구글이 Gemini 2.5 모델 패밀리의 대대적인 업데이트를 발표했습니다. 이번 업데이트는 단순한 성능 향상을 넘어서 AI 모델의 사고 방식 자체를 혁신한 의미 있는 변화입니다. 특히 “Thinking Models”라는 새로운 개념을 도입하여 AI가 응답하기 전에 내적 사고 과정을 거치도록 하는 혁신적인 접근법을 선보였습니다.

출처: Google Developers Blog
Thinking Models: AI 사고의 새로운 패러다임
Gemini 2.5 시리즈의 가장 큰 특징은 “Thinking Models”입니다. 기존 AI 모델이 질문을 받으면 즉시 답변을 생성하는 방식과 달리, Thinking Models은 먼저 내부적으로 사고 과정을 거친 후 최종 답변을 제공합니다. 이는 마치 사람이 복잡한 문제를 접했을 때 머릿속으로 여러 가지 가능성을 검토하고 논리적으로 추론한 후 답변하는 것과 유사합니다.
이러한 접근법의 핵심은 “동적 사고 예산(Dynamic Thinking Budget)” 제어입니다. 개발자는 모델이 얼마나 많은 “생각”을 하도록 할지 직접 조절할 수 있습니다. 복잡한 수학 문제나 코딩 작업에는 더 많은 사고 토큰을 할당하고, 단순한 분류 작업에는 사고 과정을 아예 비활성화할 수 있습니다.
실제로 구글 API 문서에 따르면, 사고 예산을 -1로 설정하면 모델이 작업의 복잡도에 따라 자동으로 사고량을 조절하며, 0으로 설정하면 사고 과정을 완전히 비활성화합니다. 이는 비용 효율성과 성능 최적화 사이에서 균형을 찾을 수 있는 강력한 도구입니다.
모델별 특징과 활용 시나리오
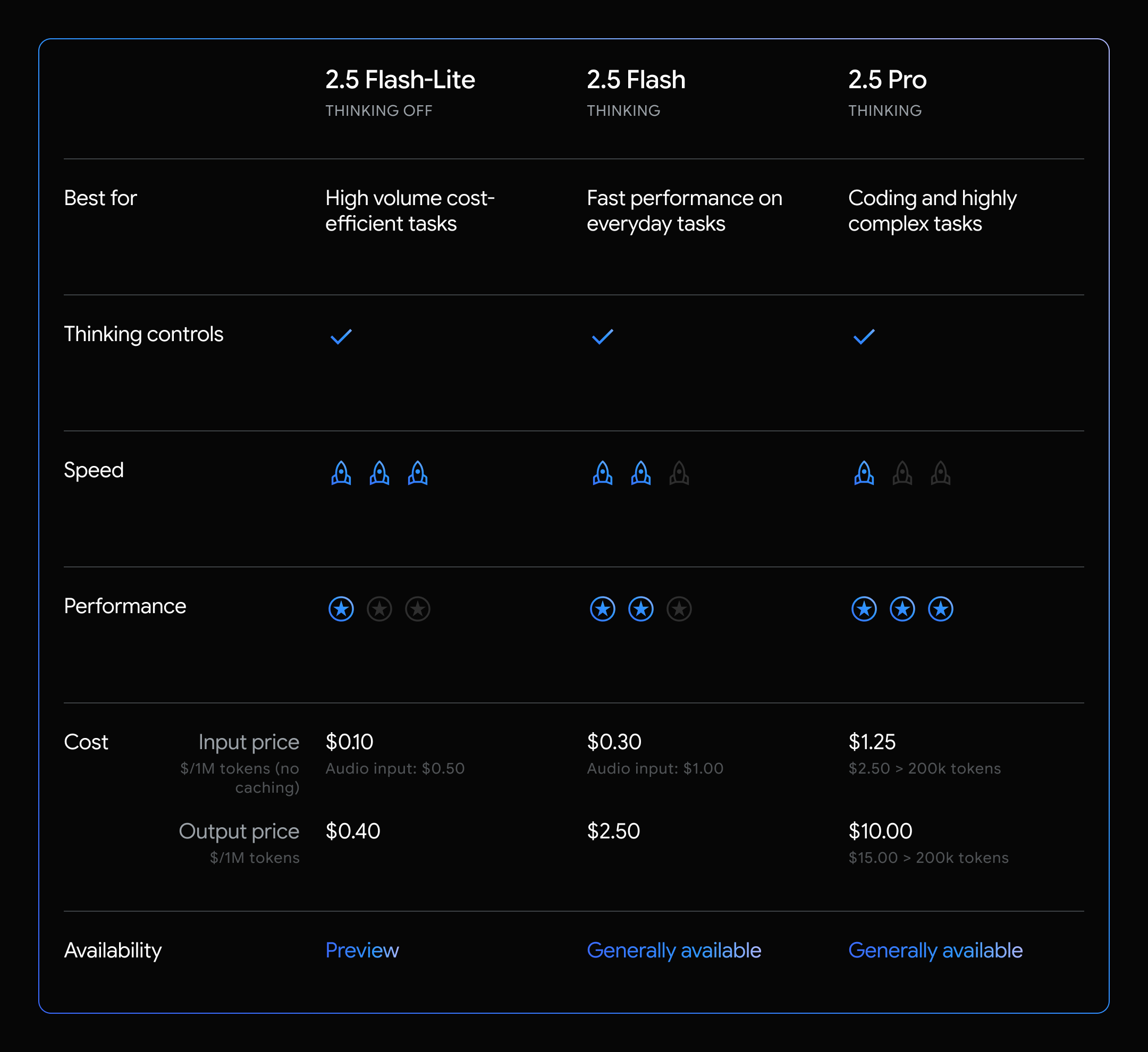
Gemini 2.5 Pro: 최고 성능의 플래그십 모델
