새 CLI를 출시했습니다. 개발자 경험도 좋고, 구조도 현대적이고, 에이전트에 최적화돼 있죠. 옛 도구는 폐기 처리하고, 문서도 갱신하고, 공지 글까지 올렸습니다. 그런데 누군가 AI 코딩 에이전트에게 프로젝트를 만들어 달라고 하면, 에이전트는 폐기한 옛 도구를 꺼내 듭니다.

마이크로소프트의 Principal Developer Advocate인 Waldek Mastykarz가 개발자 블로그에 이 현상을 분석한 글을 올렸습니다. AI 코딩 에이전트가 새로 나온 도구 대신 익숙한 옛 도구를 고집하는 이유를 “훈련 데이터 중력(training data gravity)”이라는 개념으로 설명합니다. 핵심은 단순합니다. 모델의 자신감은 도구의 최신성이 아니라, 인터넷에 쌓인 콘텐츠의 양에 비례한다는 것입니다.
출처: Competing against yourself – Microsoft for Developers
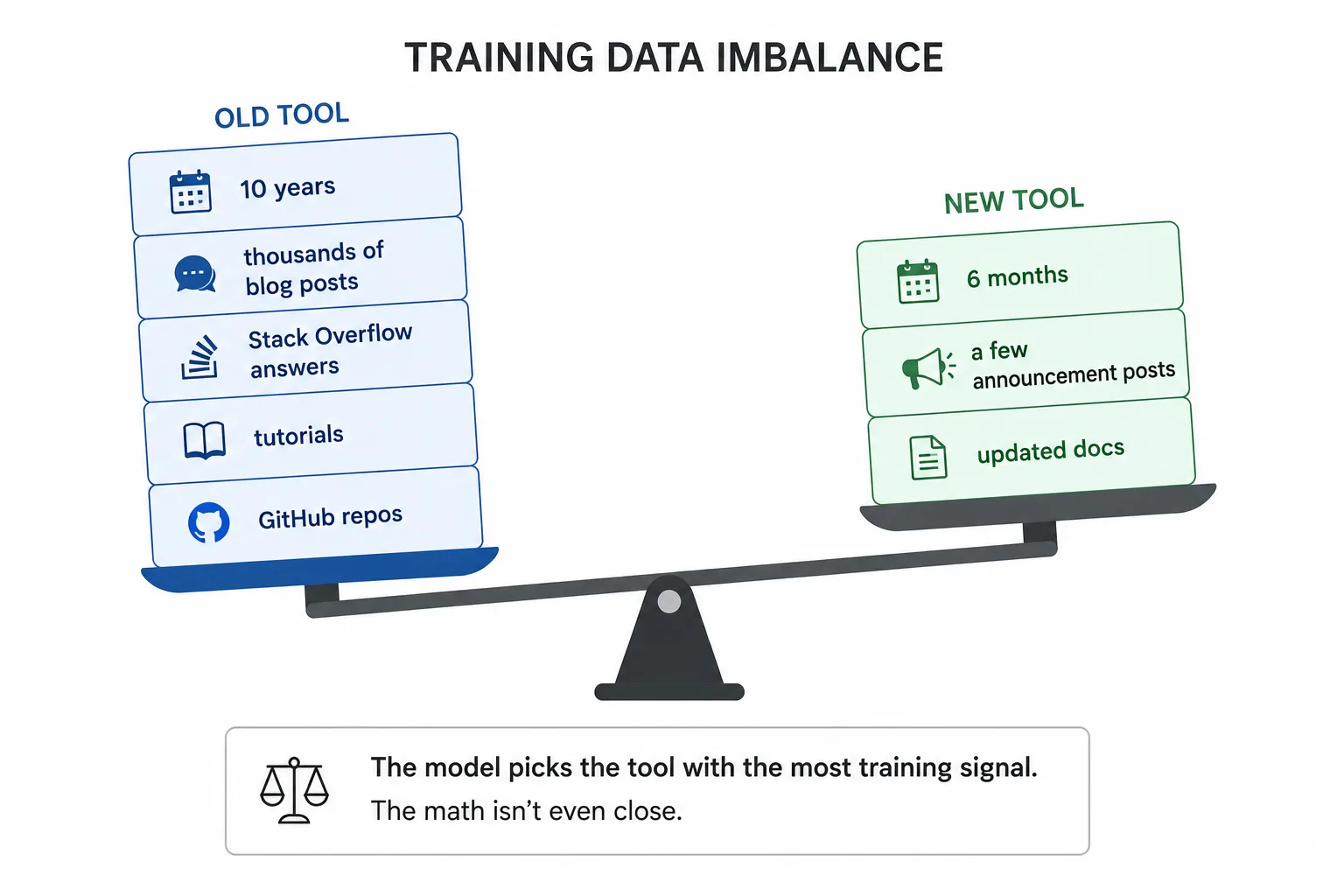
10년 대 6개월, 승부가 안 되는 싸움
모델은 인터넷에서 학습합니다. 어떤 기술이 10년 동안 존재했다면 그 도구를 다루는 블로그 글, 스택오버플로 답변, 튜토리얼, 깃허브 저장소가 수천 개씩 쌓여 있습니다. 반면 막 출시한 새 CLI는 공지 글 몇 개와 갱신된 문서가 전부죠.
