AI 활용 가이드
AI 에이전트가 팀원이 될 때, Anthropic이 찾은 협업 원리 4가지
사람과 AI가 같은 팀에서 협업하는 ‘멀티플레이어 에이전트’ 운용법. Anthropic이 사내 실험으로 찾은 4가지 협업 원리를 개인 실무자 관점으로 풀었습니다.
Written by
컨텍스트 윈도우는 200만 토큰까지 커졌는데, AI는 왜 방금 준 정보를 못 쓸까
컨텍스트 윈도우가 200만 토큰까지 커져도 AI가 중간 정보를 놓치는 U-shape 현상과, 양보다 정밀도가 중요한 이유. 개인 실무자가 바로 쓸 수 있는 5가지 컨텍스트 관리 원칙을 정리했습니다.
Written by

잘 만든 AI 프로토타입이 제품이 되지 못하는 이유, ‘프롬프트 부채’
자연어 프롬프트로 만든 AI 프로토타입이 왜 제품으로 자라지 못하는가. Drew Breunig이 짚은 ‘프롬프트 부채’ 개념과, 측정 기반 명세·프롬프트 자동 탐색이라는 대안을 소개합니다.
Written by

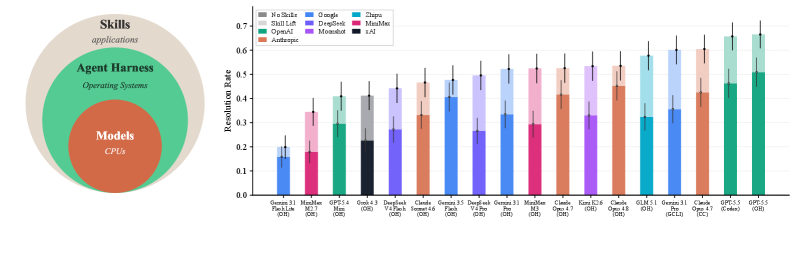
작은 AI 모델이 큰 모델을 따라잡는 방법, Skill 16.6%p의 비밀
잘 만든 Agent Skill은 AI 에이전트 정답률을 16.6%p 높이지만 모든 Skill이 도움되는 건 아닙니다. 87개 과제로 측정한 SkillsBench 연구와 좋은 Skill의 조건을 소개합니다.
Written by
Qwen이 Opus급이라는 말의 진실, 직접 굴려본 창업자의 현실 보고서
1만 5천 달러 GPU로 로컬 Qwen을 1년 넘게 운영한 창업자의 실전 후기. 벤치마크 점수와 실제 신뢰도의 차이, 그리고 로컬 모델이 진짜 빛나는 용도를 짚습니다.
Written by

OpenAI Codex, 프롬프트 대신 시연으로 AI를 가르치는 Record & Replay
OpenAI가 macOS용 Codex에 Record & Replay를 추가했습니다. 작업을 한 번 시연하면 재사용 가능한 스킬로 만들어 반복하는 기능으로, 프롬프트 대신 시연으로 AI를 가르치는 방식을 소개합니다.
Written by

같은 작업에 토큰을 더 쓰는 AI, Copilot이 매 턴 반복 비용을 줄인 방법
GitHub Copilot이 프롬프트 캐싱과 도구 검색, Auto 모델 라우팅으로 매 턴 반복되는 토큰 비용을 줄인 방법. 사용량 기반 과금 시대에 효율의 정의가 어떻게 바뀌는지 짚어봅니다.
Written by
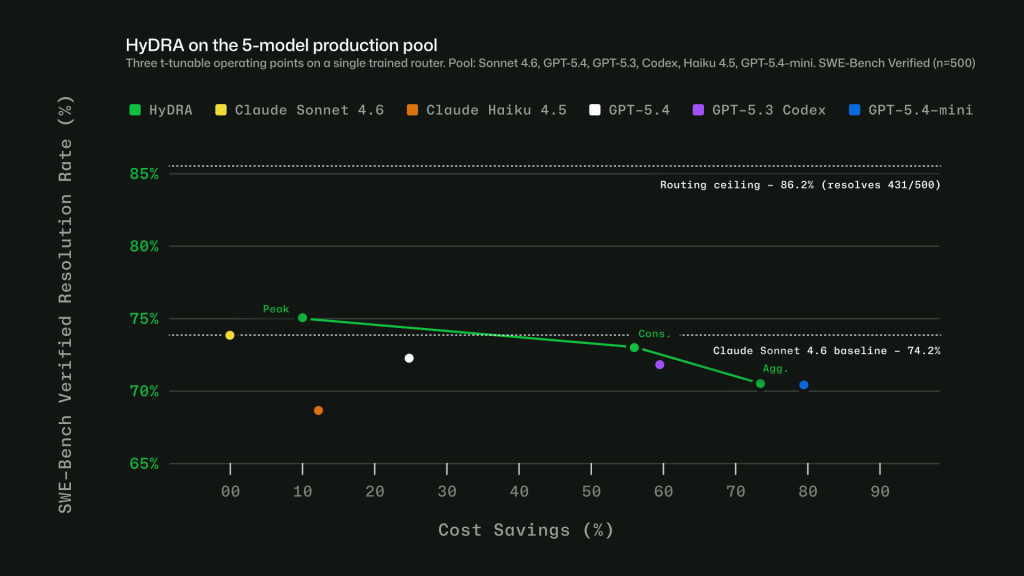
CLAUDE.md에 “항상 이렇게 해”라고 적으면 안 되는 이유, Claude Code 제어 7가지 방법
Claude Code 동작을 제어하는 7가지 방법을 정리한 Anthropic 가이드. CLAUDE.md 지시문과 결정론적 가드레일의 결정적 차이를 짚습니다.
Written by

