AI코딩
엔지니어 99%가 매일 AI를 쓰는 회사에서 벌어진 일, 스포티파이가 본 진짜 병목
엔지니어 99%가 AI 코딩 도구를 쓰는 스포티파이에서 병목이 코딩에서 의사결정으로 옮겨간 이야기. 백그라운드 에이전트 Honk와 ‘에이전트를 위한 개발자 경험’을 소개합니다.
Written by

확장을 많이 깔수록 AI 에이전트가 더 멍청해진다, MS가 측정한 구성 비용
AI 코딩 에이전트에 확장을 많이 설치할수록 성능이 떨어지는 ‘구성 비용’ 현상. 컨텍스트 윈도우 경쟁과 확장 충돌을 측정한 마이크로소프트의 분석을 소개합니다.
Written by

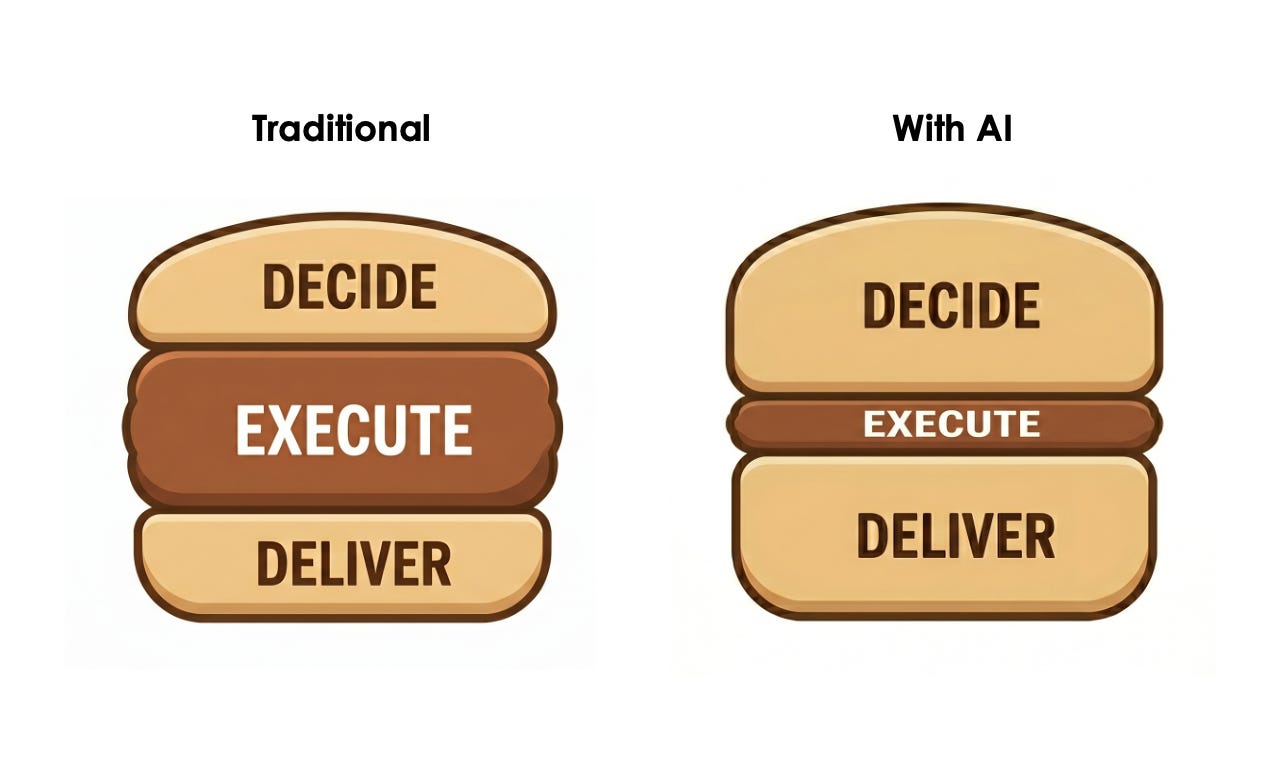
AI 코딩 시대, 소프트웨어 엔지니어 고용은 왜 줄지 않는가
AI가 코드의 80%를 써도 소프트웨어 엔지니어 고용이 줄지 않는 이유. Block·Snap 구조조정의 실체와 decide-execute-deliver 샌드위치 모델로 분석합니다.
Written by
구글 코드 75%가 AI 생성인 시대, 개발자의 가치는 어디서 오는가
구글 코드 75%가 AI 생성인 시대, 개발자의 진짜 가치는 어디서 오는가. Stack Overflow가 분석한 ‘장인 개발자’의 의미를 소개합니다.
Written by
Claude Code 스킬 9가지 분류, Anthropic이 내부에서 직접 쓰는 방식
Anthropic Claude Code 팀이 공개한 내부 스킬 9가지 분류 체계와 품질 높은 스킬을 만드는 원칙. 실무 개발자를 위한 AI 도구 활용 인사이트를 소개합니다.
Written by

AI 없이는 못 일한다는 개발자들, 그 코드의 청구서는 누가 받나
AI 코딩 도구 없이 일하길 거부하는 개발자들, 하지만 AI 생성 코드의 버그와 유지보수 비용은 쌓이고 있습니다. METR 연구와 아마존·우버 사례로 본 AI 코딩의 역설.
Written by

AI 코드 기여, 메인테이너 눈엔 어떻게 보일까, Pi 개발 90일의 기록
AI 코딩 도구로 오픈소스 기여가 쉬워진 시대, 메인테이너는 오히려 더 힘들어졌습니다. Pi 개발 90일 데이터로 본 AI 생성 이슈·PR의 현실.
Written by

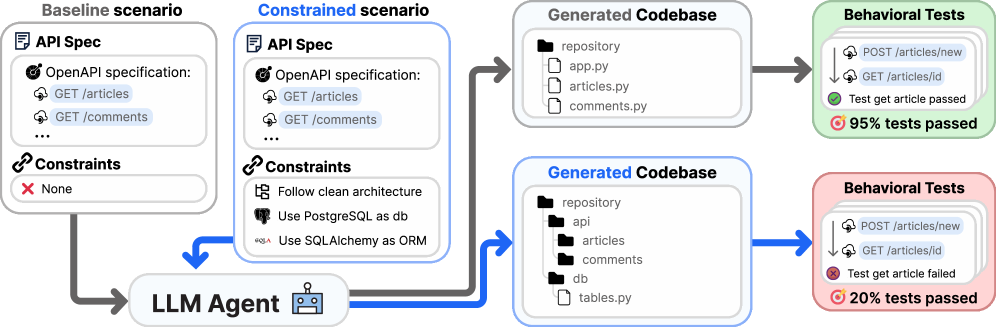
코딩 에이전트, 논문으로 확인된 구조적 한계
코딩 에이전트는 구조적 제약이 쌓일수록 성능이 급격히 떨어집니다. George Hotz의 6개월 실험과 Constraint Decay 논문이 말하는 에이전트의 실제 한계.
Written by
AI가 결과를 주는 사이, 우리 안의 무언가가 사라지고 있다
AI 코딩 도구와 LLM이 개발자의 내면적 경험과 학습자의 사고 과정을 어떻게 바꾸고 있는지, 두 개발자·학생의 시선으로 들여다봅니다.
Written by

Anthropic, 창사 이래 첫 흑자 전망, 분기 매출 10.9조 원 돌파한 이유
Anthropic이 2026년 2분기 창사 이래 첫 영업이익을 전망합니다. AI 코딩 도구와 에이전틱 AI가 폭발적 성장을 이끈 구조를 분석합니다.
Written by
