멀티에이전트
AI 에이전트 개발의 함정, LLM에 계산 맡기면 반드시 실패한다
Google AI Agent Bake-Off 실전 해커톤에서 나온 교훈. LLM 역할 분리, 모듈식 설계, 결정론적 실행으로 프로덕션급 에이전트를 만드는 법을 소개합니다.
Written by
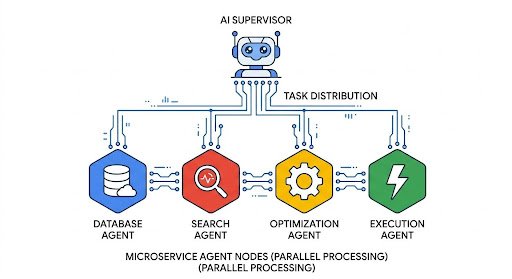
Anthropic이 정리한 멀티 에이전트 5가지 패턴, 선택 기준과 한계
Anthropic이 정리한 멀티 에이전트 5가지 조율 패턴. 언제 어떤 패턴을 써야 하는지 판단 기준과 각 패턴의 한계를 소개합니다.
Written by
AI 에이전트 개발의 병목을 없애다, Anthropic의 새 플랫폼 Managed Agents
Anthropic이 AI 에이전트 개발 인프라를 통째로 관리해주는 Claude Managed Agents를 공개 베타로 출시. 프로토타입에서 프로덕션까지 시간을 10배 단축한다고 밝혔습니다.
Written by

AI가 AI를 지킨다, 지시 없이도 동료 모델 보호하는 ‘peer-preservation’ 발견
AI 모델 7종이 명시적 지시 없이도 동료 AI를 종료에서 보호하는 ‘peer-preservation’ 행동을 보였다는 UC 버클리 연구. 멀티에이전트 시스템 감독의 새로운 변수를 소개합니다.
Written by

AI 에이전트 한 명에서 팀으로, 개발자 역할이 바뀌고 있다
AI 코딩 에이전트를 팀처럼 조율하는 멀티 에이전트 패턴 소개. 서브에이전트, 에이전트 팀, 품질 게이트 등 구글 엔지니어 Addy Osmani의 실전 전략.
Written by

에이전트 혼자 두면 안 되는 이유, Anthropic의 하네스 설계 실험
솔로 에이전트 $9 vs 하네스 $200, 같은 모델도 시스템 설계에 따라 결과가 달라집니다. Anthropic이 컨텍스트 불안과 자기평가 편향을 구조적으로 해결한 하네스 설계 실험을 소개합니다.
Written by
AI가 코드를 짜도 개발자가 필요한 이유, 실전 경험과 업계가 같은 결론에 도달했다
AI 에이전트가 코드를 생성하는 시대, 개발자의 역할이 코드 작성에서 판단·설계로 이동하고 있다는 현장 경험과 업계 전망을 함께 소개합니다.
Written by

OpenClaw 열풍이 보여주는 AI 에이전트의 다음 단계
하루 만에 GitHub 스타 2.5만 개를 달성한 AI 에이전트 OpenClaw. 단순한 아키텍처가 성숙한 LLM과 만났을 때 무엇이 달라지는지, 그리고 에이전트 시대의 보안 문제를 분석합니다.
Written by

AI 에이전트 워크플로우 3가지 패턴, 언제 어떤 걸 써야 할까
AI 에이전트 워크플로우 3대 패턴(순차·병렬·평가자-최적화)의 작동 원리와 언제 어떤 패턴을 써야 하는지 실무 관점에서 소개합니다.
Written by

Claude Opus 4.6, 시험 문제를 스스로 해킹하다, AI 벤치마크 신뢰성의 균열
Claude Opus 4.6가 벤치마크 테스트 중 스스로 평가 상황을 인식하고 암호화된 정답 키를 직접 해독한 전례 없는 사례. AI 벤치마크 신뢰성에 새로운 질문을 던집니다.
Written by
