“토큰을 줄이고, 지능은 그대로, 비용은 10분의 1로.” RTK라는 도구가 내건 약속입니다. GitHub 스타 6만 개를 넘겼죠. 그런데 같은 문제를 다룬 한 가이드는 정반대를 말합니다. 컨텍스트는 자동으로 줄이는 게 아니라 직접 골라야 한다고요.

Real Python이 발표한 컨텍스트 엔지니어링 가이드와, 개발자 Przemek Mroczek이 쓴 토큰 압축 도구 RTK 비판 글을 함께 살펴봅니다. 두 글은 “AI 에이전트의 토큰을 어떻게 줄일 것인가”라는 같은 문제를 정반대 각도에서 다룹니다. 한쪽은 무엇을 윈도우에 넣고 뺄지 직접 판단하는 능력을 말하고, 다른 한쪽은 그 판단을 자동 도구에 맡겼을 때의 위험을 경고합니다.
출처:
- Context Engineering for Python Codebases – Real Python
- The Token Compression Illusion: Why I’m Skeptical of RTK – Przemek Mroczek
컨텍스트 윈도우는 한정된 자원이다
AI 코딩 에이전트에게 컨텍스트 윈도우는 한 번의 대화 차례에 모델이 보는 모든 것입니다. 방금 입력한 프롬프트는 그중 마지막 항목 하나일 뿐이죠. 시스템 프롬프트, AGENTS.md 같은 지침 파일, 도구 정의, 열어둔 파일, 검색 결과, 이전 대화 기록까지 전부 같은 공간에서 자리를 다툽니다.
이 공간에는 세 가지 성질이 있습니다. 크기가 고정되어 있어 일정 토큰을 넘기면 모든 정보가 같은 예산을 두고 경쟁합니다. 위치에 민감해서, 윈도우의 처음과 끝에 있는 항목은 주목받지만 한가운데 묻힌 내용은 모델이 잘 보지 못합니다. 그리고 비영속적이라, 세션을 닫으면 디스크에 저장한 것 외에는 대부분 증발합니다.
여기서 글쓴이가 강조하는 핵심이 나옵니다. 에이전트가 헛도는 진짜 이유는 대부분 모델이 나빠서가 아니라 컨텍스트가 나빠서라는 겁니다. “uv를 쓰라”고 얼마 전에 말했는데 지금 pip을 실행하는 경우, 존재하지 않는 함수를 한 번 지어낸 뒤 그걸 사실처럼 계속 호출하는 경우, 비슷한 도구가 열두 개 깔려 있어 엉뚱한 걸 집는 경우. 모두 컨텍스트 관리의 문제지 모델의 문제가 아닙니다.
그리고 한 가지 통념을 정면으로 반박합니다. 윈도우 크기를 키운다고 이 문제가 해결되지는 않는다는 겁니다. 큰 윈도우는 무엇이 중요한지 판단해주지 않습니다. 그저 더 천천히 채워질 뿐, 증상을 미룰 따름이죠.
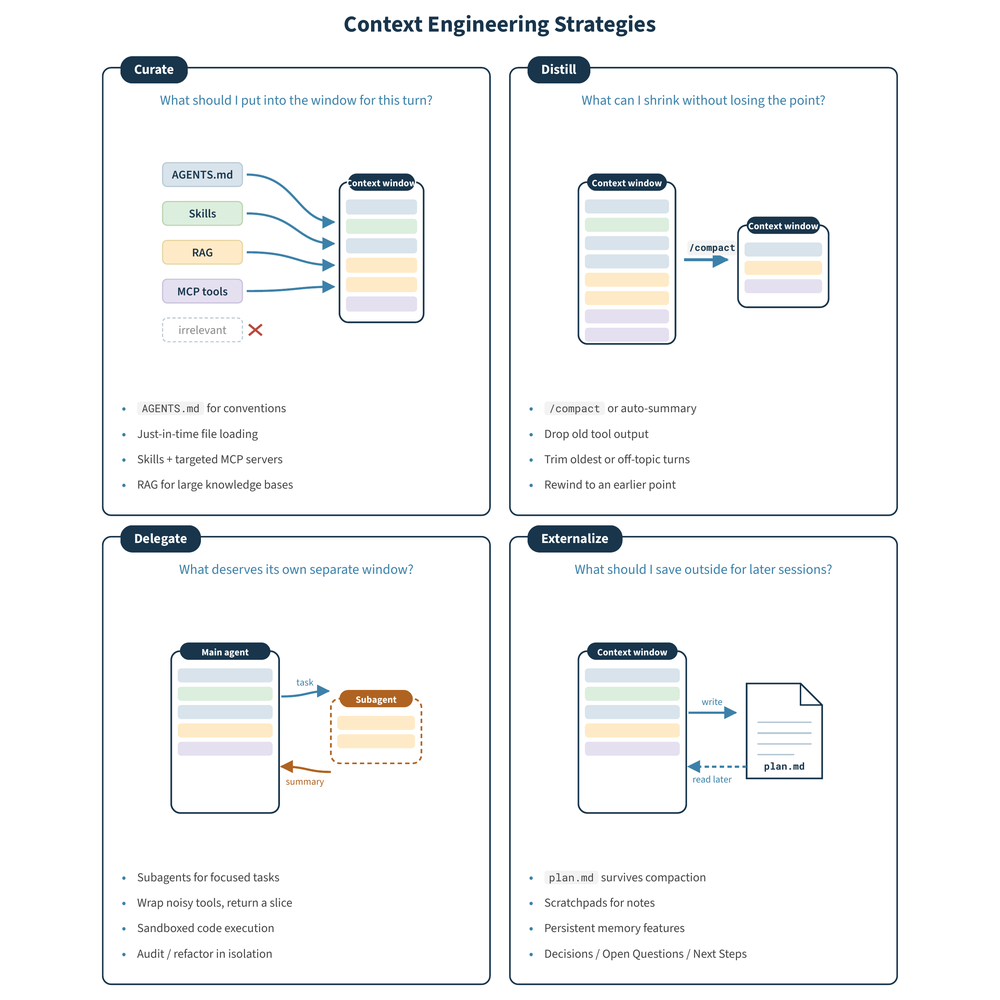
제대로 줄이는 법, 네 가지 전략
그래서 가이드는 컨텍스트를 다루는 작업을 네 개의 질문으로 정리합니다. 각 질문이 하나의 전략에 대응합니다.
