LLM
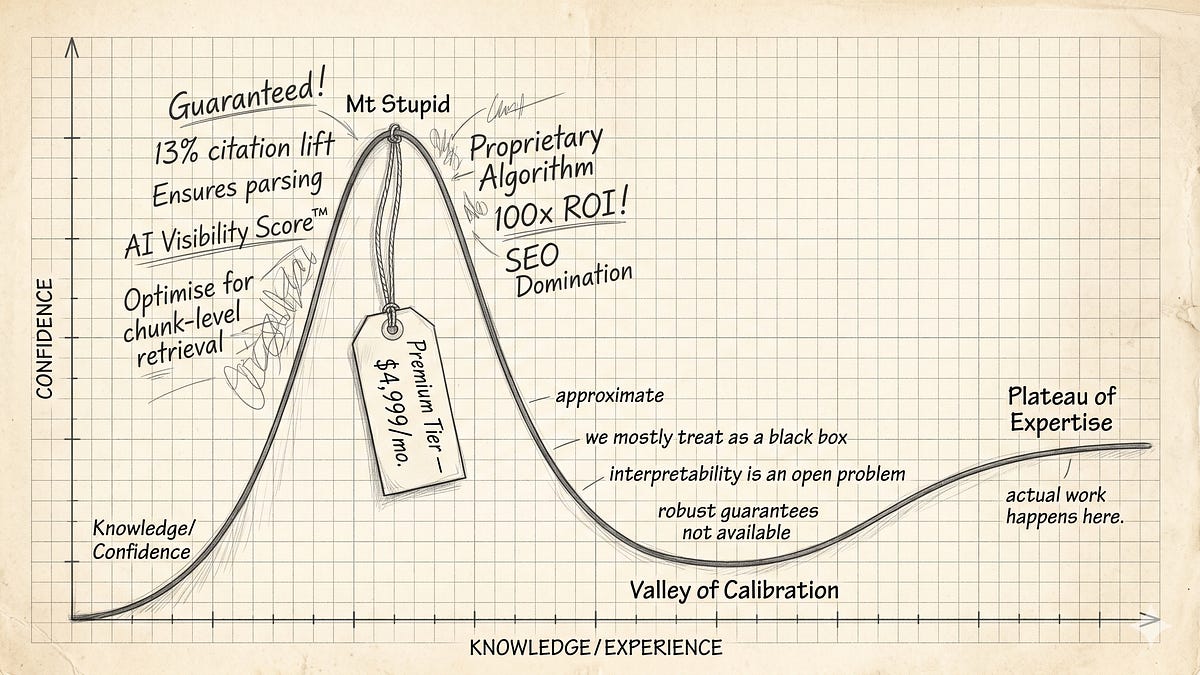
AI 검색 최적화 처방이 틀렸다, Ahrefs 실험이 밝힌 결과
Ahrefs 실험에서 스키마 마크업이 AI 인용률에 거의 영향 없음이 밝혀졌습니다. Google 공식 문서도 GEO 플레이북을 부정한 배경과 이유를 분석합니다.
Written by
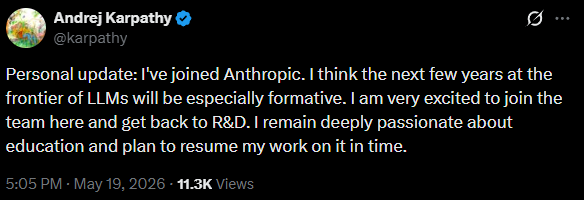
Andrej Karpathy, Anthropic 합류, AI가 AI를 훈련하는 팀 이끈다
OpenAI 공동 창업자 Andrej Karpathy가 Anthropic에 합류해 Claude를 활용한 프리트레이닝 가속 팀을 이끕니다. AI 인재 경쟁의 새로운 분수령을 소개합니다.
Written by
AI가 AI를 만드는 시대, 재귀적 자기개선은 어디까지 왔나
AI가 스스로를 개선하는 재귀적 자기개선(RSI)이 실제로 어디까지 왔는지, OpenAI·Anthropic·DeepMind 최신 사례와 한계, 미래 전망을 소개합니다.
Written by

할루시네이션 인용 논문 올리면 1년 퇴출, arXiv의 AI 슬롭 대응책
arXiv가 AI 생성 할루시네이션이 포함된 논문 제출자에게 1년 제출 금지 페널티를 부과합니다. 학술 생태계가 AI 슬롭에 대응하는 방식을 소개합니다.
Written by

컨텍스트 관리, AI 개발에서 가장 중요한데 아무도 안 가르쳐주는 기술
AI 코딩 세션에서 컨텍스트가 손실될 때 어떤 문제가 생기는지, 왜 세션 재시작이 오히려 나쁜지를 설명하는 O’Reilly 글 큐레이션. 가비지 컬렉션 비유로 개념을 명확히 전달합니다.
Written by

