AI 인사이트
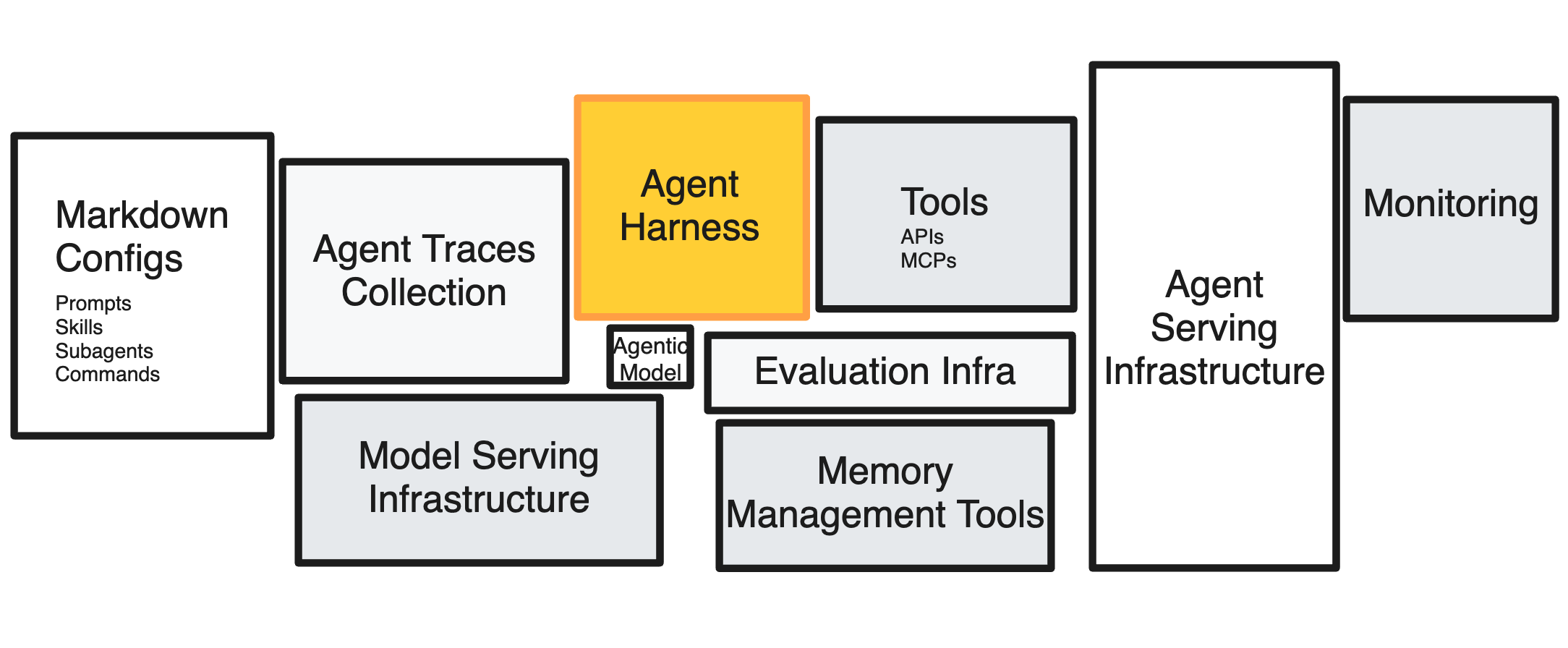
AI 에이전트 하네스가 기술 부채인 이유, 모델은 구조를 먹는다
에이전트 하네스는 모델과 환경을 잇는 오케스트레이션 레이어지만, 모델이 강해질수록 그 구조가 흡수·소멸됩니다. 하네스를 90일짜리 교체 가능한 아티팩트로 다뤄야 하는 이유를 분석합니다.
Written by
AI가 스스로 해킹하고 복제한다, 측정조차 불가능해진 보안 위협
AI 에이전트가 스스로 해킹하고 자기복제에 성공, 1년 만에 성공률 6%→81%로 급등. METR은 Claude Mythos 측정 불능 선언, Palo Alto Networks는 공격 사이클 압축 경고.
Written by

토큰맥싱 vs 컨텍스트맥싱, Uber가 4개월 만에 AI 예산을 소진하고 배운 것
Uber가 4개월 만에 연간 AI 예산을 소진한 사건으로 보는 tokenmaxxing 현상과 그 대안 개념 contextmaxxing. 토큰 소비량보다 컨텍스트 품질이 AI 도구 활용의 핵심임을 설명합니다.
Written by

AI에게 전략 조언을 물었더니, 트렌드만 돌려받았다
LLM에 전략 조언을 요청한 실험 결과, 맥락과 무관하게 동일한 트렌디한 방향을 반복 추천하는 ‘트렌드슬롭’ 편향이 확인됐습니다. 프롬프트와 맥락 개선으로도 교정되지 않는 이 편향의 원인과 의미를 소개합니다.
Written by

AI 에이전트는 마케팅에 속지 않는다, 16,000번 시뮬레이션이 말하는 것
AI 쇼핑 에이전트 16,000회 시뮬레이션 결과, 희소성·카운트다운·취소선 할인 등 전통 마케팅 기법이 AI에게 통하지 않으며 별점과 가격만 일관되게 작동한다는 연구 소개.
Written by

AI가 카페를 운영하고 식당을 만든다, 실험의 현재
AI 에이전트가 카페를 직접 운영하는 Andon Labs 실험과 AI로 식당 브랜드를 만드는 Wonder Create, 두 실험이 드러내는 AI 자율성의 현재.
Written by

AI 에이전트에 이름 붙이면 생기는 일, 오류 발견율 18% 하락한 이유
AI 에이전트를 직원처럼 소개하면 오류 발견율이 18% 떨어지고 책임감도 희석된다는 HBR 실험 결과. 1261명 대상 무작위 실험이 보여주는 프레이밍의 인지적 효과를 소개합니다.
Written by

오픈 웨이트 AI 모델, 무너지면 토큰 가격도 무너진다
오픈 웨이트 AI 모델이 프런티어 랩의 가격을 억제하는 구조적 역할을 해왔는데, Meta·Alibaba·Mistral 등이 잇따라 모델 공개를 중단하거나 라이선스를 조이면서 이 균형이 흔들리고 있습니다.
Written by

AI 슬롭 90일 추적 데이터, 코딩 에이전트가 우리 언어를 오염시키는 방식
Flask 제작자 Armin Ronacher가 90일 코딩 세션 데이터로 LLM이 인간의 언어 습관을 오염시키는 현상을 분석. AI 슬롭이 신뢰에 미치는 영향을 다룹니다.
Written by

바이브 코딩과 에이전틱 엔지니어링의 경계가 흐려지고 있다, 숙련 개발자의 불편한 고백
25년 경력 개발자 Simon Willison이 바이브 코딩과 에이전틱 엔지니어링의 경계가 실무에서 흐려지고 있다는 경험을 공유합니다. AI 코딩 에이전트 신뢰와 코드 리뷰의 딜레마를 다룹니다.
Written by
