이메일을 대신 관리해주는 AI 에이전트를 상상해보세요. 받은 편지함을 읽고, 중요한 메일을 요약하고, 필요하면 답장까지 보내주죠. 편리하지만 위험합니다. 악의적인 발신자가 이메일에 특수한 명령어를 숨겨놓으면 AI 에이전트를 조종해 개인 정보를 빼내거나 지인들에게 피싱 메일을 보낼 수 있거든요. 이게 바로 프롬프트 인젝션 공격입니다.

AI 보안 전문가 Simon Willison이 프롬프트 인젝션에 관한 최신 연구 2편을 분석한 글을 발표했습니다. Meta가 제안한 실용적 보안 프레임워크 “Agents Rule of Two”와, OpenAI·Anthropic·Google DeepMind 연구진이 공동 작성한 “The Attacker Moves Second” 논문이 핵심입니다. 두 연구 모두 같은 결론에 도달했죠. 프롬프트 인젝션은 아직 막을 방법이 없다는 것.
출처: New prompt injection papers: Agents Rule of Two and The Attacker Moves Second – Simon Willison’s Weblog
방어 시스템 12개 중 대부분이 뚫렸다
“The Attacker Moves Second” 논문은 충격적인 실험 결과를 담고 있습니다. 연구팀은 최근 발표된 프롬프트 인젝션 방어 시스템 12개를 적응형 공격으로 테스트했어요. 적응형 공격이란 한 번의 시도로 끝나는 게 아니라, 여러 번 반복하며 방어를 뚫을 방법을 찾아내는 공격 방식입니다.
결과는 참담했습니다. 대부분의 방어 시스템이 90% 이상의 공격 성공률을 기록했죠. 특히 인간 레드팀 테스트에서는 12개 시스템 모두 100% 뚫렸습니다. 연구팀은 500명의 참가자에게 2만 달러 상금을 걸고 온라인 경진대회를 열었는데, 참가자들은 모든 방어책을 우회하는 데 성공했어요.
더 심각한 건 이 방어 시스템들이 원래 논문에서 “거의 뚫리지 않는다”고 보고했다는 점입니다. RPO, Circuit Breaker, PIGuard, Model Armor 등은 정적 공격에서 0% 성공률을 자랑했지만, 적응형 공격 앞에서는 80~100%가 뚫렸죠. 이는 기존 평가 방식이 얼마나 허술했는지 보여줍니다.
연구팀은 세 가지 적응형 공격 기법을 사용했습니다. 첫 번째는 그래디언트 기반 방법으로, 2023년 발표된 “Universal and Transferable Adversarial Attacks” 논문의 기법을 활용했어요. 두 번째는 강화학습 방법인데, 시스템과 직접 상호작용하며 5라운드씩 32번의 세션을 거쳐 공격법을 학습했습니다. 블랙박스 모델에 특히 효과적이었죠. 세 번째는 검색 기반 방법으로, LLM이 공격 후보를 만들고 스스로 평가하며 개선하는 방식입니다.
Meta의 Rule of Two: 3가지 중 2개만 선택하라
프롬프트 인젝션을 막을 수 없다면 어떻게 해야 할까요? Meta는 시스템 설계로 위험을 줄이자고 제안합니다. “Agents Rule of Two”는 Google Chrome 팀의 보안 원칙과 Simon Willison의 “lethal trifecta” 개념에서 영감을 받았어요.
