대부분의 기업 AI 프로젝트는 기술이 없어서 실패하지 않습니다. 모델이 그 회사를 모르기 때문에 실패합니다. 수십 년간 쌓인 내부 문서, 워크플로, 사내 규정 대신 인터넷을 학습한 모델에게 기업 업무를 맡기는 데서 오는 간극입니다.

Mistral AI가 이 간극을 좁히겠다며 Nvidia GTC 2026에서 Forge를 공개했습니다. 기업이 자체 데이터로 AI 모델을 처음부터 훈련할 수 있는 플랫폼으로, RAG나 파인튜닝처럼 기존 모델을 ‘적용’하는 방식이 아닌, 기업이 모델 자체를 ‘소유’하는 방향을 제안합니다.
출처: Introducing Forge – Mistral AI
RAG·파인튜닝과 무엇이 다른가
현재 기업 AI 도입의 주류는 크게 두 가지입니다. RAG(검색 증강 생성)는 모델이 답변할 때 내부 문서를 실시간으로 검색해 참고하게 하는 방식이고, 파인튜닝은 기존 모델의 가중치를 일부 조정해 특정 스타일이나 태스크에 맞게 다듬는 방식입니다. 두 방법 모두 베이스 모델은 여전히 외부 것을 쓴다는 공통점이 있습니다.
Forge는 여기서 한 발 더 나갑니다. Mistral의 공개 가중치 모델을 출발점으로 삼되, 기업의 내부 데이터로 처음부터 훈련을 진행합니다. 모델이 기업의 용어, 추론 방식, 제약 조건을 ‘학습’하는 것이죠. TechCrunch에 따르면 이는 비영어권 언어나 고도로 전문화된 데이터 처리에서 특히 유리하고, 외부 모델 제공업체에 대한 의존도를 낮출 수 있습니다. 모델이 갑자기 변경되거나 서비스가 종료될 리스크를 줄이는 겁니다.
Forge의 훈련 방식
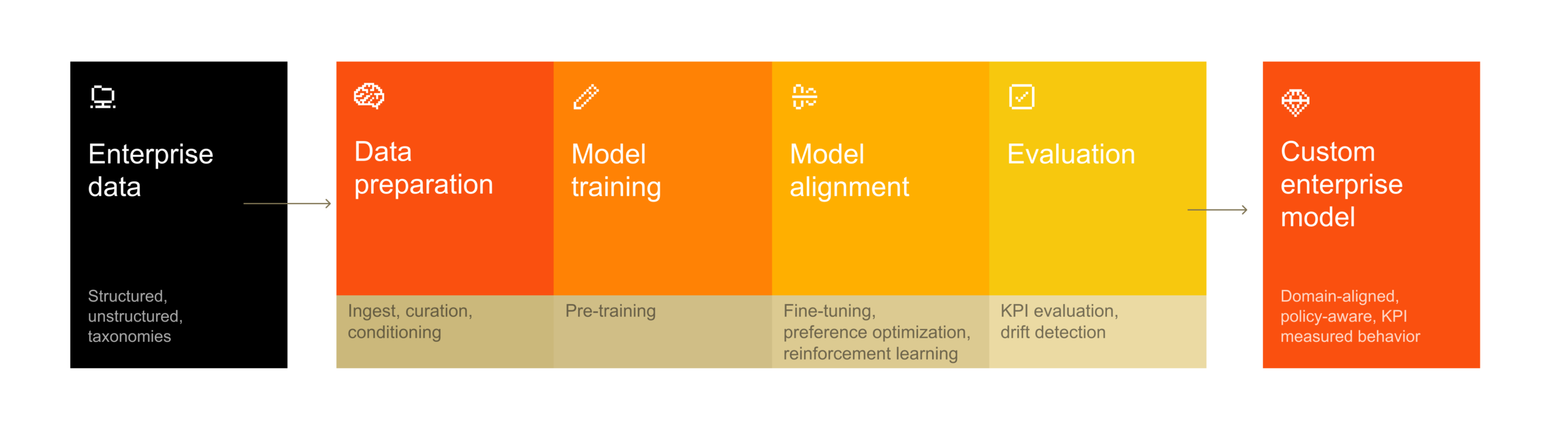
Forge는 모델 생애주기 전 단계를 지원합니다.
- 사전 훈련(Pre-training): 대규모 내부 데이터셋으로 도메인 인식 모델을 구축
- 후처리 훈련(Post-training): 특정 태스크와 환경에 맞게 모델 동작을 세밀하게 조정
- 강화 학습(Reinforcement Learning): 내부 정책, 평가 기준, 운영 목표에 모델을 정렬하고 에이전트 성능을 개선
Dense 모델과 MoE(Mixture-of-Experts) 아키텍처를 모두 지원해 성능, 비용, 운영 제약에 따라 선택할 수 있습니다. MoE는 유사한 규모의 Dense 모델 대비 낮은 지연과 비용으로 비슷한 성능을 낼 수 있는 구조입니다.
기업이 자체적으로 이 과정을 운영하기 어렵다는 점도 고려했습니다. Mistral은 IBM이나 Palantir처럼 현장 파견 엔지니어(FDE) 팀을 기업에 직접 투입해 적합한 데이터 선별과 평가 설계를 지원합니다.
에이전트가 직접 모델을 훈련시킨다
Forge에서 눈에 띄는 설계 중 하나는 ‘에이전트 퍼스트’ 철학입니다. Forge는 사람만 쓰는 도구가 아니라 자율 에이전트도 사용할 수 있도록 설계되었습니다. Mistral의 자율 에이전트 Mistral Vibe가 Forge를 사용해 모델을 파인튜닝하고, 최적 하이퍼파라미터를 찾고, 학습 작업을 스케줄링하고, 합성 데이터를 생성하는 식입니다.
코드 에이전트가 개발 도구의 주요 사용자가 되고 있는 흐름을 반영한 것으로, AI가 AI를 훈련시키는 구조가 이미 제품 설계에 녹아 있습니다.
데이터 주권과 AI 전략 자산화
Forge가 향하는 방향은 단순한 커스터마이징 그 이상입니다. Mistral은 AI 모델이 기업 인프라의 핵심 레이어가 될수록, 그 모델을 외부에 의존하는 것이 전략적 리스크가 된다는 관점을 분명히 합니다. 규제 환경이 까다로운 금융·정부·방산 분야에서는 데이터가 어떻게 인코딩되고 사용되는지에 대한 통제권이 필수입니다.
이미 ASML, 에릭슨, 유럽우주국(ESA), 싱가포르 DSO·HTX 등 파트너사에 Forge가 제공되고 있으며, Mistral은 올해 연간 반복 매출(ARR) $1B 달성 궤도에 있다고 밝혔습니다.
Forge의 기술적 세부 사항과 초기 파트너 사례는 공식 발표에서 확인할 수 있습니다.
참고자료: Mistral bets on ‘build-your-own AI’ as it takes on OpenAI, Anthropic in the enterprise – TechCrunch
답글 남기기