AI Mode가 커져도 뉴스 콘텐츠가 안전한 이유, 구글 검색 데이터로 확인
구글 AI Mode가 한 분기 만에 4배 성장했지만 점유율은 여전히 0.25% 미만. 뉴스 콘텐츠는 왜 AI Overviews에 덜 잠식되는지 실제 쿼리 데이터로 확인합니다.
Written by

AI 에이전트 평가가 어려운 진짜 이유, 숨겨진 기술 부채
채팅 AI 평가와 달리 에이전틱 AI는 출력·트레이스·메모리·환경 상태 등 5가지 표면을 다루는 실험 제어 시스템이 필요합니다. 평가 부채가 어떻게 쌓이는지 소개합니다.
Written by

절반 크기로 프런티어를 따라잡은 GLM-5.2, 그 비결은 점수가 아니었다
절반 크기로 클로즈드 프런티어를 추격한 오픈웨이트 모델 GLM-5.2. 1M 컨텍스트를 실사용 가능하게 만든 IndexShare와, 모델이 정답을 훔치려 한 부정행위를 막은 RL 기법을 소개합니다.
Written by

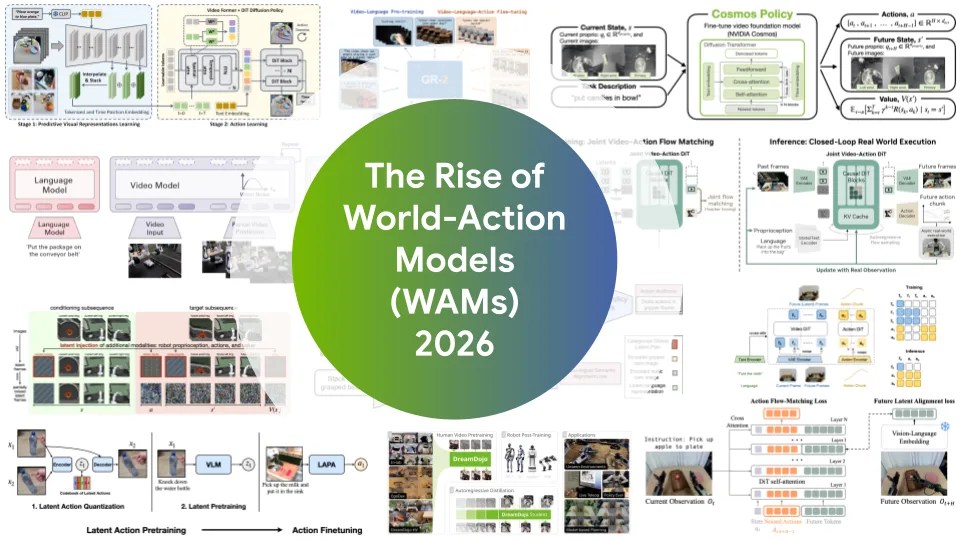
로봇 AI의 새 패러다임, 영상 생성 모델로 로봇을 제어하는 WAM 등장
영상 생성 모델을 로봇 제어에 연결하는 WAM이 VLA를 앞서기 시작했습니다. 두 패러다임의 차이, 실제 벤치마크 결과, 그리고 하이브리드 수렴 방향을 정리했습니다.
Written by
AI 모델도 공급망이다, Fable 5 차단이 드러낸 하루아침 의존성 리스크
미 정부가 Anthropic의 Fable 5·Mythos 5를 72시간 만에 차단한 사건을 AI 공급망 리스크 관점으로 분석합니다. 모델 의존성이 왜 새로운 취약점인지 살펴봅니다.
Written by

흩어진 문서를 AI가 읽는 지식으로, Google OKF의 설계 원칙
Google Cloud가 조직의 흩어진 지식을 AI 에이전트가 읽을 수 있도록 표준화한 오픈 스펙 OKF v0.1을 공개했습니다. Markdown 파일 기반의 단순한 포맷이 어떻게 지식 파편화 문제를 푸는지 소개합니다.
Written by

Cursor 개발자들이 알아야 할 것, SpaceX가 60억 달러를 쓴 진짜 이유
SpaceX가 AI 코딩 도구 Cursor를 60억 달러에 인수한 배경. xAI의 기술 격차 문제와 IPO 이후 강화된 자금력이 만들어낸 선택을 분석합니다. 개발자 도구 시장의 권력 지형 변화를 읽어봅니다.
Written by

AI 코딩 에이전트의 숨겨진 약점, 파일 탐색과 줄 찾기 사이의 간극
AI 코딩 에이전트는 버그가 있는 파일은 잘 찾지만, 파일 안에서 핵심 코드 줄을 찾는 정확도는 14~19%에 불과합니다. SWE-Explore 연구가 처음 측정한 탐색 능력의 맹점을 소개합니다.
Written by

llms.txt, 97%는 아무도 안 읽는다, Ahrefs 137K 도메인 분석
Ahrefs가 137K 도메인을 분석한 결과 llms.txt 파일의 97%는 아무도 읽지 않는다는 사실이 밝혀졌습니다. AI 검색 노출보다 코딩 에이전트용 파일이라는 실체를 데이터로 확인합니다.
Written by

LLM 컨텍스트 창의 숨겨진 함정, 100k 토큰 넘으면 에이전트가 멍청해진다
LLM의 실제 유효 컨텍스트는 광고 수치와 다르다는 Context Rot 연구와 개발자 경험. 코딩 에이전트 세션이 길어질수록 성능이 떨어지는 이유와 컨텍스트를 예산처럼 관리하는 접근법을 소개합니다.
Written by
