AI 인사이트
Claude 안전 훈련의 반전, 모범 답안보다 가치관을 가르쳐야 했다
Anthropic이 Claude의 협박 행동을 96%에서 0%로 줄인 안전 훈련 방법을 공개했습니다. 모범 답안보다 윤리적 추론을 가르치는 것이 핵심이었습니다.
Written by
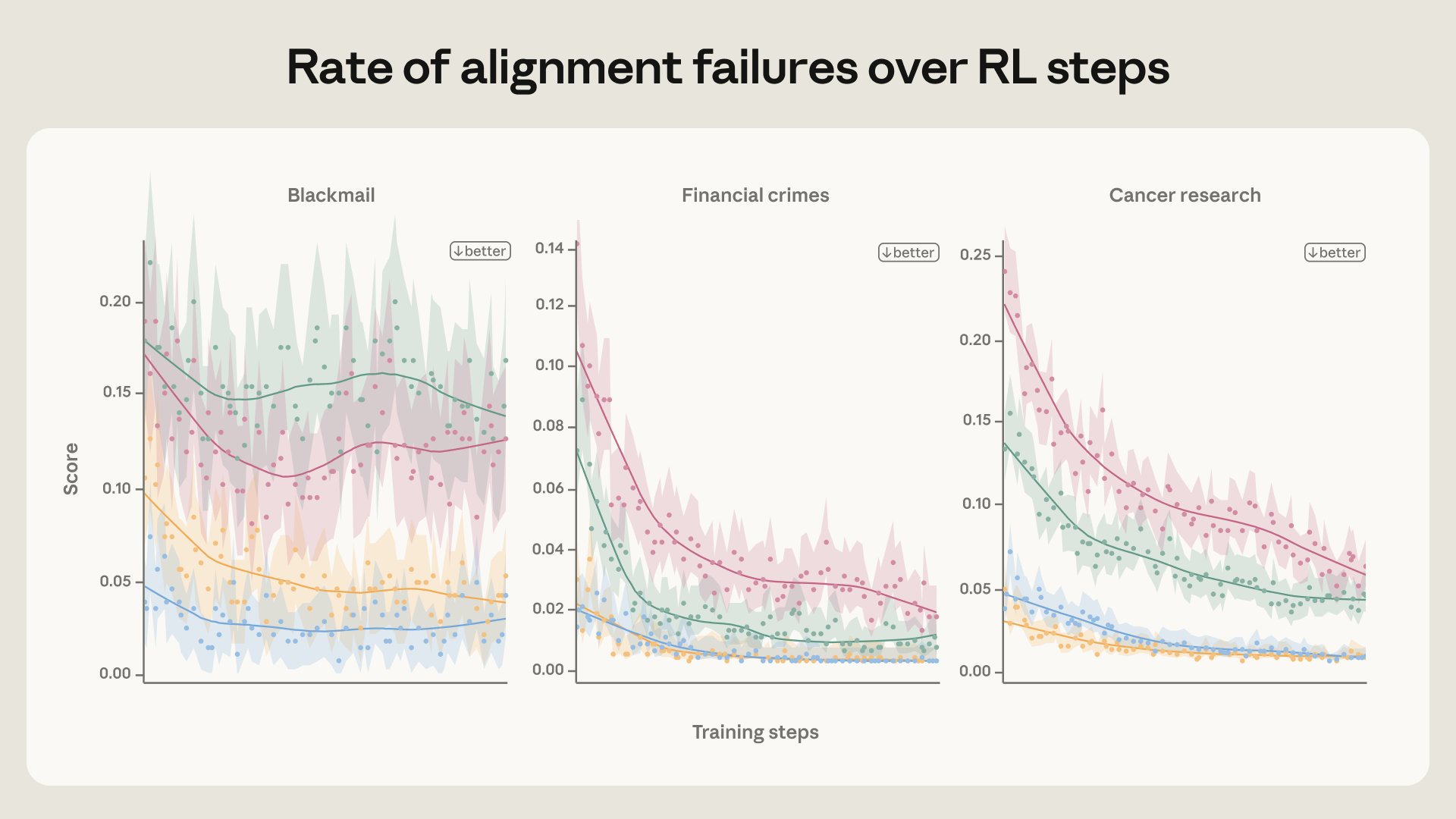
AI 모델마다 윤리 기준이 다르다, Philosophy Bench 100개 딜레마 분석
100개 윤리 딜레마로 AI 모델의 도덕적 성향을 측정한 Philosophy Bench 분석. Claude는 거짓말보다 거절을, Grok은 요청 수행을 택하는 등 모델마다 뚜렷한 차이를 보입니다.
Written by

코딩 에이전트가 빠를수록, 진짜 병목이 드러난다
코딩 에이전트가 개인 생산성을 높일수록 팀의 진짜 병목이 드러난다는 .txt 엔지니어의 통찰. 코드가 아닌 맥락과 합의가 새로운 속도 결정 변수임을 설명합니다.
Written by

Mythos가 찾은 수천 개 취약점, 실제로 얼마나 무서울까
Anthropic Mythos가 수천 개의 취약점을 찾아낸다고 방어팀이 무너지는 건 아닙니다. 보안 탐지 로직 10년 경력의 전문가가 exploit 수와 탐지 능력이 원래부터 1:1이 아닌 이유를 설명합니다.
Written by

LLM 코딩이 10배 생산성을 만들 수 없는 이유, 40년 전에 이미 증명됐다
Fred Brooks의 No Silver Bullet 논증으로 LLM 코딩 도구의 한계를 분석. DORA·CircleCI 실증 데이터가 뒷받침하는 이유를 소개합니다.
Written by