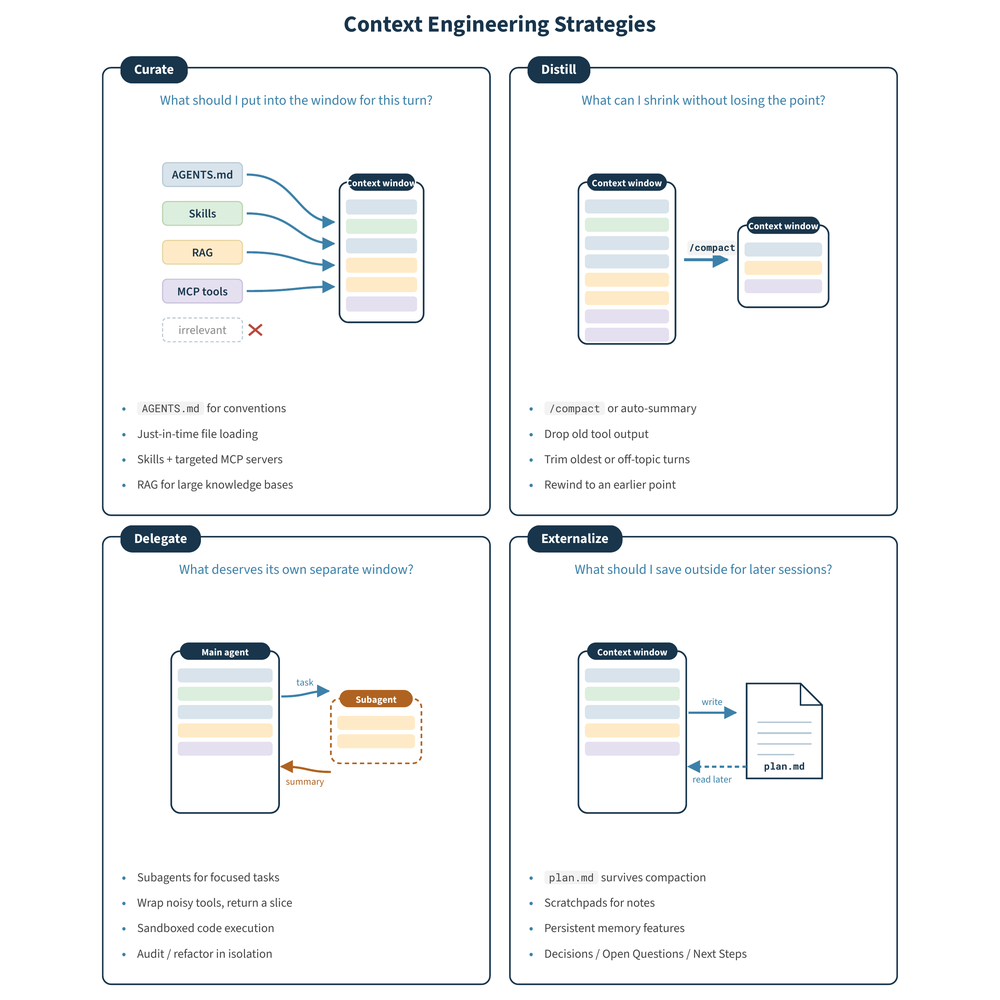
토큰 90% 절감의 함정, 컨텍스트는 줄이는 게 아니라 고르는 것
AI 에이전트의 토큰을 줄이는 두 접근을 비교합니다. 컨텍스트를 직접 선별하는 4가지 전략과, 자동 압축 도구 RTK가 가진 ‘조용한 실패’ 위험을 짚습니다.
Written by
AI 메모리는 RAG로 끝나지 않는다, 검색과 기억은 다른 문제다
“AI 메모리”는 단일 기능이 아니라 RAG·벡터·그래프 등 5개 층위입니다. 검색과 기억의 차이, 그리고 그래프 메모리가 보완하는 상태 관리 문제를 정리합니다.
Written by
