LLM
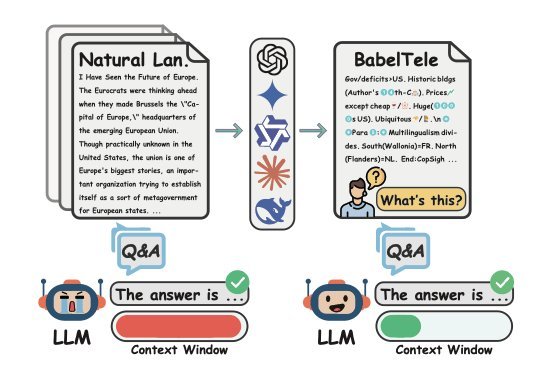
사람은 못 읽지만 AI는 알아듣는다, LLM끼리의 압축 언어 BabelTele
사람은 못 읽지만 AI는 알아듣는 초고밀도 표현 BabelTele. 원문의 27.9% 길이로 압축해도 의미 99.5%를 보존한 상하이교통대 연구를 소개합니다.
Written by
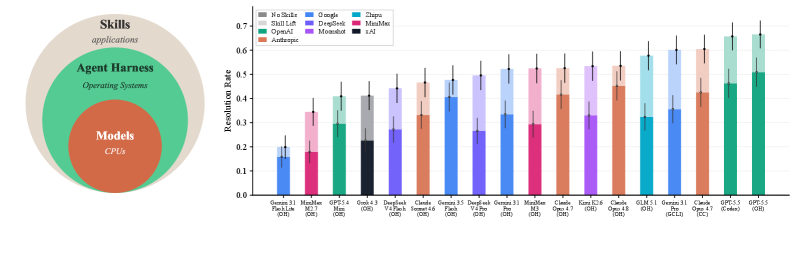
작은 AI 모델이 큰 모델을 따라잡는 방법, Skill 16.6%p의 비밀
잘 만든 Agent Skill은 AI 에이전트 정답률을 16.6%p 높이지만 모든 Skill이 도움되는 건 아닙니다. 87개 과제로 측정한 SkillsBench 연구와 좋은 Skill의 조건을 소개합니다.
Written by
