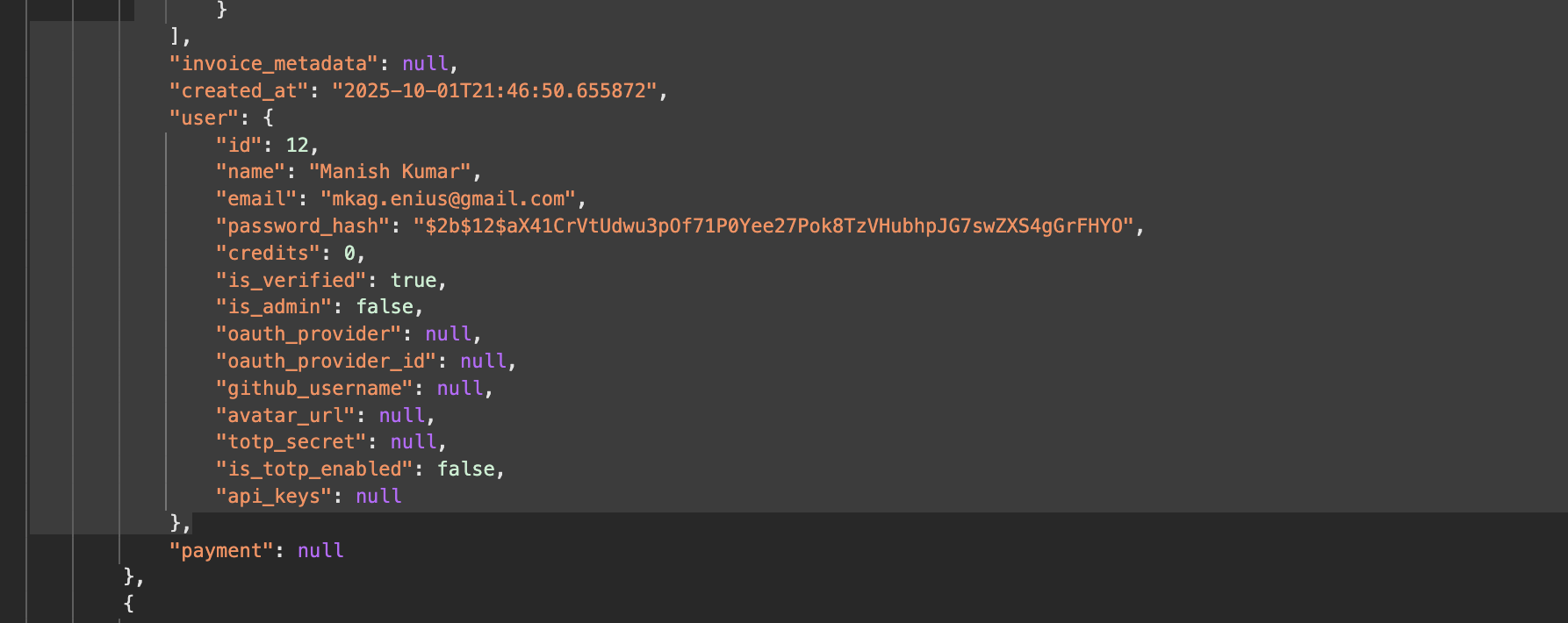
“AI 코딩 도구가 /invoices API를 작성하는 걸 지켜보고 있었습니다. 그런데 응답 JSON에 사용자 객체를 통째로 넣더니 password_hash까지 포함시켰어요. 당장 보안 문제는 아니지만, 공격자가 청구서 데이터만 탈취해도 비밀번호 해시까지 얻을 수 있다는 뜻입니다. 코드를 직접 확인하지 않았다면 완전히 놓칠 뻔했죠.”