개발자가 에이전트에게 프로젝트 생성을 요청하면, 모델은 훈련 데이터에서 가장 그럴듯한 도구를 끌어옵니다. 방대한 데이터 덕분에 모델은 그 도구로 충분히 일을 해낼 수 있다고 꽤 자신합니다. 최신 문서를 찾아보지도, 출시일이나 폐기 공지를 확인하지도 않습니다. 그냥 가장 잘 아는 것, 즉 옛 도구로 기웁니다. 10년치 콘텐츠 대 6개월치 콘텐츠. 애초에 게임이 안 됩니다.
이건 가상의 이야기가 아닙니다. 마이크로소프트의 SharePoint Framework(SPFx) 팀은 오래 써온 Yeoman 기반 생성기를 대체할 새 독립형 CLI를 준비하면서, 출시 전에 이 위험을 평가해 달라고 요청했습니다. 결과는 분명했습니다. 에이전트는 새 CLI를 완전히 무시하고 곧장 Yeoman 생성기로 향했습니다. 심지어 새 도구를 쓰라고 명시적으로 지시했을 때조차, 에이전트는 그 지시가 부정확하다고 판단하고 기존 생성기로 되돌아갔습니다.
모델은 새 도구를 고려했다가, 스스로 기각한다
이 문제가 까다로운 이유가 여기 있습니다. 모델이 무작정 옛 도구를 고르는 게 아닙니다. 많은 경우 새 도구를 고려한 뒤, 스스로 그 생각을 접습니다.
에이전트의 추론 흔적에서 이런 패턴이 관찰됐습니다. 한 평가에서 모델의 내부 추론은 대략 이런 식이었습니다. “이 플랫폼 CLI는 보통 [기존 도구]를 가리킨다. 독립형 CLI 도구가 새로 나왔을 수도 있겠지만, 표준 방식은 여전히 [기존 도구]를 쓰는 것이다.”
모델은 새로운 무언가가 있을지도 모른다고 생각했습니다. 가능성을 따져봤지만 확인할 신호를 충분히 찾지 못했고, 결국 가장 강한 사전 확률(prior)로 회귀했습니다. 주어진 훈련 데이터만 놓고 보면 이 결론은 합리적입니다. 모델은 제 할 일을 한 것뿐이죠. 다만 낡은 데이터로 작업하고 있었고, 그 너머를 보라고 알려주는 지시가 없었을 뿐입니다.
이름이 문제를 더 키운다
Vite를 webpack과 헷갈리는 사람은 없습니다. Bun을 npm과 혼동하지도 않죠. 독특한 이름은 그 자체로 모델의 지식 안에 별도의 자리를 만듭니다.
문제는 새 도구의 이름이 범주를 설명하는 일반명처럼 읽힐 때입니다. “v2 CLI”, “새 SDK”, “[플랫폼] CLI” 같은 이름은 모델 안에서 기존 도구와 같은 개념으로 뭉뚱그려집니다. 한 생태계에 공식 생성기, 커뮤니티 CLI, 레거시 독립 도구가 뒤섞여 있고 이름까지 겹치면, 모델은 그중 훈련 데이터가 가장 많은 것을 고릅니다. 당신이 어느 것을 의도했든 상관없이 말이죠. 독특한 이름은 이 신호를 만들어 주지만, 서술형 이름은 정반대로 작용합니다.
자신감은 정확성이 아니라 데이터 양이다
이 현상이 흥미로운 건 CLI에만 국한되지 않기 때문입니다. 새 SDK 버전, 프레임워크 마이그레이션(클래스 컴포넌트에서 훅으로), 빌드 도구 교체(webpack에서 Vite로), 인증 방식 변경처럼 새 도구가 기존 도구와 공존하는 모든 전환에서 같은 일이 벌어집니다. 새 방식은 존재하지만, 사전 확률을 뒤집을 만큼의 신호를 갖지 못한 상태죠.
여기서 건져낼 통찰은 분명합니다. 에이전트가 도구를 고를 때 보이는 자신감은 그 도구가 지금 옳다는 신호가 아니라, 단지 많이 문서화됐다는 신호라는 점입니다. 모델은 “널리 기록된 것”과 “현재 맞는 것”을 구분하지 못합니다. 데이터가 현실을 몇 달, 길게는 몇 년씩 뒤따라오기 때문입니다.
그래서 에이전트가 익숙하게 옛 도구를 꺼내 들 때, 그 익숙함을 곧 정확성으로 받아들이지 않는 감각이 필요합니다. 특히 최근 바뀐 기술 스택을 다룰 때, 에이전트의 첫 선택이 가장 최신의 선택은 아닐 가능성이 높습니다. 원문은 이 현상을 측정하고 대응하는 플랫폼 팀 차원의 방법들도 함께 다루는데, 도구를 만드는 입장이라면 한 번 읽어볼 만합니다.
답글 남기기