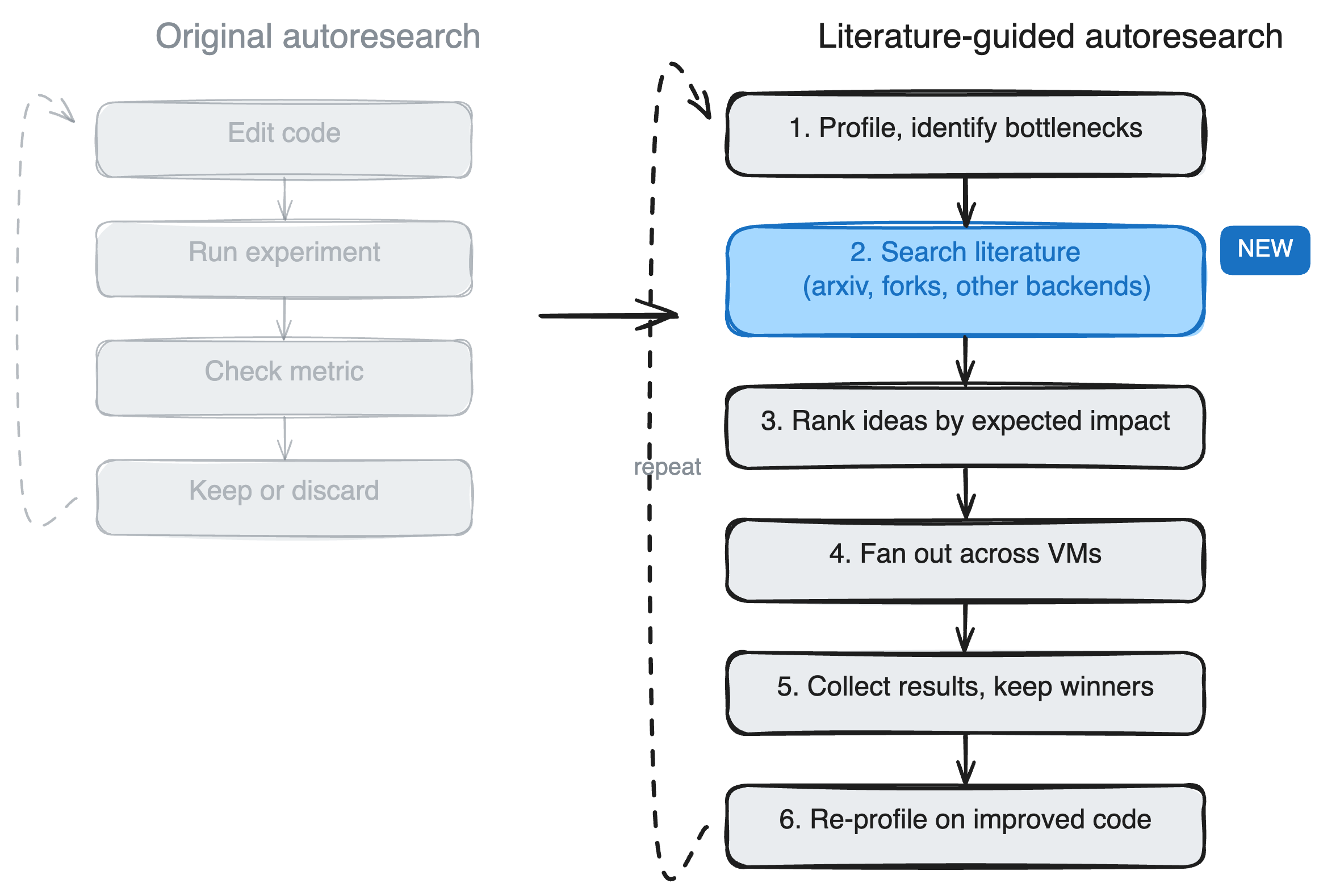
코딩 에이전트는 코드를 읽고 실험을 돌리고 개선안을 제시합니다. 그런데 코드에서 보이지 않는 이유로 느린 문제라면, 에이전트가 아무리 코드를 들여다봐도 좋은 가설이 나오지 않습니다.

SkyPilot 팀이 코딩 에이전트의 최적화 성능을 끌어올리는 실험을 진행했습니다. 에이전트가 코드 수정에 앞서 논문과 경쟁 프로젝트를 먼저 읽도록 한 결과, llama.cpp CPU 추론 속도를 x86 기준 15%, ARM 기준 5% 끌어올리는 데 성공했습니다.
출처: Research-Driven Agents: What Happens When Your Agent Reads Before It Codes – SkyPilot Blog
코드만 보면 왜 얕은 가설이 나올까
SkyPilot 팀은 Claude Code 에이전트에 AWS VM 4대를 붙여 llama.cpp의 CPU 추론 경로를 최적화하는 실험을 설계했습니다. 처음엔 에이전트가 코드 컨텍스트만 보고 가설을 세우도록 했는데, 결과는 신통치 않았습니다.