InstaVM 팀이 15개월간 LLM을 실무에 사용하며 발견한 안티패턴을 정리한 글입니다. 이론이 아닌 프로덕션 환경에서 실제로 겪은 문제와 해결책을 다루고 있습니다. Claude Code나 Computer Use 같은 최신 도구의 한계와 우회 방법도 담았어요.
출처: LLM Anti-Patterns – InstaVM
1. 같은 말 반복하지 마세요
컨텍스트는 금보다 귀한 자원입니다. 그런데 우리는 종종 같은 정보를 여러 번 보내는 실수를 해요.
Anthropic의 Computer Use가 대표적인 예입니다. 마우스가 화면에서 A 지점에서 B 지점으로 이동할 때, 매 API 호출마다 이전 스크린샷을 전부 다시 보냅니다. 마우스 포인터가 1mm 움직인 걸 보여주는, 거의 똑같은 이미지들이죠. 현재 화면 하나만 보내도 충분한데 말입니다.
아이러니하게도 Anthropic은 최근 중복 메시지를 제거해주는 컨텍스트 관리 도구를 발표했습니다. InstaVM은 이 문제를 해결하기 위해 오픈소스 click3를 만들었어요. 중요한 변화가 있는 스크린샷만 보내서 중복을 완전히 제거했습니다.
2. 물고기에게 나무 타라고 하지 마세요
물고기가 가끔 나무를 오를 수는 있어도, 잘하는 일을 시키는 게 낫습니다.
저자는 Gemini에게 “1AA…”로 시작하는 텍스트(A가 두 개)를 나무판 이미지에 넣어달라고 했어요. 13번을 시도해도 계속 “1A…”(A가 하나)로 나왔습니다. 그래서 방법을 바꿨죠. 구글 독스에 텍스트를 쓰고 스크린샷을 찍어서, 이 이미지와 나무판 이미지를 합쳐달라고 했습니다. 1번 만에 성공했어요.
LLM에게 “BLUEBERRY에 R이 몇 개 있나요?”라고 묻지 마세요. R을 세는 코드를 짜달라고 하세요. 현재 LLM은 코딩 능력이 세기 능력보다 훨씬 뛰어납니다.
Cloudflare의 최근 발견도 이를 뒷받침합니다. 도구를 직접 호출하는 것보다 도구를 호출하는 코드를 작성하게 하는 게 더 정확하다는 걸요. 정확한 답을 원한다면 코드를 생성하게 하는 게 답인 것 같습니다.

3. 컨텍스트에 빠져 허우적대는 LLM
LLM은 128k 토큰이 꽉 차지 않았을 때 가장 잘 작동합니다. 긴 세션에서 128k를 넘어가면 더 심각해져요. Claude가 정보를 압축하거나 버릴지 스스로 판단하는데, 그 기준이 예측 불가능합니다.
저자는 실제로 이런 경험을 했습니다. 세션 초반에 제공한 데이터베이스 URL을 Claude가 완전히 잊어버리고, 엉뚱하게 다른 사람의 데이터베이스 URL을 출력했어요. 다행히 그 URL은 작동하지 않았지만, 만약 작동했다면 심각한 보안 문제가 될 뻔했죠.

어떤 작업은 큰 컨텍스트가 필요합니다. 그럴 땐 정확도가 떨어질 수 있다는 걸 염두에 두고 작업하세요.
4. 비주류 주제는 조심하세요
LLM은 잘 알려지지 않은 주제나 학습 데이터 마감일 이후에 등장한 기술에서 성능이 떨어집니다. 널리 논의된 주제에서는 잘 작동하지만, 문서화가 부족한 영역은 정확도를 기대하기 어렵습니다.
저자는 Stripe 통합을 구현하려다 Claude CLI가 포기하는 걸 목격했습니다. Stripe는 훌륭한 문서를 가진 서비스인데도 말이죠. 비주류 주제를 다룰 땐 정확도가 낮을 거라 예상하고, 정확도를 높일 방법을 미리 준비하세요.

5. Vibe-coder가 되지 마세요
Claude Code 같은 도구를 쓰다 보면 관리자 모드로 빠지기 쉽습니다. Andrej Karpathy는 이를 “vibe-coder”라고 불렀어요. LLM이 무슨 코드를 쓰는지 놓치는 순간, 결국엔 손해입니다.
맨 처음 예시로 돌아가볼까요. Claude가 청구서 API에 사용자 객체를 넣으면서 “password_hash”를 노출시킨 것처럼, 코드를 직접 확인하지 않으면 이런 허점을 놓칩니다. 비밀번호를 해싱조차 하지 않는, 더 큰 실수도 가능하고요.
무슨 일이 벌어지고 있는지 시선을 놓치지 마세요. AI가 생산성을 높여주는 건 맞지만, 책임은 여전히 우리에게 있습니다.
패턴을 알면 실수가 줄어듭니다
이 다섯 가지 안티패턴은 LLM을 “그냥 쓰는 것”과 “제대로 쓰는 것”의 차이를 보여줍니다. 컨텍스트를 아끼고, 모델의 강점을 활용하고, 한계를 염두에 두고, 코드를 직접 확인하는 것. 단순해 보이지만 실전에서 놓치기 쉬운 것들입니다.
15개월의 실무 경험에서 나온 교훈이니만큼, 여러분의 프로젝트에서 같은 실수를 반복하지 않는 데 도움이 되길 바랍니다.
참고자료:
답글 남기기