LLM
AI 튜터가 법학 교수를 이겼다, 스탠퍼드 연구가 확인한 75% 우위
스탠퍼드 로스쿨 연구에서 AI 답변이 법학 교수 답변을 75%의 대결에서 앞섰습니다. 정답이 없는 판단 영역에서도 AI가 전문가 수준에 도달했다는 첫 엄밀한 증거를 소개합니다.
Written by

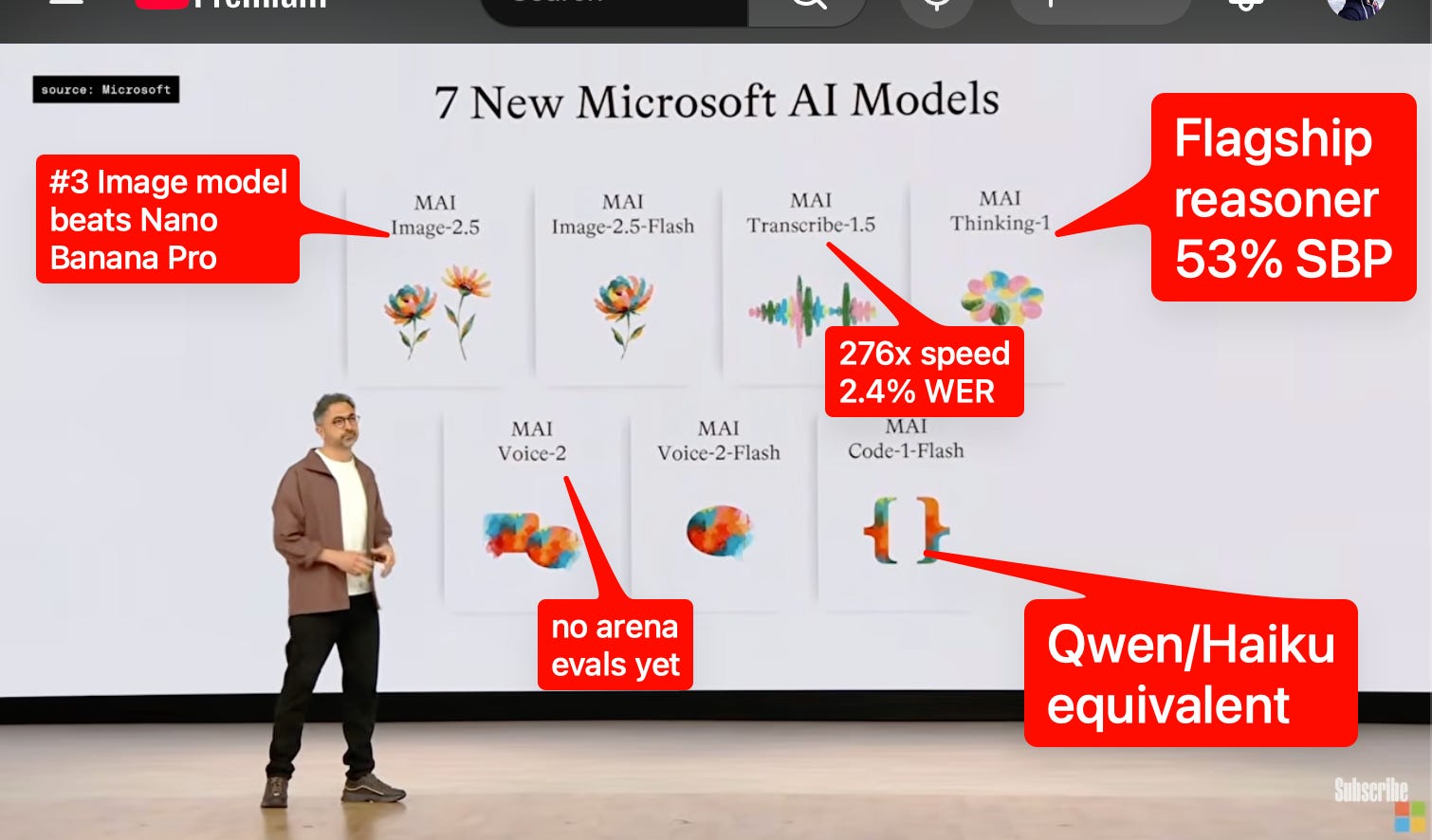
Microsoft MAI-Thinking-1, 증류 없이 만든 35B 추론 모델이 던지는 질문
Microsoft가 Build 2026에서 공개한 첫 자체 추론 모델 MAI-Thinking-1. 타사 증류 없이 35B 활성 파라미터로 대형 모델과 경쟁하는 MoE 구조와 그 의미를 소개합니다.
Written by
Supermemory Dynamic Dreaming, AI 에이전트 기억이 스스로 재정비하는 방법
Supermemory가 출시한 Dynamic Dreaming은 AI 에이전트 메모리가 유휴 시간에 스스로 기억을 재검토·통합하는 기능입니다. 기존 정적 메모리 구조의 한계와 작동 원리를 소개합니다.
Written by