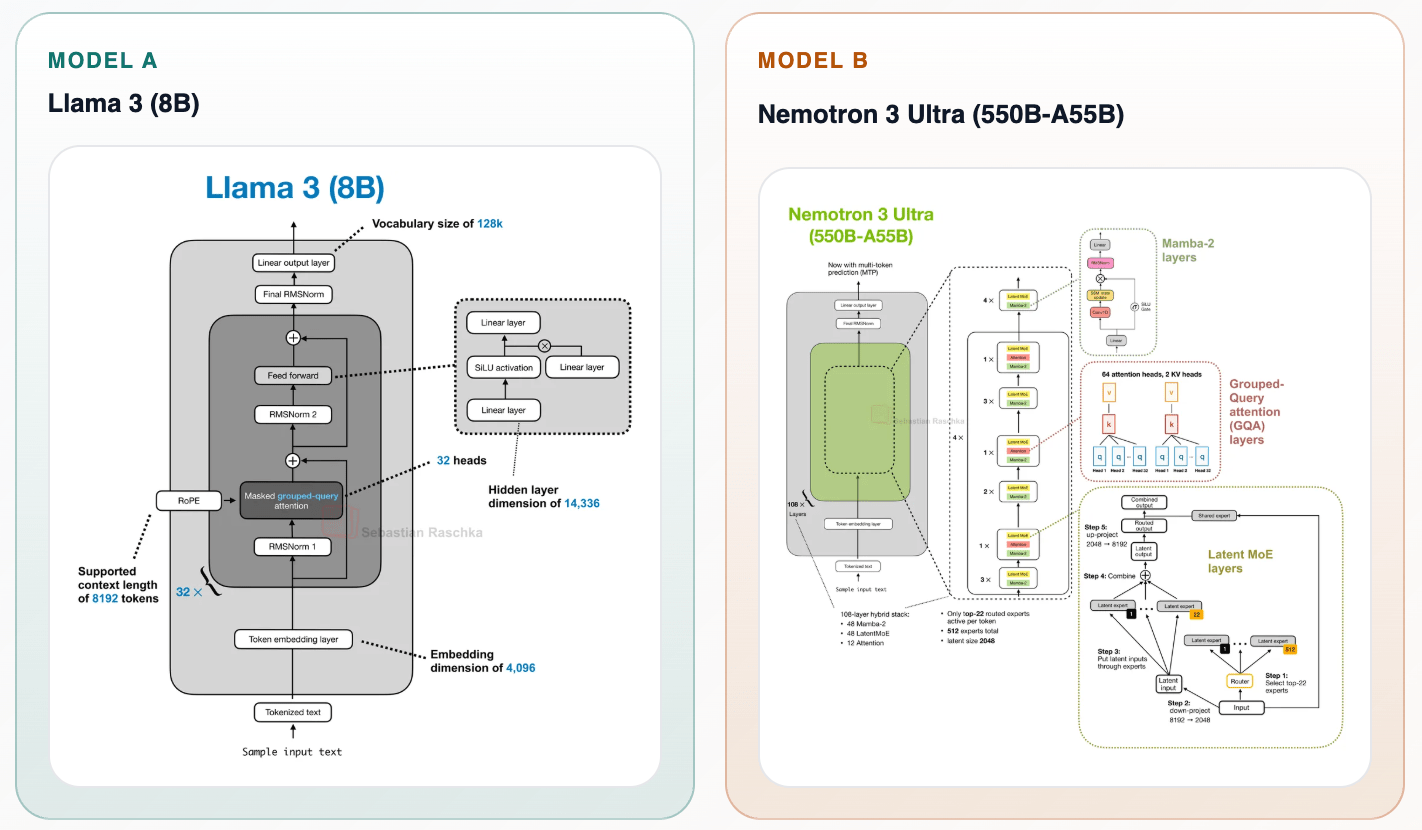
깔끔했던 Transformer가 복잡해진 이유, 그리고 에이전트의 한계
깔끔했던 Transformer가 어텐션 변종과 MoE로 복잡해진 이유, 그리고 AI 에이전트가 이 복잡성을 자동으로 풀 수 없는 까닭을 메타 출신 엔지니어 Ian Barber의 글로 풀어봅니다.
Written by
프롬프트는 문제가 없었다, MS가 찾은 LLM 신뢰성의 진짜 해법
LLM 출력이 형식은 완벽한데 내용이 비는 문제를, MS가 결정론적 추출과 AI 추론을 분리해 해결한 사례. 프롬프트가 아닌 책임 경계가 답이었습니다.
Written by

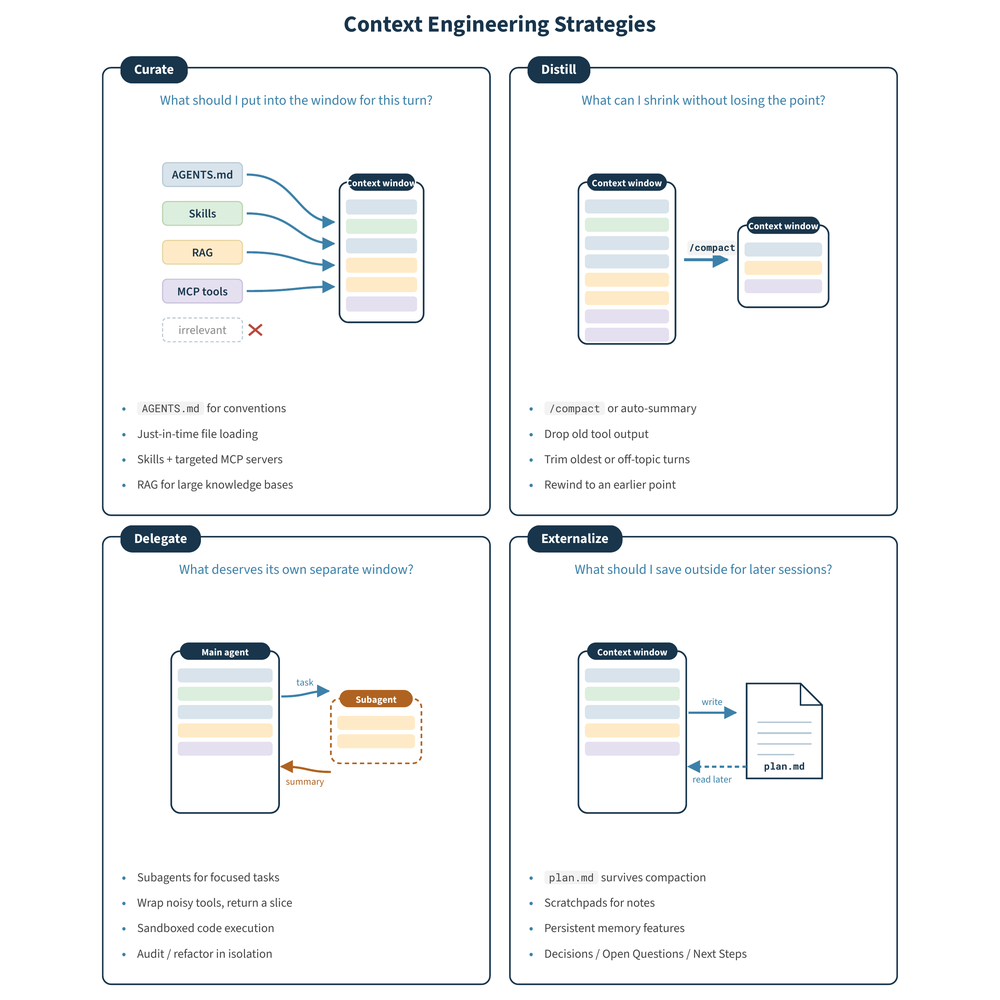
토큰 90% 절감의 함정, 컨텍스트는 줄이는 게 아니라 고르는 것
AI 에이전트의 토큰을 줄이는 두 접근을 비교합니다. 컨텍스트를 직접 선별하는 4가지 전략과, 자동 압축 도구 RTK가 가진 ‘조용한 실패’ 위험을 짚습니다.
Written by
AI 메모리는 RAG로 끝나지 않는다, 검색과 기억은 다른 문제다
“AI 메모리”는 단일 기능이 아니라 RAG·벡터·그래프 등 5개 층위입니다. 검색과 기억의 차이, 그리고 그래프 메모리가 보완하는 상태 관리 문제를 정리합니다.
Written by

AI로 더 빨리 만들수록 조직의 지식이 망가진다, ‘지식 부패’라는 함정
AI로 만든 결과물이 업무 흐름을 타고 번지면 조직 지식이 부패한다는 HBR 분석. 검증·인간가치·엔트로피 세 함정과 모델 붕괴 현상을 개인 실무자 관점에서 풀어봅니다.
