컨텍스트 창이 100만 토큰을 넘어서면서 많은 개발자들이 같은 질문을 했습니다. “이제 메모리 시스템이 필요 없지 않을까?” 연구 결과는 그렇지 않다고 말합니다. 관련 정보가 컨텍스트 중간에 위치하면 LLM 성능이 최대 30% 떨어집니다.

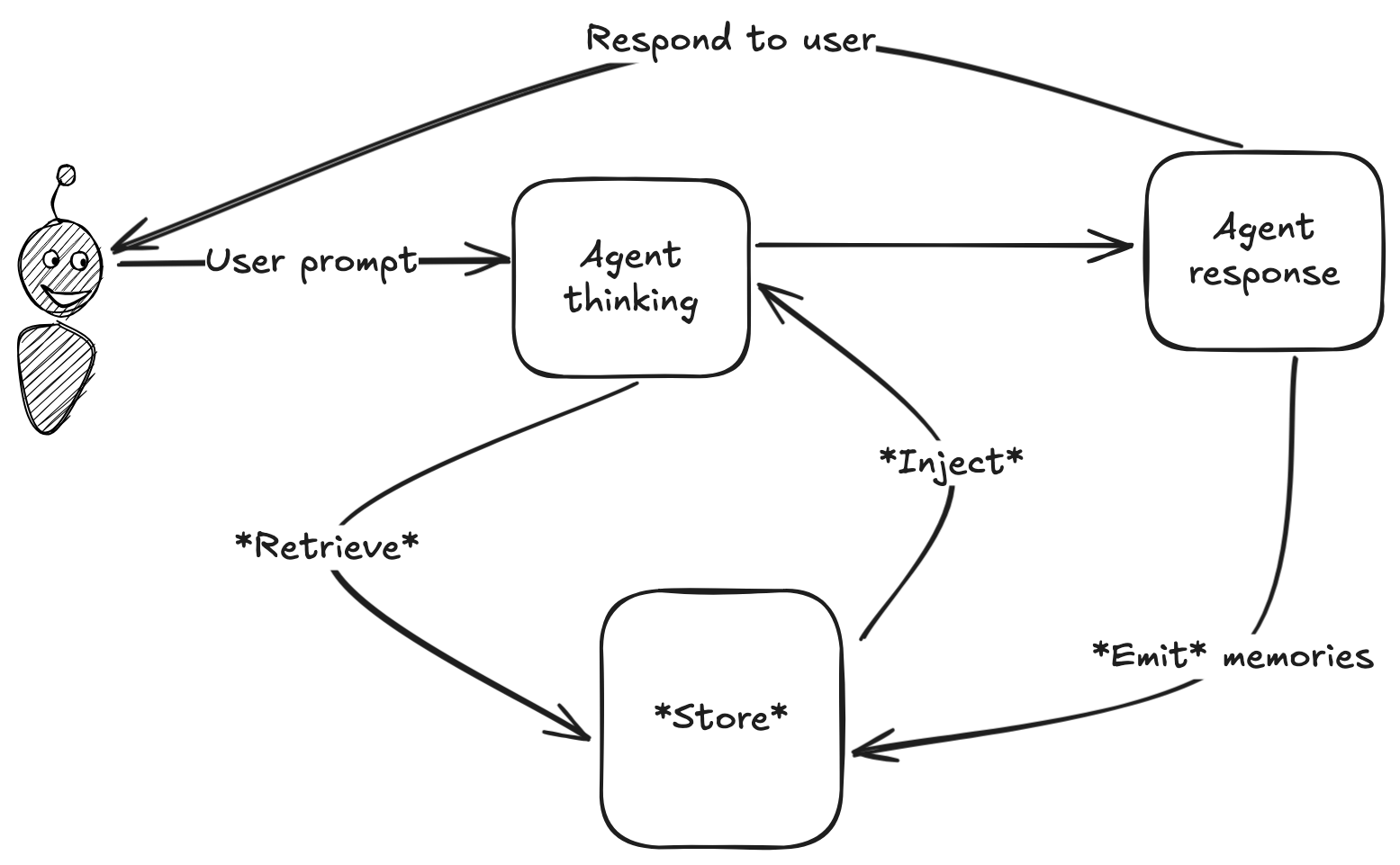
AI 에이전트 메모리 시스템 Elroy를 3년간 직접 개발해온 Tom Bedor가 Zep, Letta, Claude Code, 그리고 자신의 프로젝트 Elroy의 메모리 설계 방식을 비교 분석한 글을 발표했습니다. 모든 메모리 시스템은 저장(Store) → 검색(Retrieve) → 주입(Inject) → 생성(Emit) 이라는 4단계 구조를 공유하지만, 각 단계를 어떻게 구현하느냐에서 의미 있는 차이가 생깁니다.
