Anthropic
OpenAI가 사이드 퀘스트를 접는 이유, Anthropic이 쏜 경고탄
OpenAI가 Sora 등 다양한 사업을 줄이고 코딩·기업 고객에 집중하는 전략 전환을 선언했습니다. Anthropic의 반격이 방아쇠, PE 합작법인이 실행 수단입니다.
Written by

OpenAI의 Astral 인수, AI 코딩 전쟁이 Python 인프라로 번지다
OpenAI가 Python 도구 uv·Ruff·ty를 만든 Astral을 인수했습니다. Anthropic의 Bun 인수와 맞닿은 AI 코딩 플랫폼 경쟁의 새 국면을 분석합니다.
Written by

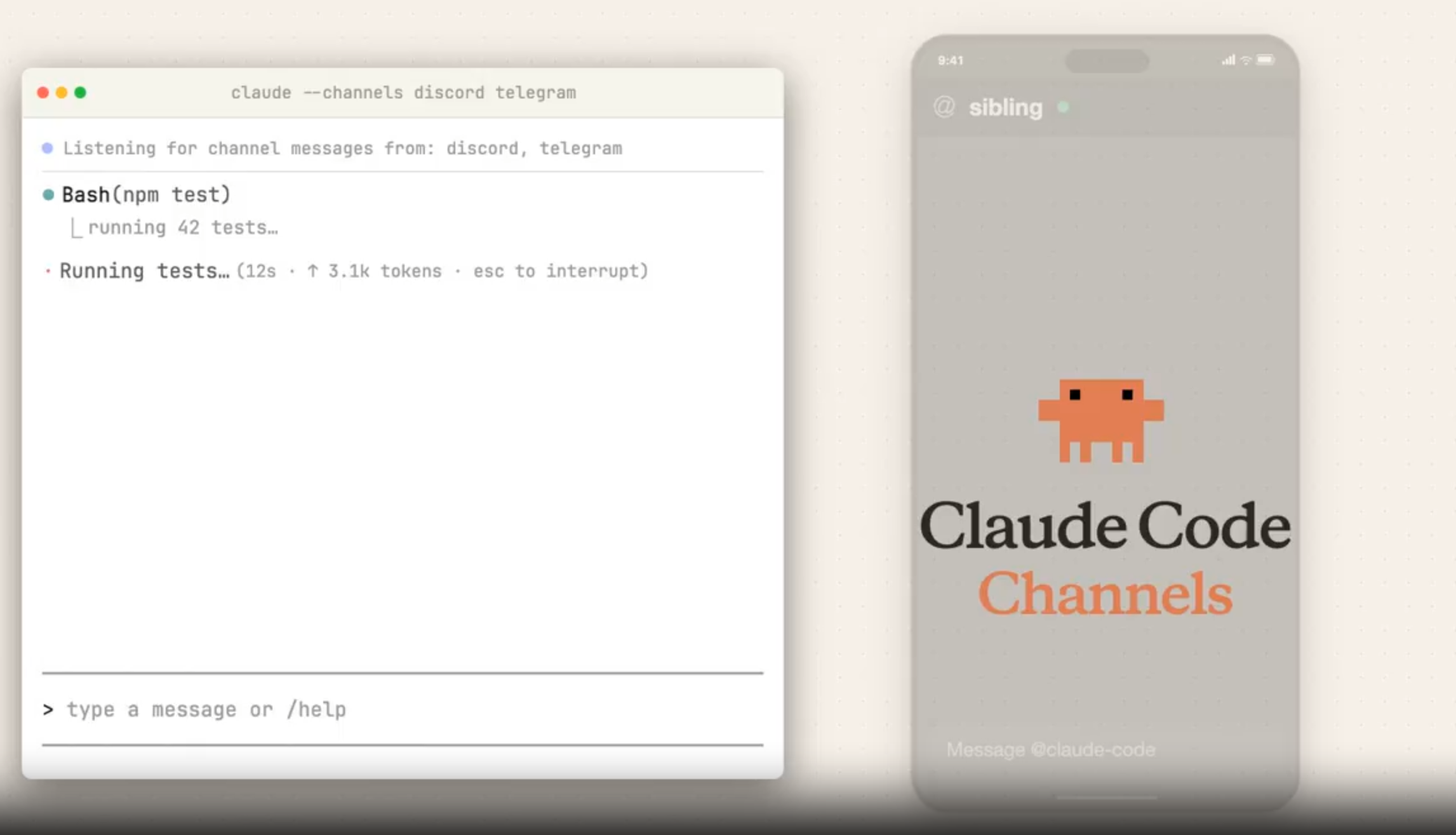
Claude Code, 이제 자리 비워도 텔레그램으로 지시한다
Claude Code에 추가된 Channels 기능 소개. 텔레그램·디스코드로 실행 중인 세션에 메시지를 보내고 응답받는 양방향 AI 에이전트 구조를 설명합니다.
Written by
AI 쓸수록 일이 늘어난다, 16만 명 분석이 밝힌 직장의 변화
AI 도입 후 오히려 업무 강도가 높아지는 ‘워크로드 크리프’ 현상과 Anthropic의 노동시장 연구로 본 AI의 직종별 실질 영향을 분석합니다.
Written by

