Meta(메타)가 최신 AI 모델인 Llama 4를 출시하면서 AI 기술 개발의 새로운 장이 열렸습니다. 이번에 출시된 Llama 4는 단순한 업그레이드가 아닌, AI 모델 아키텍처와 성능에서 혁신적인 진전을 보여주는 모델로, 개발자와 기업이 더욱 강력하고 효율적인 AI 솔루션을 구축할 수 있는 기반을 마련했습니다.
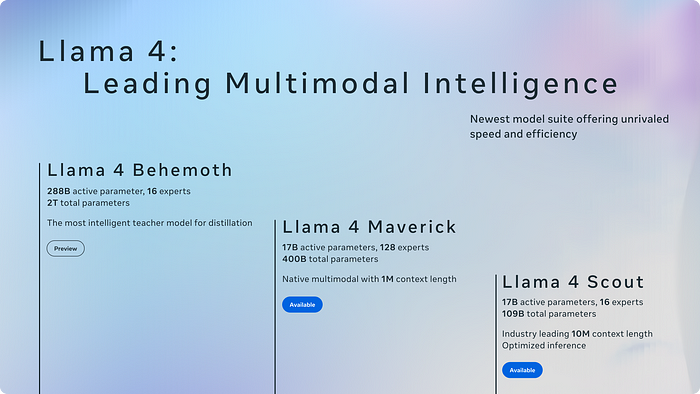
Llama 4의 세 가지 모델: Scout, Maverick, Behemoth
Meta는 이번에 세 가지 Llama 4 모델을 ‘무리(herd)’라는 개념으로 소개했습니다. 각 모델은 고유한 특성과 장점을 가지고 있어 다양한 사용 사례에 맞게 선택할 수 있습니다.
 Meta의 Llama 4 모델 시리즈: Scout, Maverick, Behemoth (출처: Meta)
Meta의 Llama 4 모델 시리즈: Scout, Maverick, Behemoth (출처: Meta)
Llama 4 Scout: 경량화된 효율성의 결정체
Llama 4 Scout는 ‘가벼움’과 ‘효율성’에 초점을 맞춘 모델입니다. 핵심 특징은 다음과 같습니다:
- 17B 활성 파라미터, 16개 전문가(experts)로 구성된 총 109B 파라미터 모델
- 업계 최고 수준인 1천만(10M) 토큰 컨텍스트 윈도우 지원
- 단일 NVIDIA H100 GPU에서 실행 가능 (Int4 양자화 적용 시)
- 이미지와 텍스트를 함께 처리할 수 있는 네이티브 멀티모달 기능
Scout는 Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1과 같은 유사한 크기의 모델들을 다양한 벤치마크에서 능가하는 성능을 보여줍니다. 특히 긴 문서를 한번에 요약하거나, 방대한 코드베이스를 분석하는 작업에 탁월합니다.
Llama 4 Maverick: 강력한 성능의 멀티모달 모델
Maverick는 Llama 4 시리즈의 ‘주력’ 모델로, 더 큰 규모와 성능을 자랑합니다:
- 17B 활성 파라미터, 128개 전문가로 구성된 총 400B 파라미터 모델
- 고급 이미지 및 텍스트 이해 능력으로 복잡한 시각적 추론 가능
- 단일 H100 DGX 호스트에서 실행 가능
- GPT-4o, Gemini 2.0 Flash, DeepSeek v3와 같은 경쟁 모델들을 능가하는 성능
LMArena 평가에서 1417 ELO 점수를 기록하며 최첨단 성능을 입증했습니다. 이미지 이해력과 텍스트 생성 능력이 뛰어나 일반적인 어시스턴트 및 챗봇 사용 사례에 적합합니다.
Llama 4 Behemoth: 가르치는 모델
Behemoth는 현재 완전히 공개되지 않은 ‘교사’ 모델로, Scout와 Maverick의 개발에 중요한 역할을 했습니다:
- 288B 활성 파라미터, 16개 전문가로 구성된 약 2조(2T) 총 파라미터 모델
- GPT-4.5, Claude Sonnet 3.7, Gemini 2.0 Pro를 STEM 벤치마크에서 능가
- Scout와 Maverick 모델을 위한 지식 증류(knowledge distillation) 역할
혁신적인 아키텍처: MoE와 멀티모달 설계
Llama 4가 이전 세대와 확연히 다른 점은 두 가지 핵심 기술을 도입했다는 것입니다: Mixture of Experts(MoE) 아키텍처와 네이티브 멀티모달 설계입니다.
