지난 1년간 AI 에이전트를 만드는 방식은 단순했습니다. While 루프를 돌리고, 사용자 프롬프트를 LLM에 전달하고, 도구를 호출하고, 결과를 다시 전달하는 과정의 반복이었죠. 이런 방식은 간단한 작업엔 효과적이지만, 3일에 걸쳐 50단계가 필요한 복잡한 작업에서는 컨텍스트를 잃고 무한 루프에 빠지거나 환각을 일으킵니다. Claude Code, Manus, OpenAI의 Deep Research 같은 애플리케이션이 이 한계를 극복하면서 AI 에이전트는 단순 반응에서 벗어나 계획하고, 기억하고, 작업을 위임하는 심층 구조로 진화하고 있습니다.

핵심 포인트:
- 컨텍스트 창의 한계 극복: 기존 에이전트는 모든 상태를 대화 기록에 저장해 복잡한 작업에서 목표를 잃었지만, Deep Agent는 외부 메모리와 명시적 플래닝으로 수백 단계의 작업 처리 가능
- 계층적 작업 위임 구조: 만능 에이전트 대신 Orchestrator가 전문화된 서브 에이전트(Researcher, Coder, Writer)에게 작업을 위임하고 정제된 결과만 받아 컨텍스트 효율성 극대화
- 반응에서 설계로의 전환: 단순히 LLM에 더 많은 도구를 연결하는 게 아니라, 명시적 계획 수립, 지속적 메모리 관리, 수천 토큰의 정교한 컨텍스트 엔지니어링을 통한 구조적 접근
Agent 1.0의 한계: 얕은 루프가 실패하는 이유
현재 대부분의 AI 에이전트는 ‘얕은(Shallow)’ 구조입니다. 전체 상태를 LLM의 컨텍스트 창, 즉 대화 기록에만 의존하죠.
작동 방식은 이렇습니다. 사용자가 “애플 주식 가격을 찾아서 지금 사기 좋은지 알려줘”라고 요청하면, LLM이 “검색 도구를 사용해야겠다”고 판단합니다. search("AAPL stock price")를 호출하고, 도구가 데이터를 반환하면 그 결과를 바탕으로 답변을 생성하거나 다른 도구를 호출합니다. 작업이 끝날 때까지 이 과정을 반복하죠.
이 아키텍처는 상태를 저장하지 않고 일시적입니다. 에이전트의 ‘뇌’ 전체가 컨텍스트 창 안에 있습니다. 작업이 복잡해지면 문제가 생깁니다. “경쟁사 10곳을 조사하고, 가격 모델을 분석하고, 비교 스프레드시트를 만들고, 전략 요약을 작성해줘” 같은 요청이 들어오면 실패합니다.
왜 실패할까요? 세 가지 이유가 있습니다. 첫째, 컨텍스트 오버플로우입니다. 도구 출력 결과들(HTML, 정리되지 않은 데이터)로 히스토리가 가득 차면서 원래 지시사항이 컨텍스트 창 밖으로 밀려납니다. 둘째, 목표 상실입니다. 중간 단계들의 노이즈 속에서 에이전트는 원래 목표를 잊어버립니다. 셋째, 복구 메커니즘이 없습니다. 잘못된 방향으로 빠져들면 멈추고 되돌아가서 새로운 접근을 시도할 선견지명이 없습니다.
이런 얕은 에이전트는 5-15 단계의 간단한 작업에는 훌륭하지만 500단계 작업엔 끔찍하죠!