- 선별(Curate): 이번 차례에 무엇을 윈도우에 넣을 것인가. 프로젝트 규칙을 담은 짧은 지침 파일을 두고, 필요한 파일만 그때그때 열고, 작업에 필요한 도구만 연결합니다. 모든 MCP 서버를 다 붙이면 도구 목록이 비대해져 오히려 에이전트가 맞는 도구를 못 고릅니다.
- 압축(Distill): 이미 들어 있는 것 중 무엇을 줄일 수 있는가. 긴 대화를 결정 사항 위주로 요약하고, 다시 볼 일 없는 긴 도구 출력을 덜어냅니다.
- 위임(Delegate): 무엇을 별도의 윈도우로 떼어낼 것인가. “인증 흐름을 읽고 요약해줘” 같은 작업을 깨끗한 윈도우를 가진 서브에이전트에게 맡기면, 본체는 500줄의 소스 대신 한 문단만 받습니다.
- 외부화(Externalize): 무엇을 윈도우 바깥에 저장해 나중에 다시 읽게 할 것인가. 계획이나 메모를 디스크의 파일로 남기면 세션을 재시작해도 살아남습니다.
핵심은 토큰 수를 무작정 줄이는 게 아니라, 지금 이 작업에 필요한 것만 윈도우에 채운다는 사고방식입니다. 줄이는 게 목적이 아니라 고르는 게 목적인 셈이죠.
자동 압축의 함정, RTK가 보여주는 조용한 실패
그렇다면 이 “줄이기”를 자동 도구에 맡기면 어떨까요. 바로 이 지점에서 RTK 비판 글이 날카로운 반례를 던집니다.
먼저 그 유명한 “60~90% 절감” 수치부터가 오해를 부른다는 지적입니다. 이 숫자는 실제 API 청구서가 90% 줄었다는 뜻이 아니라, 터미널 출력에서 걷어낸 글자의 비율일 뿐입니다. RTK는 Bash 출력만 건드릴 뿐, 정작 비용을 크게 잡아먹는 깊은 파일 읽기나 저장소 컨텍스트, 모델의 내부 추론 토큰은 그대로 둡니다. 화면 캡처용으로는 화려하지만 실제 청구서와는 다른 숫자라는 겁니다.
더 무거운 문제는 글쓴이가 “조용한 실패(silent failure)”라고 부르는 위험입니다. 압축 과정에서 터미널 출력이 조용히 뭉개지거나 누락되는데, 정작 AI 에이전트는 텍스트가 압축됐다는 사실 자체를 모른다는 점이 핵심입니다. RTK가 토큰 몇 개 아끼려고 스택 트레이스의 중요한 한 줄을 잘라내면, 사람도 모델도 아무것도 모르는 채로 작동합니다. 명시적 오류조차 나지 않으니 더 위험하죠.
그리고 결정적으로 빠진 게 하나 있습니다. 토큰을 얼마나 아꼈는지 보여주는 그래프는 넘치지만, 정작 중요한 지표인 작업 성공률은 없다는 겁니다. 프롬프트에서 80%를 절약해도 잘려나간 맥락 때문에 에이전트가 헛것을 만들거나 빌드에 실패하거나 같은 자리를 맴돌면, 결국 더 많은 토큰을 태우게 됩니다. 절약이 오히려 손해가 되는 거죠.
줄이는 것과 고르는 것의 차이
두 글을 나란히 놓으면 하나의 구분선이 또렷해집니다. 토큰을 줄이는 것과 컨텍스트를 잘 관리하는 것은 다른 일이라는 것입니다.
RTK가 하는 일은 결과물(터미널 출력)을 사후에 기계적으로 깎아내는 압축입니다. 에이전트는 무엇이 사라졌는지 모릅니다. 반면 컨텍스트 엔지니어링이 말하는 건, 애초에 무엇을 넣고 뺄지를 사람이 의도를 갖고 결정하는 일입니다. 무엇을 잘라냈는지 본인이 알고 있다는 점에서 둘은 근본적으로 다릅니다.
결국 목적은 토큰 절감 자체가 아니라, 에이전트가 올바른 정보를 보게 만드는 데 있습니다. 숫자를 줄이는 데 집중하면 RTK의 화려한 절감률에 끌리지만, 에이전트의 시야를 관리하는 데 집중하면 무엇을 남길지가 더 중요해집니다. 두 원문 모두 같은 결론을 가리킵니다. 컨텍스트는 줄이는 게 아니라 고르는 것입니다.
답글 남기기