Gemini 2.5 Pro는 가장 높은 지능과 성능을 자랑하는 플래그십 모델입니다. 구글의 발표에 따르면, 이 모델은 코딩과 에이전트 작업에서 특히 뛰어난 성능을 보입니다. 실제로 Cursor, Bolt, Cline과 같은 인기 있는 개발자 도구들이 이미 Gemini 2.5 Pro를 핵심 엔진으로 채택하고 있습니다.
Pro 모델의 특징은 사고 과정을 완전히 비활성화할 수 없다는 점입니다. 이는 이 모델이 본질적으로 복잡한 추론 작업을 위해 설계되었기 때문입니다. 사고 예산 범위는 128-32,768 토큰으로, 매우 복잡한 문제 해결에 충분한 사고 용량을 제공합니다.
Gemini 2.5 Flash: 균형잡힌 성능의 실용적 선택
Flash 모델은 성능과 비용 효율성 사이의 최적점을 찾은 모델입니다. 사고 예산을 0-24,576 토큰 범위에서 자유롭게 조절할 수 있어 다양한 작업에 유연하게 대응할 수 있습니다.
흥미롭게도 구글은 Flash 모델의 가격 정책을 조정했습니다. 입력 토큰 가격은 100만 토큰당 0.15달러에서 0.30달러로 인상되었지만, 출력 토큰 가격은 3.50달러에서 2.50달러로 인하되었습니다. 이는 대량의 출력을 생성하는 작업에서는 오히려 비용이 절약됨을 의미합니다.
Gemini 2.5 Flash-Lite: 경량화의 혁신

출처: Google Developers Blog
새롭게 출시된 Flash-Lite는 비용과 지연시간 최적화에 중점을 둔 모델입니다. 가장 큰 특징은 기본적으로 사고 과정이 비활성화되어 있다는 점입니다. 이는 빠른 응답이 필요한 대규모 분류나 요약 작업에 이상적입니다.
Flash-Lite는 이전 1.5 및 2.0 Flash 모델 대비 대부분의 평가 지표에서 향상된 성능을 보여주며, 첫 토큰까지의 시간(Time to First Token)이 더 짧고 초당 토큰 생성 속도(Tokens per Second)가 더 높습니다.