Mixture of Experts(MoE): 효율적인 전문가 시스템
MoE는 모든 입력을 모든 파라미터로 처리하는 대신, 특정 작업에 특화된 ‘전문가’ 네트워크들의 조합을 활용하는 방식입니다.
 Llama 4의 MoE 아키텍처 (출처: Meta)
Llama 4의 MoE 아키텍처 (출처: Meta)
작동 방식은 다음과 같습니다:
- 라우터(Router): 입력 토큰을 분석하여 어떤 전문가가 처리하는 것이 가장 적합한지 결정합니다.
- 선별적 활성화: 전체 파라미터 중 일부만 활성화되어 효율적인 처리가 가능합니다.
- 공유 전문가 + 라우팅된 전문가: Maverick 모델의 경우, 모든 토큰이 공유 전문가를 거치고, 추가로 128개 전문가 중 하나를 통과합니다.
이 구조는 훨씬 적은 컴퓨팅 자원으로 더 큰 모델의 성능을 구현할 수 있게 합니다. 예를 들어 Maverick는 400B 총 파라미터 중 단 17B만 활성화하여 처리 비용과 지연 시간을 크게 줄였습니다.
네이티브 멀티모달 설계: 조기 융합(Early Fusion)
Llama 4의 또다른 혁신은 ‘네이티브 멀티모달’ 설계입니다. 기존 모델들이 텍스트와 이미지를 별도로 처리하고 나중에 결합하는 방식과 달리, Llama 4는 ‘조기 융합(Early Fusion)’ 방식을 도입했습니다.
이 방식에서는:
- 텍스트와 이미지 토큰이 하나의 통합된 모델 백본으로 원활하게 통합됩니다.
- MetaCLIP 기반의 개선된 비전 인코더가 LLM에 맞게 최적화되었습니다.
- 모델이 텍스트, 이미지, 비디오를 포함한 대량의 데이터로 함께 사전 훈련되었습니다.
이를 통해 Llama 4는 최대 8개의 이미지를 동시에 처리하고, 이미지 내 영역을 정확히 인식하는 우수한 능력을 보여줍니다.
10M 토큰 컨텍스트 윈도우: 초장문 처리의 새 지평
Llama 4 Scout가 가진 또 다른 혁신적 특징은 1천만(10M) 토큰에 달하는 컨텍스트 윈도우입니다. 이는 이전 Llama 3의 128K에서 약 80배 증가한 수치로, 오픈 소스 모델 중 가장 긴 컨텍스트 길이입니다.
이를 가능케 한 기술적 혁신은 “iRoPE(interleaved Rotary Position Embeddings)” 아키텍처입니다:
- 무위치 임베딩 레이어 교차 사용: 위치 임베딩이 있는 레이어와 없는 레이어를 번갈아 사용합니다.
- 추론 시간 온도 스케일링: 주의(attention) 메커니즘의 온도를 조절하여 초장문 맥락에서도 정보를 잃지 않게 합니다.
아래 그림에서 볼 수 있듯이, Scout 모델은 1천만 토큰까지 정보를 검색할 수 있습니다:
 Llama 4 모델의 텍스트 검색 성능 (출처: Meta)
Llama 4 모델의 텍스트 검색 성능 (출처: Meta)
이러한 초장문 컨텍스트 처리 능력은 다음과 같은 응용 분야에서 획기적인 발전을 가져옵니다:
- 여러 문서를 한 번에 요약하고 비교 분석
- 방대한 사용자 활동 기록을 기반으로 개인화된 응답 생성
- 대규모 코드베이스 전체를 이해하고 분석
혁신적인 훈련 방식: MetaP와 증류 학습
Llama 4 개발에서 또 다른 중요한 혁신은 훈련 과정에 있습니다. Meta는 “MetaP”라는 새로운 학습 기법을 개발해 레이어별 학습률과 초기화 스케일과 같은 중요한 모델 하이퍼파라미터를 안정적으로 설정할 수 있게 했습니다.