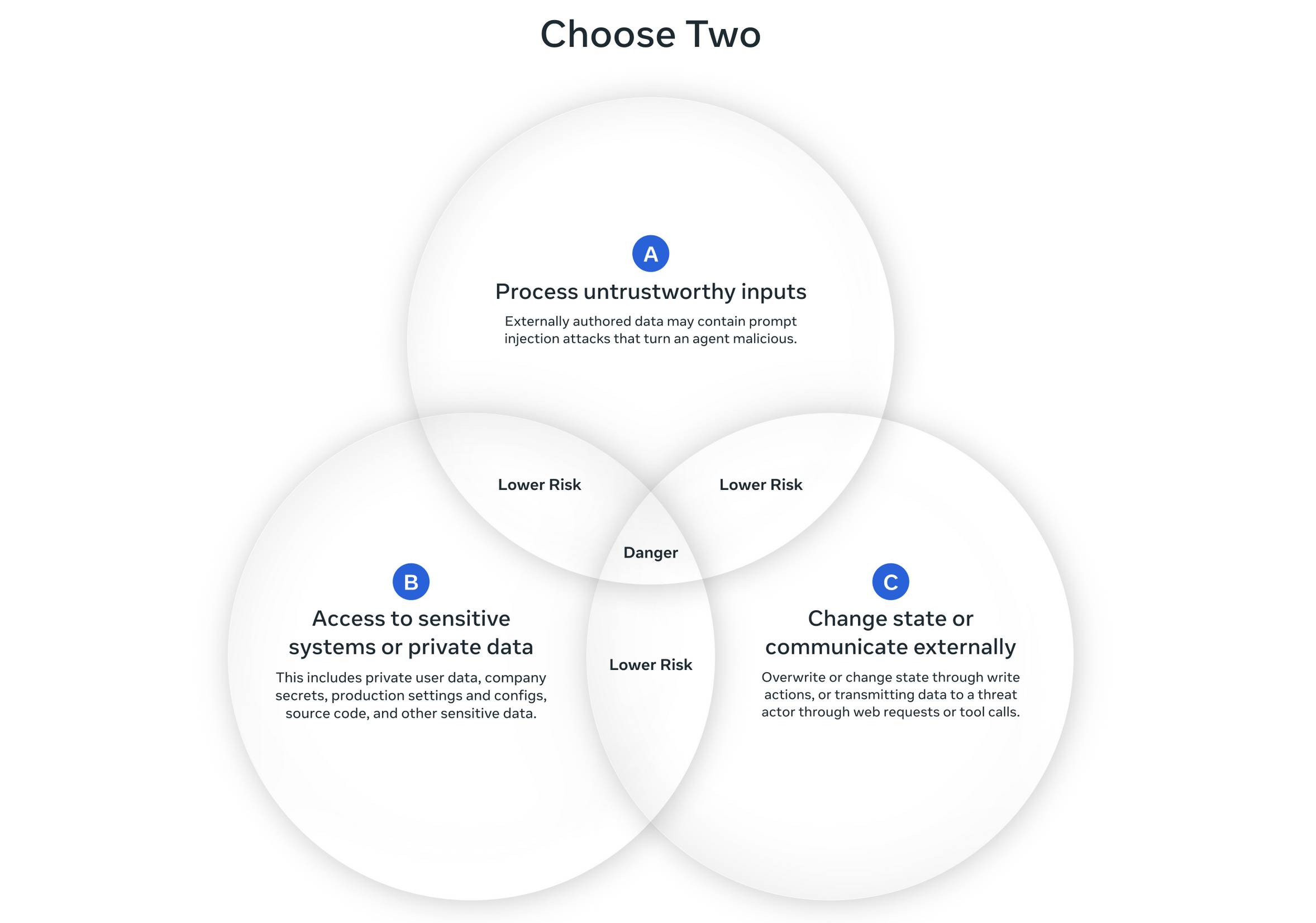
핵심은 간단합니다. AI 에이전트가 다음 세 가지 속성 중 동시에 2개까지만 가지도록 설계하라는 거죠:
[A] 신뢰할 수 없는 입력 처리: 외부에서 작성된 데이터를 읽고 처리하는 능력. 이메일, 웹 콘텐츠, 사용자가 업로드한 파일 등이 여기 해당합니다.
[B] 민감한 시스템이나 개인정보 접근: 개인 데이터, 회사 기밀, 프로덕션 설정, 소스 코드 같은 중요한 정보에 접근할 수 있는 권한입니다.
[C] 상태 변경이나 외부 통신: 데이터를 수정하거나 웹 요청을 보내는 등 실제로 뭔가를 실행할 수 있는 능력이죠.
예를 들어볼까요? 이메일 봇이 받은 편지함을 읽고(A), 답장을 보낼 수 있다면(C), 개인 이메일 기록에는 접근하면 안 됩니다(B 제외). 혹은 고객 데이터베이스에 접근해서(B) 정보를 수정할 수 있다면(C), 외부 입력은 처리하지 말아야 해요(A 제외). 만약 세 가지 모두 필요한 작업이라면? 사람이 직접 승인하는 단계를 넣어야 합니다.
Meta의 보안 연구원 Mick Ayzenberg는 “[B]는 민감한 시스템에 대한 모든 접근을 의미한다”고 명확히 했습니다. 샌드박스나 프로덕션과 격리된 환경에서라면 A와 C를 함께 써도 위험도가 낮다는 뜻이죠. 이런 피드백을 반영해 Meta는 벤 다이어그램의 교차 영역 표시를 “안전함”에서 “낮은 위험”으로 수정했습니다.
단순함의 힘, 그리고 한계
Simon Willison은 Rule of Two를 “매우 마음에 든다”고 평가했습니다. 그는 수년간 개발자들에게 프롬프트 인젝션 위험을 설명하려 애썼는데, “좌절스러울 만큼 어려웠다”고 털어놨죠. 그의 “lethal trifecta” 개념은 데이터 유출 위험을 잘 설명했지만, 상태 변경 같은 다른 공격 시나리오는 커버하지 못했어요. Rule of Two는 “상태 변경” 속성을 추가해 더 넓은 범위의 공격을 포괄합니다.
다만 Willison은 한 가지 문제를 지적했습니다. 벤 다이어그램에서 A(신뢰할 수 없는 입력)와 C(상태 변경)의 조합을 “낮은 위험”으로 표시했는데, 민감한 시스템 접근 없이도 충분히 해로운 결과를 만들 수 있다는 거예요. 이 예외를 명시하면 “Rule of Two”라는 단순한 프레임이 복잡해지는 딜레마가 생기죠.
그럼에도 이 접근은 현실적입니다. “The Attacker Moves Second” 논문이 보여주듯, 믿을 만한 방어 기술은 아직 없습니다. 논문은 “방어 평가 기준을 높여 신뢰할 수 있는 방어책 개발 가능성을 높이자”고 낙관적으로 마무리하지만, Willison은 동의하지 않아요. 방어책들이 완전히 무력화된 결과를 보면, 가까운 미래에 완벽한 방어가 나오리라 기대하기 어렵다는 겁니다.
결국 지금 할 수 있는 최선은 시스템을 안전하게 설계하는 것입니다. Rule of Two는 그 출발점으로 충분히 실용적으로 보입니다.
참고자료:
답글 남기기