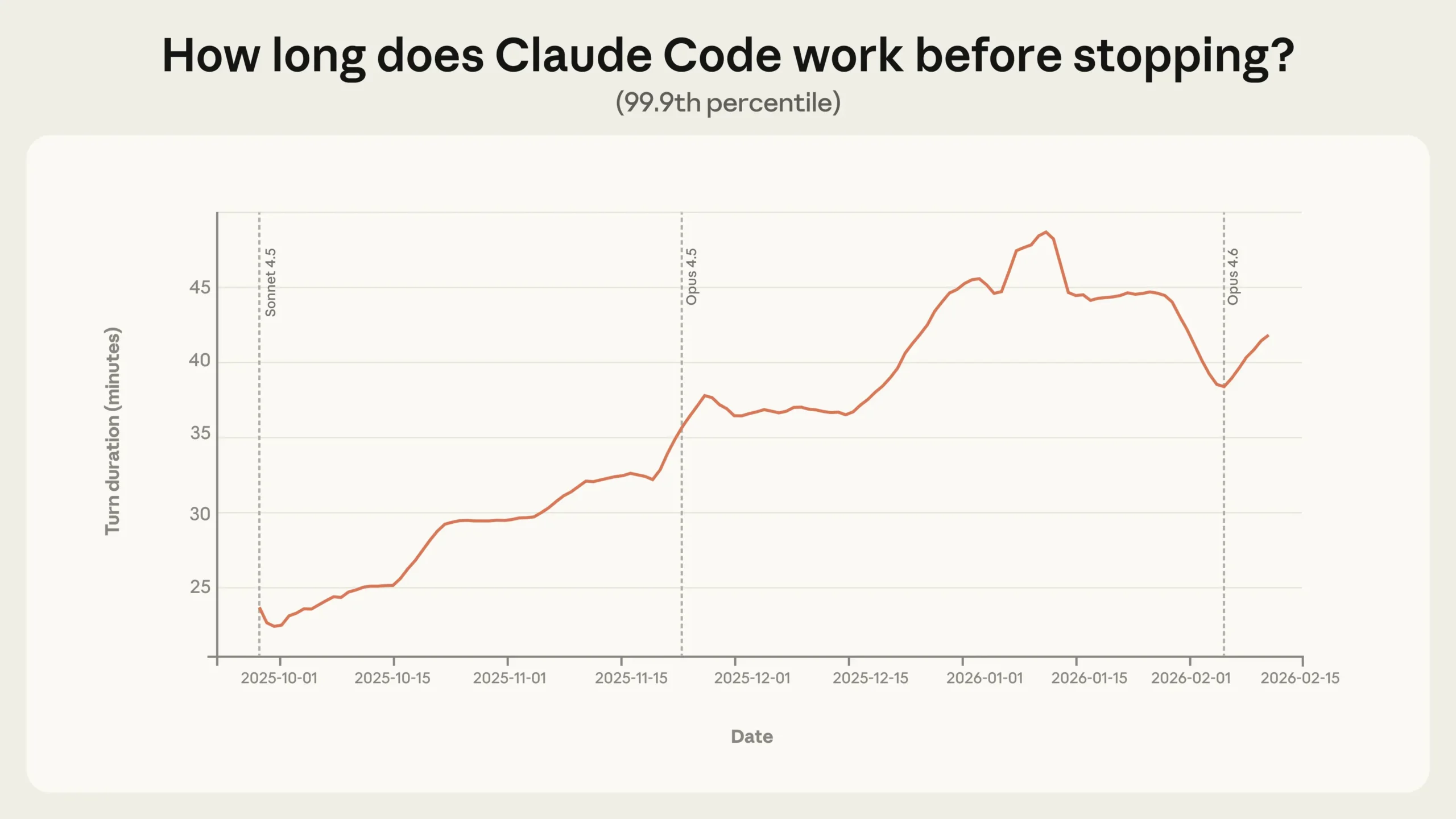
가장 눈에 띄는 수치는 Claude Code의 자율 실행 시간입니다. 2025년 10월부터 2026년 1월 사이, 상위 0.1%(99.9 퍼센타일) 세션의 최대 자율 실행 시간이 25분에서 45분으로 거의 두 배 늘었습니다.
흥미로운 점은 이 증가가 모델 업데이트 시점과 맞물리지 않는다는 겁니다. 새 모델이 출시될 때마다 급격히 뛰는 게 아니라 꾸준히 완만하게 늘었죠. Anthropic은 이를 모델 성능만의 결과가 아니라, 사용자가 점점 더 도구를 신뢰하고 더 야심찬 작업을 맡기면서 나타난 현상으로 봅니다. 반대로 말하면, 현재 모델도 실제로 발휘하는 자율성보다 훨씬 더 많은 자율성을 처리할 능력이 있다는 뜻이기도 합니다.