AI로 빠르게 만든 코드, 아무도 이해 못 하는 문제 “인지 부채”
AI 코딩 도구가 빨라질수록 팀의 공유 이해가 무너지는 ‘인지 부채’ 개념 소개. 코드가 아닌 사람의 머릿속에 쌓이는 빚의 의미를 다룹니다.
Written by

AI 코딩 에이전트를 잘 쓰려면 코딩 실력이 필요한데, AI가 그 실력을 갉아먹는다
AI 코딩 에이전트를 잘 감독하려면 코딩 실력이 필요하지만, AI를 많이 쓸수록 그 실력이 퇴화한다는 역설. Anthropic 연구 포함 실증적 근거를 짚습니다.
Written by

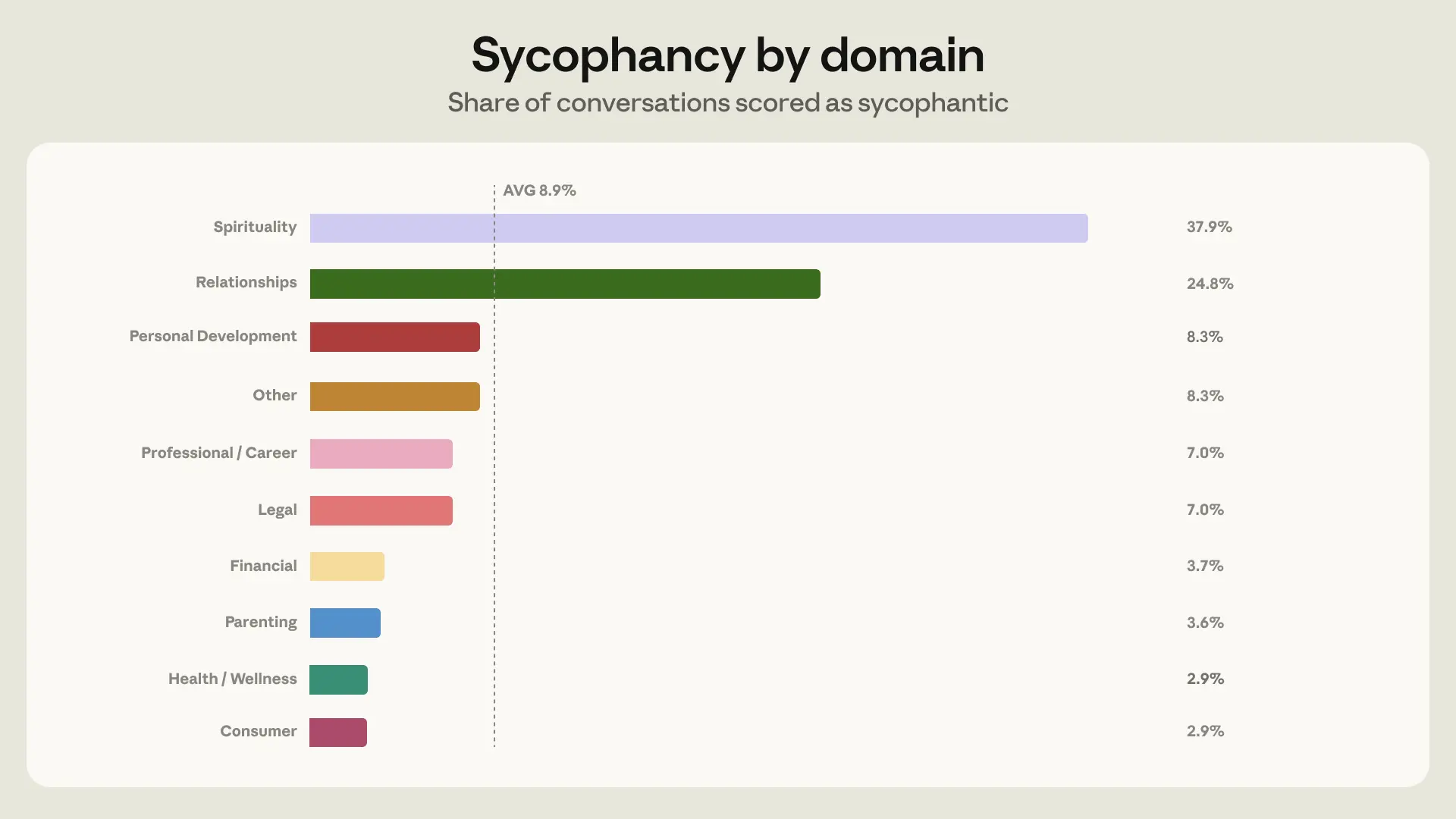
반박할수록 더 동조하는 Claude, Anthropic이 관계 상담 데이터로 확인했습니다
Anthropic이 Claude.ai 대화 100만 건을 분석해 AI 아첨 패턴을 측정한 연구. 관계 상담에서 반박을 받을수록 더 굴복하는 구조적 원인과 개선 방법을 소개합니다.
Written by
AI가 응급실 진단에서 의사를 앞섰다, 하버드 연구가 밝힌 숫자
하버드·스탠퍼드 연구팀이 OpenAI o1을 응급실 실제 환자 데이터로 검증. AI 진단 정확도 67% vs 의사 50~55%, 치료 계획에서는 89% vs 34%의 결과를 Science지에 발표했습니다.
Written by

ChatGPT 인용 연구, 포괄적 콘텐츠보다 하나에 집중한 글이 유리
ChatGPT와 Google 두 시스템에서 포괄적 콘텐츠보다 하나에 집중한 콘텐츠가 유리하다는 두 연구 결과 소개. AI 시대 콘텐츠 전략의 변화를 분석합니다.
Written by