또한 사후 훈련(post-training) 과정에서 다음과 같은 혁신적인 방식을 채택했습니다:
- 경량화된 지도 학습(SFT): Llama 모델을 판사로 사용해 ‘쉬운’ 데이터의 50%를 제거하고, 남은 어려운 데이터셋으로 초기 학습
- 온라인 강화 학습(RL): 어려운 프롬프트를 지속적으로 선별하고 필터링하는 전략 도입
- 경량화된 직접 선호도 최적화(DPO): 모델 응답 품질과 관련된 특수 사례를 처리
특히 Behemoth 모델에서 Scout와 Maverick로의 지식 증류(knowledge distillation)는 더 작은 모델의 성능을 크게 향상시키는 핵심 요소였습니다.
클라우드 서비스 통합: 누구나 접근 가능한 Llama 4
Llama 4의 출시와 함께, 주요 클라우드 서비스 제공업체들과의 협력을 통해 개발자와 기업이 쉽게 이 모델들을 사용할 수 있게 되었습니다:
- Meta AI: WhatsApp, Messenger, Instagram Direct, 그리고 웹에서 직접 이용 가능
- Hugging Face: 허깅페이스 플랫폼에서 모델 다운로드 및 배포 가능
- AWS: Amazon SageMaker JumpStart, 곧 Amazon Bedrock에서도 제공 예정
- Microsoft Azure: Azure AI Foundry 및 Azure Databricks에서 이용 가능
- Cloudflare: Workers AI 플랫폼에서 서버리스 방식으로 이용 가능
이러한 광범위한 통합은 Llama 4를 더 많은 개발자와 기업이 쉽게 활용할 수 있게 하며, Meta의 개방형 AI 생태계 비전을 실현하는 데 기여합니다.
Llama 4의 비전: 개방성이 혁신을 이끈다
Meta는 “개방성이 혁신을 이끈다(openness drives innovation)”는 철학을 바탕으로 Llama 4를 공개했습니다. 이는 개발자, Meta, 그리고 세계 전체에 이로운 접근법이라는 신념에서 비롯됩니다.
Mark Zuckerberg의 말에 따르면: “가장 지능적인 시스템은 일반화된 행동을 취하고, 인간과 자연스럽게 대화하며, 이전에 보지 못한 어려운 문제를 해결할 수 있어야 합니다.”
이러한 비전을 바탕으로, Llama 4는 다음과 같은 방향으로 AI 생태계를 발전시킬 것으로 기대됩니다:
- 접근성 향상: 고성능 AI를 더 많은 개발자와 기업이 활용 가능하게 함
- 다중 언어 지원: 200개 언어에 대한 사전 훈련으로 글로벌 사용자 지원
- 개인화된 경험: 더 나은 멀티모달 경험을 구축할 수 있는 기반 제공
- 편향성 감소: 정치적, 사회적 주제에서 더 균형 잡힌 관점 제공
결론: AI의 새로운 시대를 열다
Llama 4는 단순한 모델 업그레이드가 아닌, AI 개발의 새로운 시대를 여는 중요한 이정표입니다. MoE 아키텍처, 네이티브 멀티모달 설계, 10M 토큰 컨텍스트 윈도우와 같은 혁신적 기술은 AI 모델의 미래 방향을 제시합니다.
더욱 중요한 것은, Meta의 개방형 접근 방식이 더 많은 사람들이 첨단 AI 기술에 접근하고 활용할 수 있게 함으로써 더 다양하고 혁신적인 응용 프로그램의 개발을 촉진한다는 점입니다. 이는 AI 기술의 민주화와 발전에 크게 기여할 것입니다.
Llama 4는 “가능한 것의 한계(what’s possible)”를 확장하며, 개발자와 기업이 더 지능적이고 접근성 높은 AI 솔루션을 구축할 수 있는 새로운 지평을 열었습니다. 앞으로 AI 커뮤니티가 이 기술을 활용해 어떤 혁신적인 응용 프로그램을 개발할지 기대됩니다.
답글 남기기