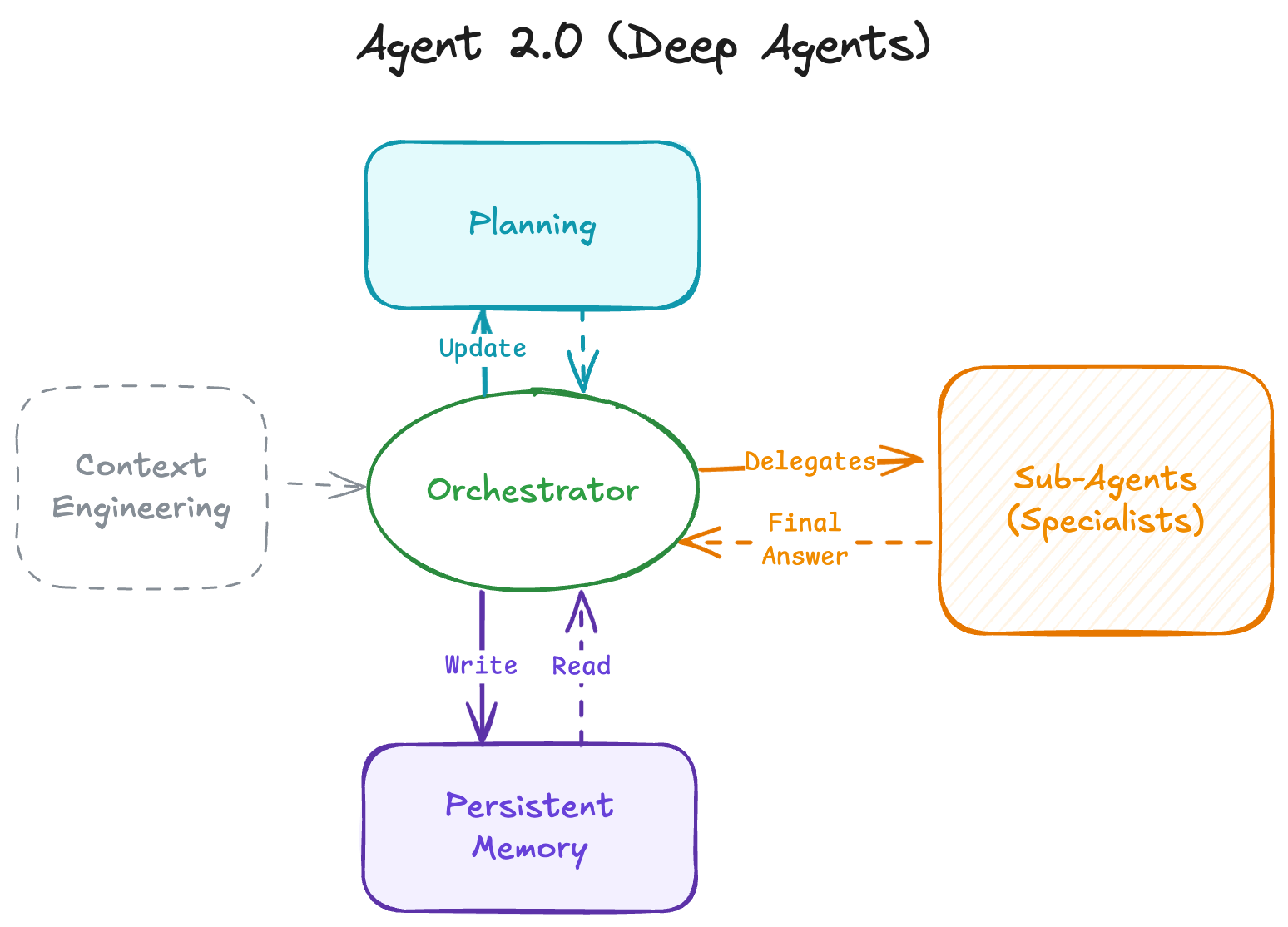
Agent 2.0의 4가지 핵심 구조
Deep Agent는 계획과 실행을 분리하고 컨텍스트 창 외부에서 메모리를 관리합니다. 네 가지 핵심 구조로 이뤄져 있습니다.
명시적 플래닝
얕은 에이전트는 단계별 추론(chain-of-thought)을 통해 암묵적으로 계획합니다. “X를 해야겠고, 그다음 Y를 해야지” 같은 식이죠. 반면 Deep Agent는 도구를 사용해 명시적인 계획을 만들고 유지합니다. 마크다운 문서로 된 To-Do 리스트 형태일 수 있습니다.
매 단계마다 에이전트는 이 계획을 검토하고 업데이트합니다. 단계를 pending, in_progress, completed로 표시하거나 메모를 추가합니다. 단계가 실패하면 맹목적으로 재시도하지 않습니다. 실패를 수용하도록 계획을 업데이트하죠. 이렇게 에이전트는 고수준 작업에 집중할 수 있습니다.
계층적 위임 (서브 에이전트)
복잡한 작업은 전문화가 필요합니다. 얕은 에이전트는 하나의 프롬프트로 모든 걸 해결하려 합니다. Deep Agent는 Orchestrator → Sub-Agent 패턴을 활용합니다.
Orchestrator가 작업을 서브 에이전트에게 위임하고, 각 서브 에이전트는 깨끗한 컨텍스트를 갖습니다. “Researcher”, “Coder”, “Writer” 같은 서브 에이전트는 각자의 도구 호출 루프(검색, 에러 처리, 재시도)를 수행하고 최종 답변을 정리해서 Orchestrator에게 합성된 답변만 반환합니다.
서브 에이전트는 두 가지 방식으로 구현됩니다. Claude Code처럼 미리 정의된 명시적 서브 에이전트는 재사용 가능하고 예측 가능하지만 확장성이 제한됩니다. 반면 Poke.com처럼 필요할 때마다 동적으로 생성되는 암묵적 서브 에이전트는 유연하지만 디버깅이 어렵습니다. 핵심은 컨텍스트 격리입니다. 각 서브 에이전트는 자신의 전문 영역에만 집중하고, Orchestrator는 중간 과정의 잡음 없이 정제된 결과만 받습니다.

지속적 메모리
컨텍스트 창 오버플로우를 방지하기 위해 Deep Agent는 파일 시스템이나 벡터 데이터베이스 같은 외부 메모리를 진실의 원천으로 활용합니다. 이는 인간의 인지와 유사하게 단기 메모리와 장기 메모리로 나뉩니다.