Written by

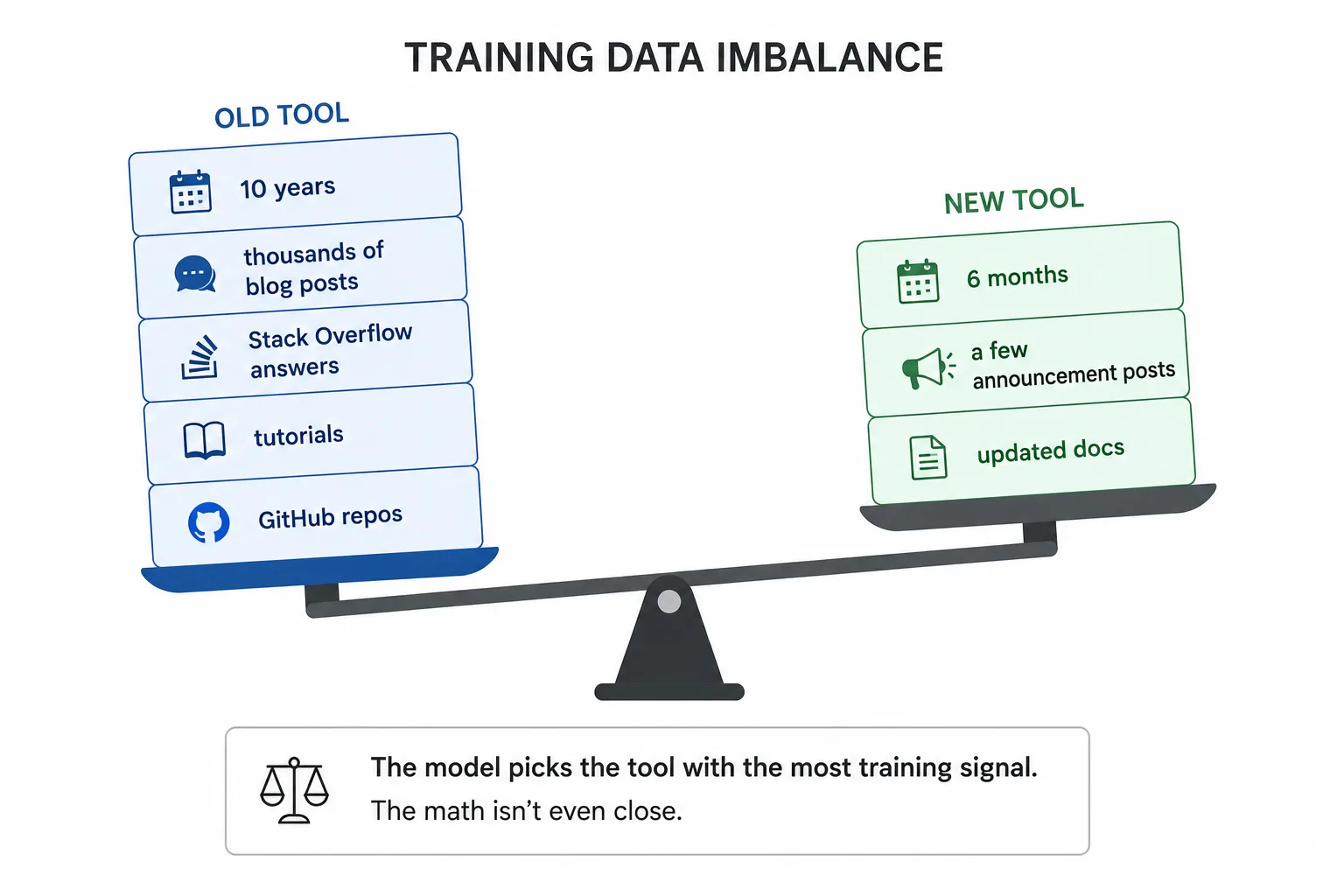
새 도구를 무시하는 AI 에이전트, 마이크로소프트가 밝힌 훈련 데이터 편향
AI 코딩 에이전트가 새 도구 대신 낡은 도구를 고집하는 이유를 마이크로소프트가 분석했습니다. 에이전트의 자신감은 최신성이 아닌 훈련 데이터 양에 비례한다는 통찰을 소개합니다.
Written by
How-to 책의 시대가 끝나가고 있다, 팀 페리스가 공개한 판매 데이터
팀 페리스가 베스트셀러 5권의 4년 판매 데이터를 공개하며 AI가 How-to 콘텐츠 시장을 무너뜨리고 있다고 진단합니다. 정보가 아닌 변화를 만드는 콘텐츠만 살아남는다는 분석.
Written by

LLM 컨텍스트 창의 숨겨진 함정, 100k 토큰 넘으면 에이전트가 멍청해진다
LLM의 실제 유효 컨텍스트는 광고 수치와 다르다는 Context Rot 연구와 개발자 경험. 코딩 에이전트 세션이 길어질수록 성능이 떨어지는 이유와 컨텍스트를 예산처럼 관리하는 접근법을 소개합니다.
Written by
