AI 코딩 에이전트가 엉뚱한 결과를 낼 때마다 규칙을 하나씩 추가합니다. 그런데 규칙이 20개, 30개로 불어나자 에이전트가 오히려 아무것도 하지 않기 시작합니다. 규칙끼리 충돌하니 매번 확인을 요청하고, 창의적인 해결은 시도조차 않죠.

Unwind AI의 Shubham Saboo가 AI 에이전트의 컨텍스트 엔지니어링에 대한 글 두 편을 발표했습니다. 규칙을 구조화하는 방법과 에이전트에게 효과적으로 말하는 법을 다루는데, 핵심은 같습니다. 규칙의 양이 아니라 질과 구조가 에이전트 성능을 결정한다는 것이죠.
출처:
- Why Your Agent Rules Are Making It Dumber (And How to Fix It) – unwind ai
- Talking to AI Agents is All You Need – unwind ai
대화가 길어질수록 LLM은 길을 잃는다
이 문제는 직관만이 아니라 연구로도 뒷받침됩니다. Microsoft Research와 Salesforce의 공동 연구(“LLMs Get Lost In Multi-Turn Conversation”)는 o3, GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet 등 15개 모델을 대상으로 멀티턴 태스크 성능을 측정했습니다. 결과는 명확했어요. 같은 정보를 한 번에 주었을 때와 여러 턴에 걸쳐 나눠 주었을 때, 평균 39%의 성능 저하가 발생했습니다.
원인은 “능력 부족”이 아니었습니다. 모델의 실력 자체는 16%만 떨어졌지만, 신뢰성(일관된 결과를 내는 정도)이 112% 악화됐어요. 초반 턴에서 성급하게 가정을 세우고 잘못된 방향으로 가면, 이후 턴에서 회복하지 못하는 패턴이 반복됐습니다. 연구팀은 이를 “대화에서 길을 잃는다(lost in conversation)”고 표현했습니다.
에이전트에 규칙을 잔뜩 쌓는 것은 이 문제를 악화시킵니다. 규칙이 많아지면 중요한 지시가 주의(attention) 속에 묻히고, 규칙끼리 충돌하면 모델이 어느 쪽을 따를지 판단하지 못해 멈춰 서죠.
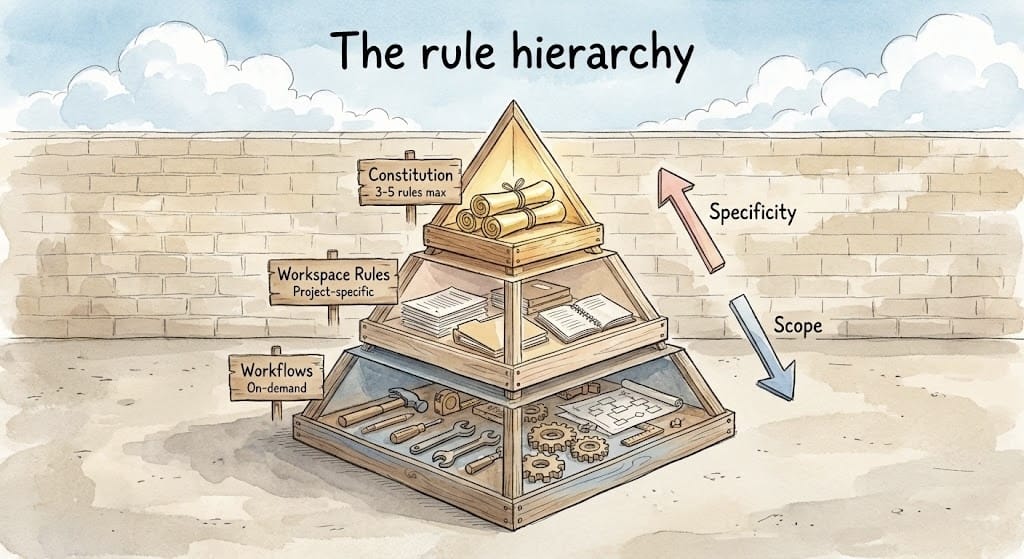
규칙은 리스트가 아니라 피라미드
해법은 규칙을 평면적 리스트가 아니라 3단 피라미드로 구조화하는 것입니다.
1층: 헌법(Constitution) — 최대 3~5개의 절대 규칙입니다. “비밀 정보를 로그에 남기지 않는다”, “모든 코드는 타입 체크를 통과한다” 같은 것들이죠. 모든 상황에 예외 없이 적용됩니다. 여기서 핵심은 “모든 것이 중요하면 아무것도 중요하지 않다”는 원칙이에요.