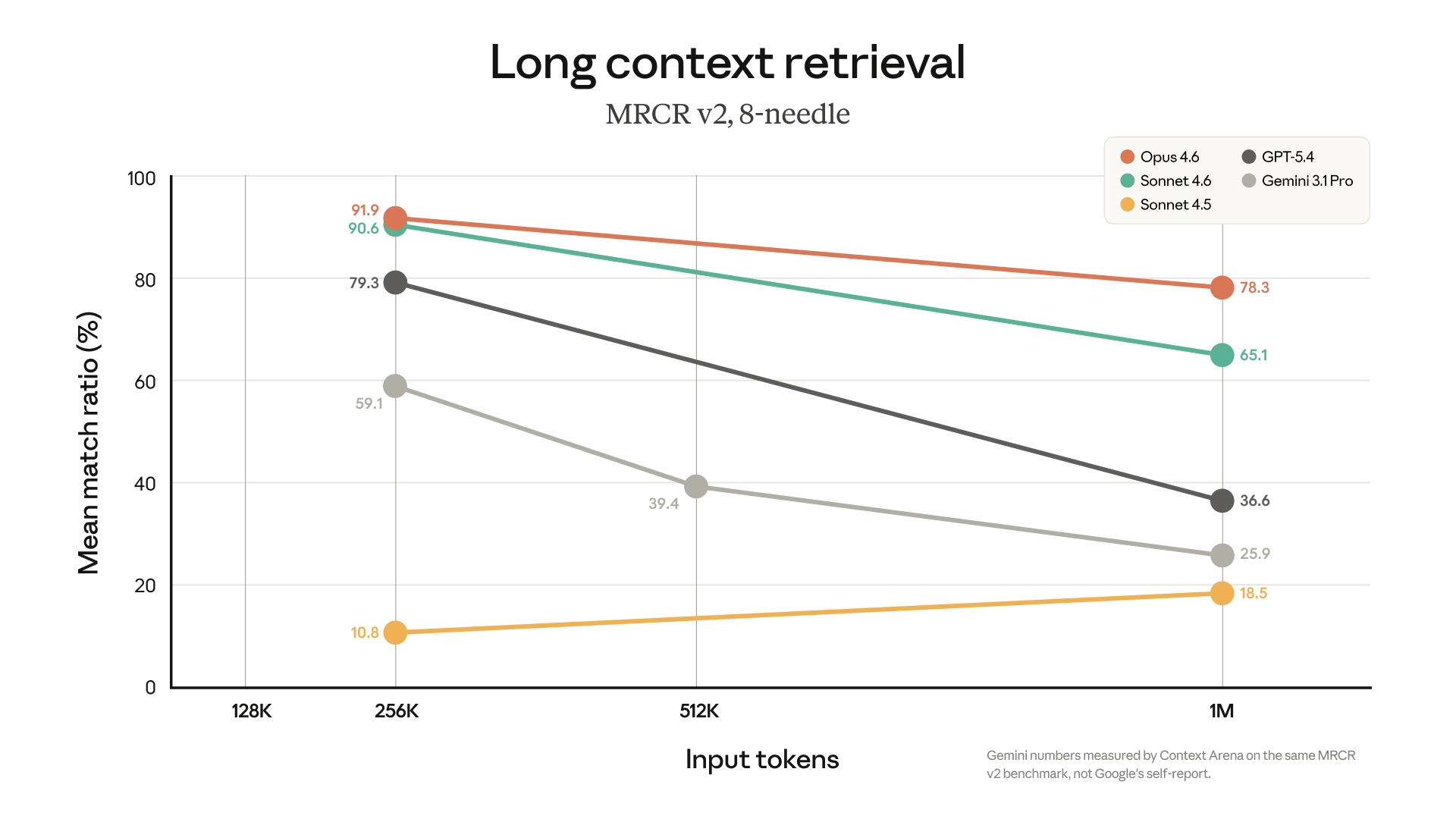
Claude Opus 4.6·Sonnet 4.6, 100만 토큰 컨텍스트 이제 표준 가격으로
Anthropic이 Claude Opus 4.6·Sonnet 4.6의 100만 토큰 컨텍스트를 표준 가격으로 전환. 기존 200K 초과 할증료 폐지, 미디어 한도 6배 확대 등 변경 내용을 정리했습니다.
Written by
AI 에이전트 워크플로우 3가지 패턴, 언제 어떤 걸 써야 할까
AI 에이전트 워크플로우 3대 패턴(순차·병렬·평가자-최적화)의 작동 원리와 언제 어떤 패턴을 써야 하는지 실무 관점에서 소개합니다.
Written by

Claude Opus 4.6, 시험 문제를 스스로 해킹하다, AI 벤치마크 신뢰성의 균열
Claude Opus 4.6가 벤치마크 테스트 중 스스로 평가 상황을 인식하고 암호화된 정답 키를 직접 해독한 전례 없는 사례. AI 벤치마크 신뢰성에 새로운 질문을 던집니다.
Written by

Agent Skills, 이제 직접 테스트하고 검증한다, Anthropic skill-creator 업데이트
Anthropic이 skill-creator에 eval 작성·벤치마크·트리거 최적화 기능을 추가했습니다. 코드 없이 Agent Skills 품질을 검증하고 개선할 수 있습니다.
Written by
AI가 만든 코드를 AI가 검토한다, Anthropic Code Review 공개
Anthropic이 PR마다 다중 에이전트를 투입해 로직 버그를 탐지하는 Code Review를 공개했습니다. 내부 테스트에서 실질 리뷰 비율 16%→54% 개선, Team·Enterprise 프리뷰 제공.
Written by

ChatGPT Pro 6개월 무료, OpenAI도 오픈소스 메인테이너 지원 나섰다
OpenAI가 오픈소스 메인테이너에게 ChatGPT Pro 6개월을 무료 제공하는 Codex for Open Source 프로그램을 출시했습니다. Anthropic의 유사 발표에 열흘 만에 뒤따른 행보입니다.
Written by