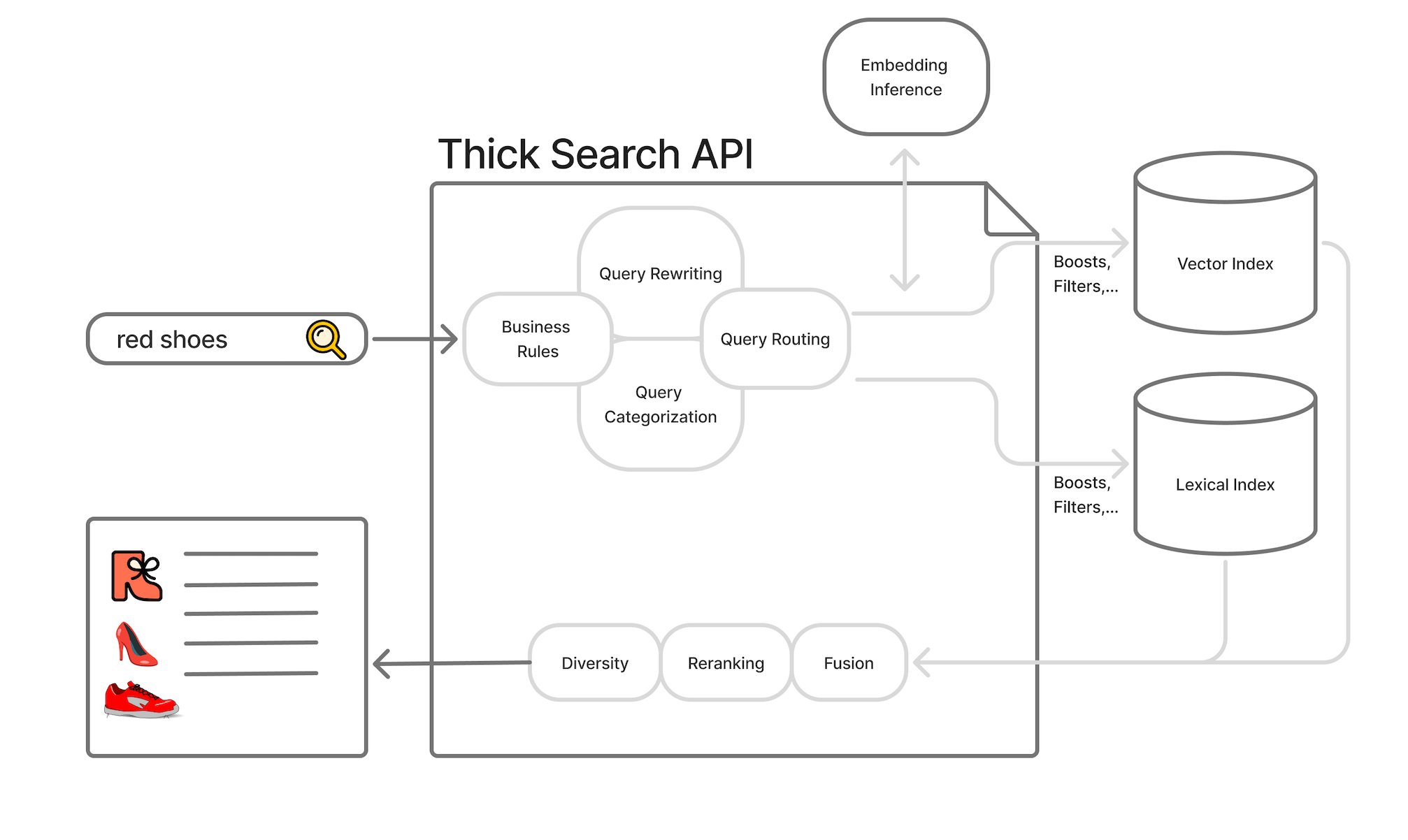
GPT-5도 모르는 마지막 20%, 도메인 특화 검색 에이전트의 등장
기존 검색 스택의 한계와 에이전트 기반 검색으로의 전환을 소개합니다. GPT-5가 채우지 못하는 도메인 특수성과, 이를 해결할 특화 소형 모델의 등장을 정리했습니다.
Written by
AI가 잘 못하는 일과 잘 하는 일, 2×2 매트릭스로 구분하는 법
AI가 실패하는 이유는 모델이 아닌 작업 단위 때문입니다. 반복성과 출력 구조로 AI 활용 우선순위를 정하는 2×2 프레임워크를 소개합니다.
Written by

AI 추론이 둘로 나뉜다, Answer와 Agentic의 차이가 하드웨어를 바꾼다
AI 추론이 Answer와 Agentic으로 나뉘면서 GPU 중심 하드웨어 구조가 흔들리고 있습니다. Stratechery Ben Thompson의 분석을 소개합니다.
Written by

오픈 웨이트 AI 모델, 무너지면 토큰 가격도 무너진다
오픈 웨이트 AI 모델이 프런티어 랩의 가격을 억제하는 구조적 역할을 해왔는데, Meta·Alibaba·Mistral 등이 잇따라 모델 공개를 중단하거나 라이선스를 조이면서 이 균형이 흔들리고 있습니다.
Written by

AI 슬롭 90일 추적 데이터, 코딩 에이전트가 우리 언어를 오염시키는 방식
Flask 제작자 Armin Ronacher가 90일 코딩 세션 데이터로 LLM이 인간의 언어 습관을 오염시키는 현상을 분석. AI 슬롭이 신뢰에 미치는 영향을 다룹니다.
Written by
