Claude
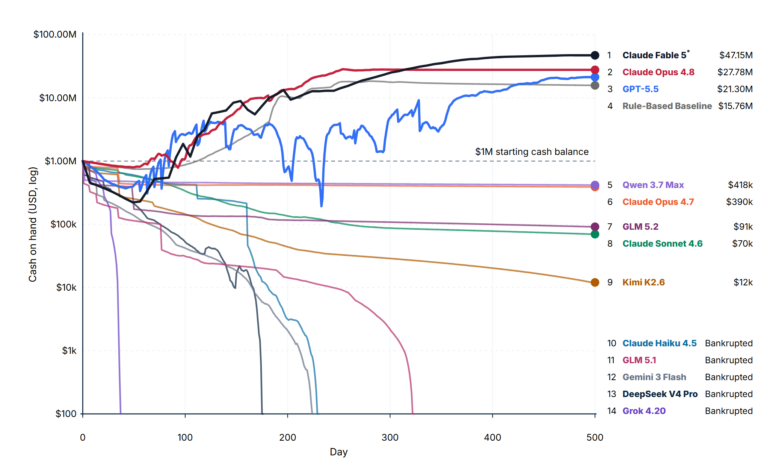
회사 하나를 500일 맡겼더니, AI 14개 중 11개가 파산했다
프린스턴 연구진의 CEO-Bench는 AI에게 가상 스타트업을 500일 경영하게 했습니다. 14개 모델 중 3개만 생존하고 단순 규칙 봇이 대부분을 이긴 결과를 소개합니다.
Written by
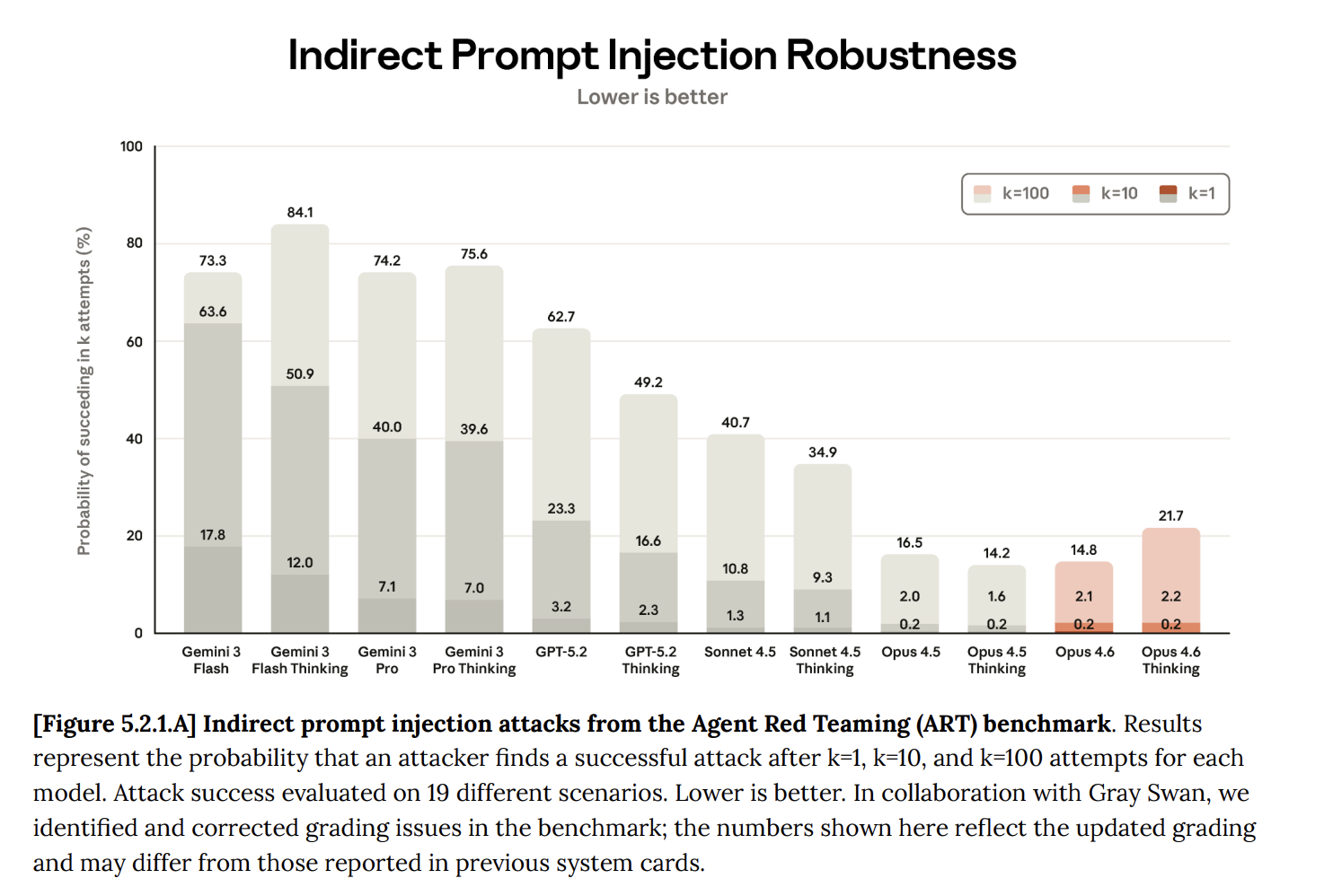
프롬프트 인젝션 6000번 공격, AI 에이전트가 다 막아낸 실험
2,000명이 6,000번 공격했지만 비밀은 새지 않았다. Claude Opus 4.6 기반 AI 비서를 대상으로 한 프롬프트 인젝션 실험과, 개인 사용자가 읽어야 할 의미를 짚습니다.
Written by
GLM-5.2, 보안 취약점 탐지에서 클로드 코드를 이기다
오픈웨이트 모델 GLM-5.2가 Semgrep 보안 벤치마크에서 프롬프트만으로 Claude Code를 6분의 1 비용에 앞섰습니다. 결과의 의미와 한계, 그 뒤의 엔지니어링을 짚습니다.
Written by

