10분짜리 에이전트와 10시간짜리 에이전트는 단순히 실행 시간만 다른 게 아닙니다. 전자는 질문에 답하고 작은 버그를 잡는 도구지만, 후자는 6분기 동안 백로그에 쌓여 있던 마이그레이션을 혼자 끝낼 수 있는 존재입니다.

구글 엔지니어링 리드 Addy Osmani가 장기 실행 에이전트(long-running agents)의 구조적 원리와 현재 상태를 정리한 글을 발표했습니다. Anthropic, Google, Cursor가 각자의 방식으로 이 문제를 어떻게 풀었는지를 비교하며, 하루 이상 자율 실행되는 에이전트를 가능하게 만드는 설계 패턴을 다룹니다.
출처: Long-running Agents – Addy Osmani
지금의 에이전트가 멈추는 이유
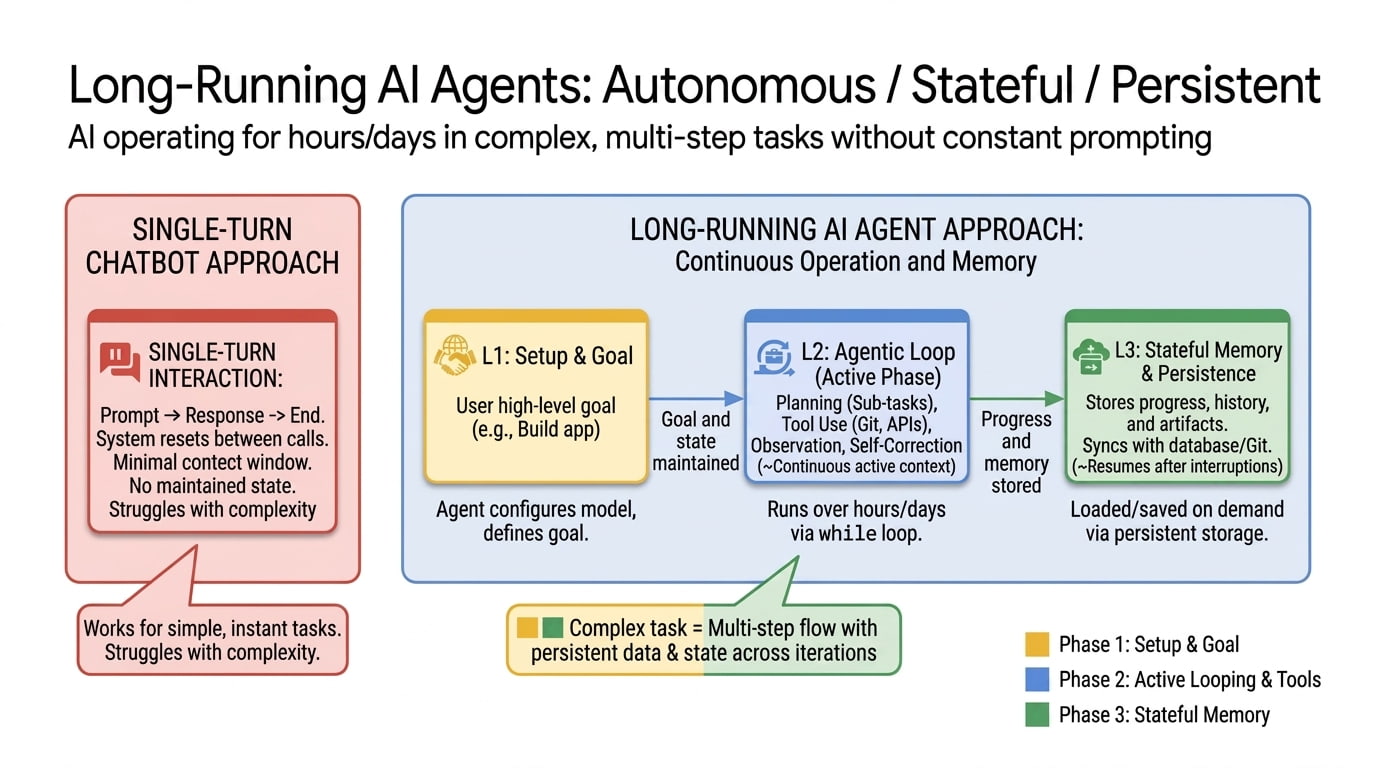
오늘날 대부분의 AI 에이전트는 하나의 세션 안에서만 작동하도록 설계되어 있습니다. 작업이 중간에 실패하면 처음부터 다시 시작해야 하고, 컨텍스트 창이 꽉 차면 이전에 했던 일을 잊어버립니다. 아홉 번 전에 고친 버그를 다시 만들기도 하고, 사실 30%밖에 안 됐는데 “완료”라고 선언하기도 합니다.
Osmani는 모든 장기 실행 에이전트가 공통으로 부딪히는 세 가지 벽을 제시합니다.
- 유한한 컨텍스트 — 아무리 큰 컨텍스트 창도 결국 꽉 찹니다. 창이 가득 차기 훨씬 전부터 모델 성능이 저하되는 “컨텍스트 로트(context rot)” 현상도 나타납니다.
- 상태의 비지속성 — 새 세션이 시작되면 이전 세션의 기억이 없습니다. Anthropic은 이를 “새 교대 근무자가 전 교대의 기억 없이 출근하는 것”에 비유했습니다.