2층: 워크스페이스 규칙 — 특정 프로젝트나 리포지토리에 해당하는 맥락입니다. “이 프로젝트는 pytest를 사용한다”, “컴포넌트는 src/components/에 배치한다” 같은 것들이요. 1층을 절대 덮어쓰지 않지만, 해당 작업 공간에서는 항상 적용됩니다.
3층: 워크플로(Workflows) — 상시 규칙이 아니라 필요할 때만 호출하는 액션입니다. “테스트 작성”을 항상 켜둔 규칙으로 만들면, 아직 기능을 만드는 중인데 에이전트가 테스트를 먼저 쓰려고 합니다. 기능이 완성된 뒤에 호출하는 워크플로로 분리하면 이 문제가 사라지죠. 린팅, 문서 업데이트, 보안 점검도 마찬가지입니다.
규칙이 충돌하면 누가 이기나
구조만으로는 부족합니다. 1층 규칙이 “항상 TypeScript를 사용하라”고 하고, 2층 규칙이 “기존 파일의 언어를 따르라”고 했는데 파일이 JavaScript라면? 에이전트는 멈춥니다.
저자는 시스템 프롬프트에 우선순위 조항(priority clause)을 명시하라고 제안합니다. “현재 사용자 요청 > 워크스페이스 규칙 > 글로벌 규칙” 순서로 따르라는 것이죠. 이렇게 하면 두 가지가 해결됩니다. 첫째, 모호함이 사라집니다. 둘째, 에이전트가 상황에 따라 규칙을 유연하게 적용할 수 있는 “허가”를 받게 됩니다.
저자의 실제 사례가 이를 잘 보여줍니다. 100개 이상의 AI 에이전트 구현이 담긴 오픈소스 리포지토리에서, 글로벌 규칙은 “관심사 분리 원칙에 따라 파일을 나눠라”고 하고 워크스페이스 규칙은 “모든 에이전트를 단일 파일로 작성하라”고 했습니다. 우선순위 조항 없이는 에이전트가 4개 파일로 나눠 쓰는 정석적 아키텍처를 만들었지만, 이 리포의 목적 — 개발자가 하나의 파일만 읽고 10분 안에 전체 흐름을 이해하는 것 — 과는 맞지 않았어요. 우선순위 조항을 추가하자 같은 모델이 같은 요청에 단일 파일로 결과를 냈습니다.
한 가지 더. “스파게티 코드를 쓰지 마라” 같은 부정형 제약은 방향을 주지 않으면서 주의만 소모합니다. “관련 로직을 전용 모듈로 분리하라”는 긍정형으로 바꾸면 에이전트가 구체적으로 무엇을 해야 하는지 알 수 있죠.
구조 설계 전에 ‘왜’부터 말하기
규칙 구조를 아무리 잘 짜도, 에이전트에게 전달하는 의도 자체가 모호하면 소용없습니다. 저자는 두 번째 글에서 이 점을 강조합니다. “대시보드를 만들어줘”는 what이고, “우리 유저가 매일 500개 피드백에서 트렌드를 못 찾고 있어”는 why입니다. why를 먼저 전달하면 에이전트가 이후 모든 결정에서 맥락을 갖게 됩니다.
또 하나 효과적인 습관은 “다시 쓰지 말고 반응하라”는 것입니다. 결과가 마음에 안 들면 프롬프트를 처음부터 새로 쓰는 대신, “톤이 너무 딱딱해”, “데이터가 없는 경우를 빠뜨렸어” 같이 구체적으로 반응하는 게 낫습니다. 이미 쌓인 대화 컨텍스트를 버리지 않으면서 방향만 조정하는 거죠. 멀티턴 성능 저하 연구를 고려하면, 불필요하게 턴을 늘리지 않는 이 방식이 더 합리적이기도 합니다.
규칙 파일은 소스 코드다
결국 컨텍스트 엔지니어링은 프롬프트 기법이 아니라 환경 설계에 가깝습니다. .cursorrules, CLAUDE.md, AGENTS.md 같은 규칙 파일을 코드처럼 관리하라는 게 저자의 제안입니다. 월간 감사로 여전히 유효한 규칙만 남기고, 10번 이상의 세션에서 쓰이지 않은 규칙은 삭제하고, 버전 관리로 변경 이력을 추적하는 것이죠.
원문은 이 밖에도 규칙과 프롬프트의 구분 기준(“합리적인 예외 상황이 있는가?” 테스트), 실전 코드 예시 등을 더 자세히 다루고 있습니다.
참고자료: LLMs Get Lost In Multi-Turn Conversation – Microsoft Research & Salesforce Research (arXiv, 2025)
답글 남기기