에이전트가 1라운드에서 시도한 것들은 전형적인 SIMD 미세 최적화였습니다. AVX2 프리페치, 루프 언롤링, 임시 버퍼 제거 같은 것들인데, 개선 효과는 거의 없거나 오히려 성능이 떨어졌습니다. 이유는 단순했습니다. 에이전트 스스로 내린 사후 진단이 정확했습니다.
“Wave 1 결과를 보니, 텍스트 생성은 컴퓨팅이 아니라 메모리 대역폭이 병목입니다. 컴퓨팅 경로를 아무리 미세 최적화해도 효과가 미미합니다.”
600MB 모델을 초당 49토큰으로 처리하려면 초당 ~30GB의 메모리 대역폭이 필요한데, 이는 해당 EC2 인스턴스의 DRAM 한계에 근접한 수치입니다. SIMD를 아무리 최적화해도 CPU가 DRAM에서 가중치를 불러오느라 멈춰 있으면 소용이 없습니다. 하지만 이 사실은 코드 어디에도 적혀 있지 않습니다. 하드웨어 메모리 대역폭, 루프라인 모델, 배치 크기 1 추론의 특성을 알아야 비로소 보이는 것입니다.
논문과 경쟁 프로젝트를 읽은 에이전트
연구팀은 실험 루프에 ‘리서치 단계’를 추가했습니다. 코드 수정 전, 에이전트가 관련 논문과 경쟁 프로젝트를 직접 탐색하도록 한 것입니다.
에이전트는 두 방향으로 병렬 리서치를 진행했습니다.
- 경쟁 프로젝트 분석: ik_llama.cpp(성능 중심 포크), llamafile의 tinyBLAS, PowerInfer, ExLlamaV2
- 논문 탐색: FlashAttention, Blockbuster(블록 수준 연산 융합), Intel의 캐시 인식 스레드 파티셔닝 논문 등
여기서 흥미로운 점이 있습니다. 논문보다 경쟁 프로젝트 분석이 더 유용했다는 것입니다. 특히 CUDA와 Metal 백엔드를 살펴보던 에이전트가 이런 사실을 발견합니다.
“RMS norm + MUL 융합이 CPU 백엔드에는 없는데, CUDA에는 있습니다.”
같은 연산을 CUDA 백엔드는 하나로 묶어 처리하는데 CPU 백엔드는 따로 돌리고 있었던 겁니다. 코드만 봤다면 절대 나오지 않을 가설입니다. CPU 코드만 봐서는 두 단계로 나뉜 처리 방식이 이상해 보이지 않으니까요.
리서치가 이끌어낸 5가지 최적화
30회 이상의 실험 중 최종적으로 5개 최적화가 살아남았습니다. 핵심은 모두 같습니다. 메모리 패스를 줄이는 것, 즉 같은 데이터를 여러 번 읽는 대신 한 번에 처리하는 것입니다.
대표적인 두 가지를 보면:
소프트맥스 융합: 기존 코드는 복사 → 스케일링 → 마스크 추가를 3번의 별도 패스로 처리했습니다. 에이전트는 이를 한 번의 루프로 합쳤습니다.
플래시 어텐션 KQ 융합: 타일드 플래시 어텐션 경로에서 스케일링, 패딩, 마스크 추가, 최댓값 탐색을 4번에 걸쳐 하던 것을 AVX2 FMA 명령어로 단일 패스에 처리했습니다.
최종 결과는 다음과 같습니다.
| 아키텍처 | 프롬프트 처리 | 텍스트 생성 |
|---|---|---|
| x86 (Intel Xeon) | +1.2% | +15.1% |
| ARM (Graviton3) | +1.9% | +5.0% |
텍스트 생성 단계에서 개선 폭이 큰 이유는 이 단계에서 어텐션 연산이 차지하는 비율이 더 크기 때문입니다. 흥미로운 부가 효과도 있었습니다. 기준 모델의 텍스트 생성 속도 분산은 ±19 t/s였는데, 최적화 후 ±0.59 t/s로 줄었습니다. 중간 쓰기 연산이 사라지면서 메모리 접근 패턴이 더 예측 가능해진 덕분입니다.
비용은 VM 비용 $20, API 비용 $9, 총 약 3시간이 걸렸습니다.
왜 이게 중요한가
이 실험이 보여주는 건 단순히 “에이전트에게 논문을 읽혀라”는 팁이 아닙니다. 에이전트가 생성하는 가설의 품질은 주어진 컨텍스트의 품질에 직접 의존한다는 것입니다.
코드만 보면 “이 루프를 더 빠르게”라는 가설이 나옵니다. 논문과 다른 구현체를 보면 “이 연산들을 합칠 수 있지 않을까”라는 질문이 나옵니다. 시니어 엔지니어가 낯선 코드베이스를 최적화하기 전 먼저 레퍼런스를 찾아보는 것처럼, 에이전트도 같은 준비 과정이 필요하다는 뜻이죠.
SkyPilot 팀은 이 설정을 벤치마크와 테스트 스위트가 있는 어떤 프로젝트에도 적용할 수 있다고 밝히고 있습니다. 실험에 사용된 전체 설정은 원문에서 확인할 수 있습니다.
답글 남기기