AI 인사이트
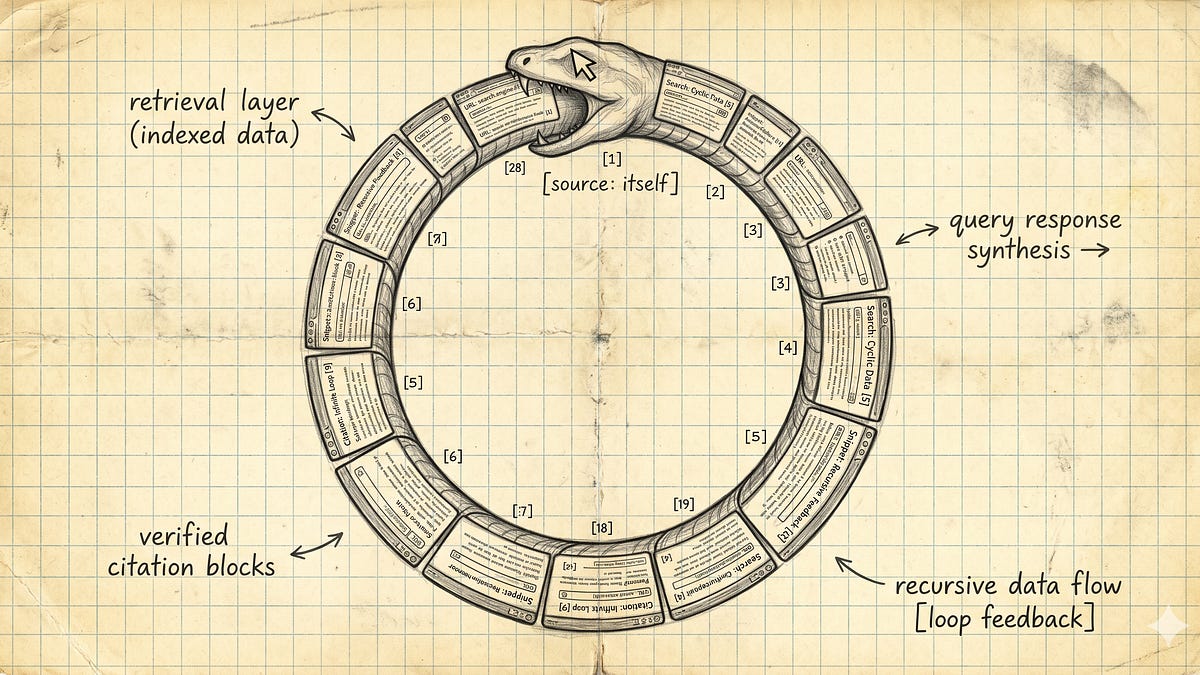
AI 검색은 지금 자기 환각을 인용하고 있다, 검색 오염의 실제 속도
AI 검색이 AI가 쓴 허위 콘텐츠를 실시간으로 인용하는 ‘검색 오염’ 현상 분석. 모델 재학습 없이도 크롤러 속도로 오염이 퍼지는 구조를 설명합니다.
Written by
AI가 정말 좋은 콘텐츠를 선택하는가, 실측 데이터로 확인한 결과
AI가 오리지널 콘텐츠를 실제로 더 잘 인용하는지 실측 데이터로 검증한 연구. 상관관계는 있지만 약하고, 쿼리 유형에 따라 달라집니다.
Written by

AI 모델이 자신 있을수록 더 위험하다, MIT가 찾아낸 과잉 확신의 구조적 원인
MIT CSAIL이 개발한 RLCR 훈련 방식. AI 추론 모델의 과잉 확신 문제를 훈련 구조 자체에서 해결하고, 교정 오류를 최대 90% 줄였습니다.
Written by

AI 검색에 내 글이 인용되는데, 아무도 내 이름을 모른다?
AI가 내 콘텐츠를 인용해도 브랜드명은 언급하지 않는 ‘유령 인용’ 현상. 3,981개 도메인 분석으로 밝혀진 AI 엔진별 인용·언급 패턴과 그 의미.
Written by

Dario Amodei vs Yann LeCun, AI 일자리 논쟁에서 누구 말을 믿어야 할까
Anthropic CEO 아모데이의 AI 일자리 소멸 경고에 야안 르쿤이 정면 반박. 두 AI 거장이 실은 서로 다른 질문에 답하고 있다는 인사이트를 담았습니다.
Written by

AI 쓸수록 뇌가 덜 쓰인다, MIT 연구가 밝힌 55% 뇌 활성화 감소
MIT 연구에서 ChatGPT 사용 시 뇌 활성화가 최대 55% 감소하는 것으로 나타났습니다. AI 사용 방식에 따라 인지 건강에 미치는 영향이 달라진다는 연구 결과를 소개합니다.
Written by
AI 모델, 복잡한 차트 앞에서 성능 절반 이상 추락, RealChart2Code 벤치마크 결과
RealChart2Code 벤치마크 연구 결과, 최상위 AI 모델도 복잡한 차트 앞에서 성능이 절반 이하로 떨어지는 ‘복잡도 갭’이 확인됐습니다.
Written by

퍼스널 AI가 바꾸는 서비스 구조, 헤드리스화가 시작됐다
AI 에이전트가 서비스를 대신 사용하는 시대, 모든 앱이 CLI·API 기반 헤드리스 구조로 전환해야 하는 이유를 Matt Webb의 분석으로 살펴봅니다.
Written by

ChatGPT는 직접 읽고, Gemini는 안 읽는다, nginx 로그로 본 AI 트래픽의 실체
AI 어시스턴트 8개를 nginx 탐침으로 실측한 결과. ChatGPT·Claude는 직접 읽고, Gemini는 읽지 않습니다. AI 트래픽의 두 신호를 구분하는 방법을 소개합니다.
Written by

AI를 열심히 쓰는데, 왜 점점 나 혼자서는 못 할 것 같지?
AI를 많이 쓸수록 혼자서는 더 못하게 된다는 두 연구의 핵심 발견. 문제는 AI가 아니라 어떻게 쓰느냐입니다.
Written by
