“더 나은 AI 에이전트를 만들려면 더 좋은 모델로 바꾸면 된다.” 많은 개발자들이 이렇게 생각합니다. 그런데 LangChain 창업자 Harrison Chase는 이 관점이 근본적으로 좁다고 말합니다.

LangChain 공식 블로그에 Harrison Chase가 올린 글은 AI 에이전트의 “지속 학습(continual learning)”을 세 개의 레이어로 나눠 설명합니다. 모델뿐만 아니라 에이전트를 구동하는 코드 구조와 메모리도 시간이 지나면서 스스로 개선될 수 있다는 프레임워크입니다.
출처: Continual learning for AI agents – LangChain Blog
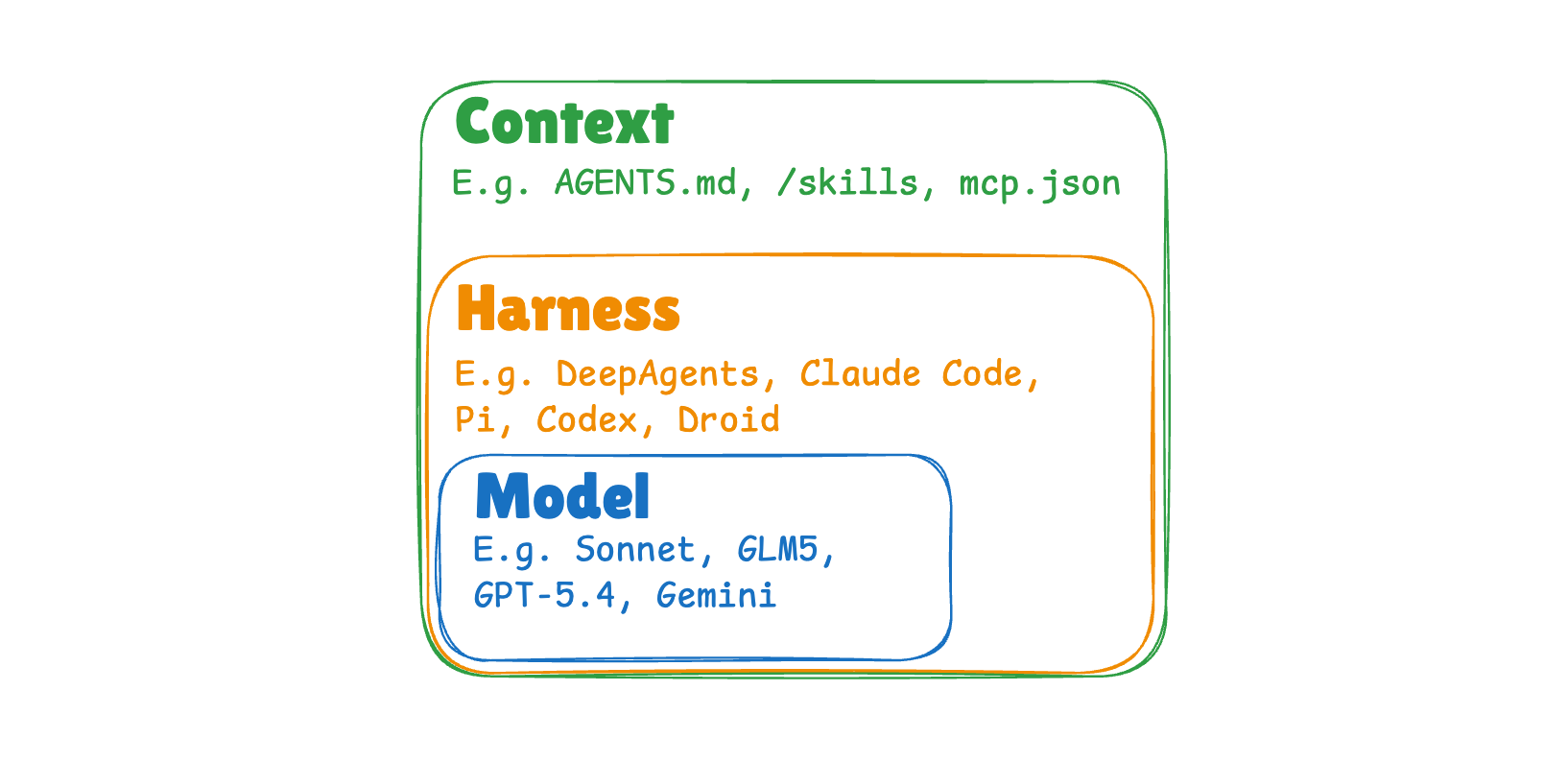
에이전트 시스템의 세 레이어
글에서는 모든 에이전트 시스템을 세 가지 구성 요소로 나눕니다.