가격 정책 변화와 실무 적용 전략

출처: Google Developers Blog
구글이 “사고”와 “비사고” 가격 구조를 단일화한 것은 개발자들에게 매우 반가운 변화입니다. 이제 사고 토큰과 출력 토큰을 합산하여 단일 가격으로 책정되어 비용 계산이 훨씬 명확해졌습니다.
실무 적용 관점에서 볼 때, 각 모델의 선택 기준을 다음과 같이 정리할 수 있습니다:
고복잡도 작업 (Pro 선택): 복잡한 코딩 프로젝트, 다단계 추론이 필요한 분석 작업, 고급 수학 문제 해결 등에서는 Pro 모델의 강력한 사고 능력이 필수적입니다.
중간 복잡도 작업 (Flash 선택): 일반적인 텍스트 생성, 번역, 중간 수준의 분석 작업 등에서는 Flash 모델이 성능과 비용의 균형점을 제공합니다.
대량 처리 작업 (Flash-Lite 선택): 대용량 데이터 분류, 간단한 요약, 실시간 응답이 필요한 서비스 등에서는 Flash-Lite의 속도와 비용 효율성이 탁월합니다.
개발자 생태계와의 시너지

출처: Google Developers Blog
Gemini 2.5 Pro의 급속한 성장은 개발자 도구 생태계에서 그 진가를 입증하고 있습니다. Cursor, GitHub Copilot, Replit 등 주요 개발 환경에서 이미 핵심 엔진으로 채택되었으며, 이는 코딩 작업에서의 실질적인 성능 우위를 보여줍니다.
특히 주목할 점은 Thinking Models이 기존의 모든 Gemini 도구 및 기능과 완벽하게 호환된다는 것입니다. Google 검색 연동, 코드 실행, 함수 호출, 구조화된 출력 등의 기능을 사고 과정과 결합하여 더욱 정교한 결과를 얻을 수 있습니다.
마이그레이션과 전략적 고려사항
기존 Gemini 사용자들은 마이그레이션 일정을 주의깊게 계획해야 합니다. 2.5 Flash Preview 04-17 모델은 2025년 7월 15일에 지원이 종료되고, 2.5 Pro Preview 05-06 모델은 2025년 6월 19일에 서비스가 중단됩니다.
이러한 변화는 단순한 모델 업그레이드를 넘어서 AI 활용 전략의 근본적인 재검토를 요구합니다. Thinking Models의 도입으로 개발자들은 이제 작업의 성격에 따라 AI의 “사고 깊이”를 조절할 수 있게 되었으며, 이는 비용 최적화와 성능 향상을 동시에 달성할 수 있는 새로운 가능성을 열어줍니다.
결론: AI 개발의 새로운 장 시작
Gemini 2.5 모델 패밀리의 업데이트는 단순한 성능 향상을 넘어서 AI 모델의 작동 방식에 대한 패러다임 전환을 의미합니다. “생각하는 AI”라는 개념은 더 이상 공상과학 소설의 영역이 아닌 실제 개발 환경에서 활용할 수 있는 현실이 되었습니다.
개발자들에게는 이제 작업의 복잡도와 요구사항에 따라 AI의 사고 과정을 세밀하게 조절할 수 있는 도구가 주어졌습니다. 이는 비용 효율성과 성능 최적화 사이에서 더욱 정교한 균형을 찾을 수 있게 해주며, AI 기반 애플리케이션의 가능성을 크게 확장시킵니다.
앞으로 AI 모델 선택은 단순히 “더 좋은 모델”을 고르는 것이 아니라, 각 작업에 최적화된 “사고 방식”을 선택하는 것이 될 것입니다. 이러한 변화에 발맞춰 개발자들도 AI 활용 전략을 재정비하고, 새로운 가능성을 탐색해야 할 시점입니다.
참고자료:
답글 남기기