단기 메모리는 컨텍스트 창 자체입니다. 시스템 지시사항, 최근 대화 기록, 현재 작업에 필요한 정보를 담습니다. 빠르지만 일시적이고 크기가 제한됩니다. 장기 메모리는 외부 저장소에 보관되며 여러 세션에 걸쳐 정보를 저장하고 불러옵니다. 여기서 진정한 개인화와 “학습”이 일어나죠.
Claude Code나 Manus 같은 프레임워크는 에이전트에게 read/write 권한을 줍니다. 에이전트는 중간 결과물을 파일에 쓰고, 이후 에이전트들은 필요한 것만 가져옵니다. 패러다임이 “모든 것을 기억하기”에서 “정보를 어디서 찾을지 아는 것”으로 전환됩니다. 시장 조사에서 Researcher가 research_results.md에 결과를 저장하면, Writer는 나중에 이 파일만 읽어 보고서를 작성합니다.
극도로 정교한 컨텍스트 엔지니어링
더 똑똑한 모델이라고 해서 프롬프팅이 덜 필요한 건 아닙니다. 더 나은 컨텍스트가 필요합니다. “당신은 유용한 AI입니다”라는 프롬프트로는 Agent 2.0 동작을 얻을 수 없습니다. Claude Code의 재현된 시스템 프롬프트는 매우 깁니다.
Deep Agent는 때로 수천 토큰에 달하는 매우 상세한 지침에 의존합니다. 이 지침들은 다음을 정의합니다: 행동하기 전에 언제 멈추고 계획해야 하는지, 서브 에이전트를 생성할 때와 직접 작업할 때의 프로토콜, 도구 정의와 사용 시기 및 방법의 예시(few-shot 프롬프트), 파일 이름과 디렉토리 구조 표준, 휴먼-인-더-루프 협업을 위한 엄격한 형식. 이런 상세한 지침 없이는 에이전트가 언제 계획을 세워야 하는지, 어떻게 작업을 분할해야 하는지 모릅니다.
실제 작동 흐름
이 네 가지 구조가 어떻게 조합될까요? “양자 컴퓨팅을 조사하고 요약을 파일로 작성해줘”라는 복잡한 요청을 처리하는 Deep Agent의 시퀀스를 살펴보겠습니다.
먼저 Orchestrator가 요청을 받고 명시적 계획을 생성합니다. plan.md 파일에 “1. 양자 컴퓨팅 조사, 2. 요약 작성” 같은 단계를 기록합니다. 그다음 첫 번째 단계를 위해 Researcher 서브 에이전트를 생성합니다.
Researcher는 깨끗한 컨텍스트에서 시작합니다. 웹 검색을 수행하고, 여러 소스를 탐색하고, 중간 결과를 처리합니다. 이 모든 노이즈는 Researcher의 컨텍스트에만 남습니다. 조사가 끝나면 정제된 결과를 research_quantum_computing.md 파일에 저장하고 Orchestrator에게 “조사 완료, 파일 경로는 research_quantum_computing.md”라고 보고합니다.
Orchestrator는 계획을 업데이트합니다. 1단계를 completed로 표시하고, 2단계를 위해 Writer 서브 에이전트를 생성합니다. Writer는 research_quantum_computing.md 파일을 읽고 요약을 작성해서 summary_quantum_computing.md에 저장합니다.
전체 과정에서 Orchestrator의 컨텍스트는 깨끗하게 유지됩니다. 웹 검색의 HTML 조각들, 실패한 시도들, 중간 데이터는 Orchestrator에게 도달하지 않습니다. 각 서브 에이전트가 자신의 컨텍스트에서 처리하고 정제된 결과만 전달하기 때문입니다.
구조가 복잡성을 제어한다
Shallow Agent에서 Deep Agent로의 이동은 단순히 LLM에 더 많은 도구를 연결하는 게 아닙니다. 반응적 루프에서 능동적 아키텍처로의 전환입니다. 모델 주변을 더 잘 설계하는 것에 관한 문제죠.
명시적 플래닝, 서브 에이전트를 통한 계층적 위임, 지속적 메모리를 구현하면 컨텍스트를 제어할 수 있습니다. 컨텍스트를 제어하면 복잡성을 제어할 수 있습니다. 그렇게 몇 초가 아니라 몇 시간이나 며칠이 걸리는 문제를 해결할 수 있는 능력이 열립니다.
이 아키텍처 전환은 AI 에이전트가 실험실을 벗어나 실제 업무 환경에서 복잡한 프로젝트를 처리할 수 있는 기반이 됩니다. 간단한 질의응답을 넘어 장기적이고 복잡한 작업을 안정적으로 완수할 수 있는 시스템이 필요했고, Deep Agent가 그 답을 제시하고 있습니다.
참고자료:
답글 남기기