- 모델(Model): 실제 추론을 담당하는 LLM 가중치
- 하네스(Harness): 에이전트를 구동하는 코드, 항상 적용되는 프롬프트와 툴
- 컨텍스트(Context): 하네스 바깥에 존재하며 인스턴스별로 설정을 바꾸는 지시사항과 메모리
Claude Code를 예로 들면, 모델은 claude-sonnet이고, 하네스는 Claude Code 자체이며, 컨텍스트는 사용자가 작성하는 CLAUDE.md와 /skills 파일들입니다. 지속 학습은 이 세 레이어 각각에서 다른 방식으로 일어납니다.
모델 레이어: 느리고 비싸지만 근본적
모델 가중치를 직접 업데이트하는 방식입니다. SFT나 RL 같은 기법이 여기에 해당합니다. 가장 직관적이지만 치명적인 문제가 있습니다. 새로운 데이터로 학습하면 이전에 잘하던 것을 잊어버리는 “파국적 망각(catastrophic forgetting)” 현상입니다. 아직까지 완전히 해결된 연구 문제가 아닙니다.
모델 업데이트는 대개 에이전트 전체 수준에서 이뤄집니다. 이론적으로는 사용자별로 별도의 LoRA를 갖는 구조도 가능하지만, 실제로 이렇게 운영하는 사례는 드뭅니다.
하네스 레이어: 코드 자체가 스스로 개선된다
하네스 학습의 핵심 아이디어는 에이전트 실행 로그(트레이스)를 쌓고, 다른 코딩 에이전트가 그 로그를 분석해 하네스 코드를 수정하도록 하는 것입니다.
최근 발표된 Meta-Harness 논문이 이 방식을 정식화했습니다.
- 에이전트를 다양한 태스크에 실행
- 결과를 평가하고 로그를 파일시스템에 저장
- 코딩 에이전트가 로그를 분석해 하네스 코드 수정 제안
- 변경 사항 반영 후 다시 실행
코드 구조 자체가 반복 실행을 통해 점진적으로 최적화되는 구조입니다.
컨텍스트 레이어: 가장 유연한 학습 방식
컨텍스트 학습은 모델도, 코드도 바꾸지 않고 에이전트에 주입되는 지시사항과 메모리를 업데이트하는 방식입니다. 이 방식의 장점은 적용 단위를 유연하게 설정할 수 있다는 점입니다.
- 에이전트 레벨: 에이전트 자체가 하나의 지속적 메모리를 가짐 (OpenClaw의 SOUL.md가 대표적 예)
- 사용자/조직 레벨: 사람마다 다른 컨텍스트를 갖고 개인화가 누적됨
업데이트 타이밍도 두 가지입니다. 오프라인으로 최근 로그를 배치 분석해 인사이트를 추출하는 방식(OpenClaw가 “dreaming”이라고 부르는 방식)과, 에이전트가 작업 중 실시간으로 메모리를 기록하는 방식입니다.
세 레이어를 동시에 조합하는 것도 가능합니다. 에이전트 레벨 컨텍스트, 사용자 레벨 컨텍스트, 조직 레벨 컨텍스트가 함께 작동하는 구조입니다.
트레이스가 모든 학습의 연료
세 레이어의 학습에 공통으로 필요한 것은 에이전트의 실행 기록, 즉 트레이스입니다. 어떤 레이어를 개선하든 “무슨 일이 일어났는가”를 정확히 기록해야 분석이 가능하기 때문입니다.
이 프레임워크가 흥미로운 이유는 학습을 “더 좋은 모델”의 문제로만 보지 않는다는 데 있습니다. 같은 모델을 쓰더라도 하네스나 컨텍스트를 꾸준히 개선하면 에이전트 성능이 실질적으로 올라갈 수 있다는 것입니다. 특히 컨텍스트 레이어는 모델 업데이트보다 훨씬 가볍고 빠르게 적용할 수 있어, 실제 서비스 운영 환경에서 가장 현실적인 선택지가 될 수 있습니다.
세 레이어 간 트레이드오프 비교와 구체적 구현 사례는 원문에서 확인할 수 있습니다.
참고자료: Meta-Harness: End-to-End Optimization of Model Harnesses – arXiv (Yoonho Lee et al., 2026)
답글 남기기