AI가 구글에서 50만 달러어치 취약점을 찾았다, 비결은 똑똑함이 아니었다
보안 연구자가 AI에게 구글 API 수천 개를 자동 점검시켜 50만 달러 버그 바운티를 받은 사례. AI가 효과적이었던 진짜 이유는 똑똑함이 아니라 지치지 않는 규모였습니다.
Written by
Claude가 신분증을 요구하기 시작했다, AI 챗봇에 들어온 신원 인증의 의미
Anthropic이 7월 8일부터 Claude 소비자 사용자에게 정부 신분증과 얼굴 인증을 요구합니다. 생체정보 수집과 수출통제 배경, 개인 사용자에게 갖는 의미를 짚습니다.
Written by

엔지니어 99%가 매일 AI를 쓰는 회사에서 벌어진 일, 스포티파이가 본 진짜 병목
엔지니어 99%가 AI 코딩 도구를 쓰는 스포티파이에서 병목이 코딩에서 의사결정으로 옮겨간 이야기. 백그라운드 에이전트 Honk와 ‘에이전트를 위한 개발자 경험’을 소개합니다.
Written by

API 키 한 줄만 바꾸면 90% 싸진다는데, 그 차액은 누가 채우고 있을까
90% 싸게 AI API를 쓸 수 있다는 중계 서비스의 이면, 모델 바꿔치기와 코드 주입 위험을 실증한 두 연구 결과를 소개합니다.
Written by

AI 검색 3사가 같은 질문을 처리하는 방식, Google vs OpenAI vs Claude 비교
Google, OpenAI, Anthropic 세 AI 플랫폼이 같은 검색 쿼리를 처리하는 방식 비교. 수신 페이지 수, 인용 비율, 스니펫 구조가 플랫폼마다 어떻게 다른지 실험 데이터로 분석합니다.
Written by
Fable 5 숨겨진 가드레일, Anthropic이 결국 사과하고 번복했습니다
Anthropic이 Fable 5의 숨겨진 가드레일 정책을 번복하고 공개 사과했습니다. 빠른 출시를 위해 투명성을 양보한 이유와 AI 도구 신뢰의 문제를 짚습니다.
Written by

Fable 5 가드레일 두 가지, 하나는 보이고 하나는 안 보인다
Anthropic의 Fable 5에는 두 종류의 가드레일이 있습니다. 사이버·바이오 차단은 사용자에게 알리지만, 경쟁 AI 개발 관련 성능 저하는 알리지 않습니다.
Written by