긴 대화일수록 AI는 더 많이 잊는다, Context Compaction 이해하기
AI가 긴 대화에서 이전 내용을 조용히 잊는 컨텍스트 컴팩션 현상을 설명하고, 중요 정보를 보존하는 3가지 실용 원칙을 소개합니다.
Written by

Opus 4.7보다 4배 솔직해진 Claude Opus 4.8, 달라진 점 정리
Anthropic의 Claude Opus 4.8 출시 정리. 정직성 4배 개선, 동적 워크플로, Effort Control 등 핵심 변화를 소개합니다.
Written by

코딩 에이전트, 논문으로 확인된 구조적 한계
코딩 에이전트는 구조적 제약이 쌓일수록 성능이 급격히 떨어집니다. George Hotz의 6개월 실험과 Constraint Decay 논문이 말하는 에이전트의 실제 한계.
Written by
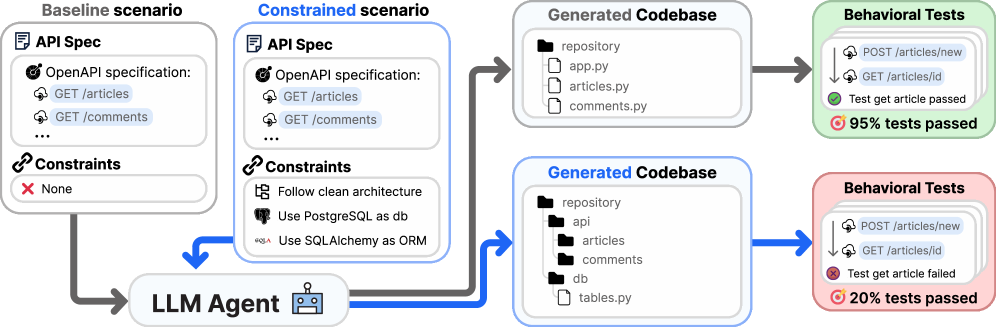
모델 고르는 시대는 끝났다, 에이전트 하네스가 성능을 가른다
모든 주요 AI 모델 회사들이 에이전트 개발로 피벗하는 흐름과, 모델 선택보다 하네스 설계가 성능을 좌우한다는 Stanford 연구 소개.
Written by
AI 코딩 도구 도입 후 생산성이 올랐다고? 측정이 틀렸을 수 있습니다
AI 코딩 도구 도입 후 생산성이 올랐다는 측정, 정말 믿을 수 있을까요? 코드 줄 수·설문·커밋 수 등 흔한 측정 방식의 구조적 오류를 연구 문헌으로 짚어봅니다.
Written by

코드가 에이전트의 ‘뼈대’가 됐다, Code as Agent Harness 논문 읽기
코드가 AI 에이전트의 결과물이 아닌 운영 인프라가 된다는 ‘Code as Agent Harness’ 논문 소개. UIUC·Meta·Stanford 공동 연구, 하네스 3레이어 구조를 쉽게 정리했습니다.
Written by

프롬프트도 기술 부채다, 정교하게 설정할수록 더 위험한 이유
정교한 프롬프트 설정이 오히려 독이 될 수 있다는 GitHub 엔지니어의 주장. 모델이 바뀔 때마다 조용히 무력화되는 프롬프트 부채의 위험성을 다룹니다.
Written by