참고로 중간값(median) 실행 시간은 약 45초로 수개월째 안정적입니다. 극단적인 롱테일에서만 변화가 일어나고 있는 것으로, 대부분의 사용은 여전히 짧고 단순한 작업 중심입니다.
더 믿을수록 더 자주 끊는다는 역설
경험 많은 사용자일수록 Claude를 더 믿고 덜 간섭할 것 같지만, 데이터는 조금 다른 그림을 보여줍니다.
신규 사용자(50세션 미만)는 약 20%의 세션에서 전체 자동 승인(auto-approve)을 사용하고, 750세션 이상의 고경험 사용자는 40% 이상으로 늘어납니다. 그런데 동시에 중간에 작업을 끊는(interrupt) 비율도 경험과 함께 증가합니다. 신규 사용자는 5%의 턴에서 개입하는 반면, 숙련 사용자는 약 9%에서 개입합니다.
모순처럼 보이지만, 이건 감독 방식이 바뀐 것입니다. 초보 사용자는 매 액션을 승인하는 방식으로 통제하고, 숙련 사용자는 Claude가 알아서 달리게 두되 뭔가 잘못됐을 때 빠르게 끊는 방식으로 전환합니다. ‘사전 승인’에서 ‘사후 개입’으로의 전환이죠.
Claude도 스스로 멈춘다
사람만 개입하는 게 아닙니다. Claude Code는 복잡한 작업일수록 스스로 멈추고 사람에게 질문하는 빈도가 높아지는데, 가장 복잡한 작업에서는 Claude가 자발적으로 멈추는 빈도가 사람이 개입하는 빈도보다 2배 이상 높습니다.
Claude가 스스로 멈추는 주요 이유를 보면, 접근 방식 선택을 사용자에게 묻는 경우(35%)가 가장 많고, 진단 정보나 테스트 결과 수집(21%), 모호한 요청 명확화(13%) 등이 뒤를 잇습니다. Anthropic은 이를 단순한 기능이 아닌 안전 속성으로 봅니다. 모델이 자신의 불확실성을 인식하고 적절한 시점에 사람에게 판단을 넘기는 것 자체가 외부 안전장치를 보완하는 역할을 한다는 시각입니다.
위험한 영역도 쓰이지만, 아직은 소규모
공개 API 툴 호출 분석(약 100만 건 샘플)에서는 소프트웨어 엔지니어링이 전체의 약 50%를 차지했습니다. 그 외에는 비즈니스 인텔리전스, 고객 서비스, 금융, 이커머스 등이 각각 몇 퍼센트 수준으로 뒤를 이었습니다.
고위험 영역(의료 기록 접근, 금융 거래, 보안 취약점 탐색)도 등장하지만 아직은 소수입니다. 전체 툴 호출의 80%에는 최소 하나의 안전장치가 있고, 73%는 어떤 형태로든 사람이 루프에 있으며, 비가역적 액션(예: 실제 이메일 발송)은 0.8%에 불과합니다.
실험실 수치와 현실의 간극
METR의 연구는 Claude Opus 4.5가 사람이 약 5시간 걸리는 작업을 50% 성공률로 수행할 수 있다고 추정합니다. 반면 실제 Claude Code의 99.9 퍼센타일 자율 실행 시간은 약 42분입니다.
두 수치는 측정 대상이 다릅니다. METR는 사람 개입 없이 이상적 조건에서 모델이 달성할 수 있는 최대치를, Anthropic의 데이터는 실제 환경에서 사람과 상호작용하며 실제로 실행된 시간을 측정합니다. 모델이 이론적으로 처리할 수 있는 자율성과 실제로 부여받는 자율성 사이에는 아직 큰 간극이 있다는 게 이 연구의 핵심 함의 중 하나입니다.
Anthropic은 이번 연구가 시작점이라고 밝힙니다. 현재 공개 API 요청들을 하나의 에이전트 세션으로 연결하는 방법이 없어 전체 그림을 보기 어렵고, Claude Code라는 단일 제품 데이터에 많이 의존하는 한계도 있습니다. 에이전트가 더 다양한 분야로 확산될수록 이런 모니터링 인프라의 필요성도 커질 것입니다. 위험도와 자율성의 상세한 측정 방법론, 각 도메인별 분석은 원문과 부록 PDF에서 확인할 수 있습니다.
참고자료: [AINews] Anthropic’s Agent Autonomy study – Latent.Space
답글 남기기