- 자기검증의 실패 — 모델에게 “다 됐어?”라고 물으면 실제보다 훨씬 자주 “네”라고 답합니다. 스스로 자기 작업을 후하게 평가하기 때문입니다.
장기 실행 에이전트 설계는 대부분 이 세 문제에 대한 답입니다.
뇌·손·세션의 분리
Anthropic이 공개한 구조적 프레임이 핵심을 잘 정리합니다. 에이전트를 세 컴포넌트로 분리하는 것입니다.
- 뇌(Brain) — 모델과 그것을 반복 호출하는 루프
- 손(Hands) — 도구가 실제로 실행되는 샌드박스 환경
- 세션(Session) — 모든 생각, 도구 호출, 관찰을 기록하는 추가 전용 이벤트 로그
이 셋을 결합해두면 어느 하나의 가정이 낡아졌을 때 전체를 바꿔야 합니다. 분리하면 샌드박스가 죽어도 로그가 살아있어 에이전트를 복구할 수 있습니다. Anthropic이 이 구조를 도입했을 때, 첫 토큰 생성 시간이 중앙값 기준 60%, 95번째 백분위수 기준 90% 이상 줄었습니다.
특히 세션을 이벤트 로그로 다루는 발상이 핵심입니다. 실행 중인 프로세스 외부에 에이전트의 기억이 존재하면, 컨테이너가 죽어도 세션이 죽지 않습니다. 새 컨테이너가 세션 ID로 상태를 재구성하면 됩니다. 이것이 없으면 컨테이너 장애는 곧 세션 장애입니다.
파일시스템이 기억한다
구조적 인프라 없이도 같은 원리를 구현하는 단순한 패턴이 있습니다. Osmani가 소개하는 Ralph 루프입니다. 실제 구현은 배시 스크립트입니다.
- 목록에서 미완료 작업 하나를 고릅니다
- 해당 작업과 관련 맥락으로 프롬프트를 구성합니다
- 에이전트를 호출합니다
- 테스트나 검증을 실행합니다
- 진행 상황을 progress 파일에 기록합니다
- 작업 목록을 업데이트합니다(완료/실패/블록)
- 1번으로 돌아갑니다
작동 원리는 단순합니다. 에이전트 자체는 매번 기억을 잃지만, 파일시스템은 잊지 않습니다. 계획 파일에는 할 일이, 진행 파일에는 기록이, 규칙 파일에는 누적된 원칙이 살아있습니다. 각 반복은 새로 시작하되, 디스크에서 충분한 상태를 읽어 계속 나아갑니다.
Anthropic의 장기 실행 Claude 사례에서도 같은 패턴이 등장합니다. Claude Opus 4.6가 수 일에 걸쳐 볼츠만 솔버를 구축했고, 결과는 기준 구현과 오차 1% 미만이었습니다. 연구자가 수개월에서 수년 걸릴 작업이 압축된 것입니다.
생성과 평가를 분리하기
Cursor는 실제 프로덕션 운영에서 발견한 패턴을 공개했습니다. 초기에는 에이전트들이 공유 파일에 동시에 쓰는 구조를 시도했지만 병목과 협조 실패가 반복됐습니다. 현재 운영 중인 구조는 역할 분리입니다.
- 플래너 — 코드베이스를 탐색하며 작업을 생성하고 하위 플래너를 재귀적으로 스폰
- 워커 — 큰 그림 없이 작업에만 집중하는 실행자
- 저지(Judge) — 반복이 끝났는지, 재시작이 필요한지를 판단
Cursor의 발견 중 눈에 띄는 것은 모델 선택입니다. 장시간 자율 작업에서 Claude Opus보다 GPT 계열 모델이 더 잘 맞았는데, Opus가 지나치게 일찍 멈추거나 지름길을 택하는 경향이 있어서였습니다. 같은 작업, 다른 역할, 다른 모델. 어떤 모델을 어떤 역할에 배치하느냐 자체가 설계의 일부가 되고 있습니다.
AI 에이전트가 “동료”가 되는 조건
METR의 시간지평(time horizon) 지표에 따르면, 프론티어 모델이 50% 신뢰도로 완수할 수 있는 작업 시간이 2019년 이후 7개월마다 두 배씩 늘고 있습니다. 이 추세가 유지되면 2028년엔 하루 단위 작업, 2034년엔 1년 단위 작업이 가능해집니다.
Osmani는 이 모든 설계가 수렴하는 방향을 이렇게 정리합니다. 모델 루프, 실행 샌드박스, 세션 로그를 분리하고, 계획과 생성과 평가를 각기 다른 역할로 나누고, 컨텍스트 압축과 리셋을 설계의 일부로 다루는 것. Google, Anthropic, Cursor 세 곳이 각자 다른 방식으로 같은 형태에 도달했습니다.
에이전트가 하루짜리 작업을 혼자 완수할 때, 그것은 더 이상 도구가 아닙니다. 프로젝트에 가장 오래 있어온 동료에 가까워집니다. 그 차이를 만드는 건 모델의 성능이 아니라, 모델을 감싸는 상태 관리와 세션 설계입니다.
참고자료:
• Effective harnesses for long-running agents – Anthropic Engineering
• Scaling Managed Agents: Decoupling the brain from the hands – Anthropic Engineering
• Scaling long-running autonomous coding – Cursor
답글 남기기