출처: The design of AI memory systems – tombedor.dev
메모리와 컨텍스트는 다르다
둘을 혼동하기 쉽지만 구분이 중요합니다. 컨텍스트는 지금 대화창에 올라와 있는 텍스트 전체, 즉 AI가 현재 볼 수 있는 작업 공간입니다. 메모리는 대화가 끝난 후에도 외부에 저장되어 다음 세션에서 다시 불러와지는 정보입니다. 메모리 시스템이 하는 일은 결국 “저장소에서 관련 있는 것만 골라 컨텍스트에 올려놓기”입니다. 컨텍스트 창을 아무리 키워도 메모리를 대체할 수 없는 이유가 여기 있습니다.
저장 방식: 그래프 DB냐, 파일이냐
저장 방식은 크게 그래프 데이터베이스와 파일 두 진영으로 나뉩니다. Zep은 그래프 DB를 강력히 지지하며 ‘바늘 찾기(needle in a haystack)’ 성능에서 최고 수준이라 주장합니다. 반면 Letta는 “파일만으로 충분하다(Files are all you need)”는 연구 논문을 내놨고, 유출된 Claude Code 소스도 메모리를 마크다운 파일로 저장하는 방식을 채택하고 있습니다.
저장 단계에서 메모리 시스템이 공통적으로 겪는 오류는 세 가지입니다.
- 시간 착오: “다음 목요일”처럼 상대적 날짜를 기록하면, 나중에는 완전히 틀린 정보가 됩니다.
- 우선순위 오보정: 특정 대화에서만 의미 있는 사소한 사실이 이후 대화까지 살아남습니다.
- 단순 사실 오류: 사용자가 틀린 정보를 말했거나 생각이 바뀌었을 때, 메모리는 그대로 남습니다.
흥미롭게도, 저자는 자신의 Claude 메모리 요약본에서 이 세 가지 오류가 모두 발견됐다고 직접 밝힙니다. “이 메모리가 맞는지 어떻게 아나요?”라는 질문에 대한 솔직한 답은 “모른다”입니다. 대화 기록을 기반으로 생성된 메모리는 필연적으로 사실 오류를 포함합니다.
검색: 벡터 유사도 vs 백그라운드 AI 호출
메모리를 어떻게 꺼내오느냐도 구현마다 다릅니다. 대부분의 시스템은 벡터 유사도 검색을 기본으로 씁니다. 빠르지만 표면적으로 비슷한 내용을 잘못 매칭하는 문제가 있어, 검색 후 필터링 단계를 추가하는 게 일반적입니다.
Claude Code는 흥미로운 예외입니다. 벡터 유사도 대신 어떤 메모리가 있는지를 컨텍스트에 메타데이터로 보관하고, 실제 검색은 백그라운드 Sonnet 호출에 위임합니다. 저자는 이 방식이 공개 임베딩 API가 없는 현실적 이유에서 선택된 것으로 추측하면서도, 검색 정확도가 낮을 수 있고 관련 메모리가 응답에 늦게 도착할 수 있다는 한계를 지적합니다.
검색 지연시간도 중요한 문제입니다. 메모리 강화 응답은 메모리 호출, 필터링, 주입이라는 단계를 거치며 기본 응답보다 느릴 수밖에 없습니다. 그러나 브루클린 브리지 길이처럼 단순한 질문엔 메모리 검색 자체가 불필요합니다. 언제 검색하고 언제 건너뛸지 판단하는 것도 설계의 일부입니다.
주입: 어디에 끼워 넣을까
검색한 메모리를 대화 컨텍스트에 전달하는 방법은 세 가지입니다.
- 시스템 메시지 업데이트: 개념적으로 가장 자연스럽지만, 시스템 메시지를 자주 바꾸면 프롬프트 캐시가 무효화되어 비용이 급증합니다.
- 툴 호출: 메모리 검색 자체를 툴 호출로 수행한다면 자연스러운 선택입니다. Letta가 이 방식을 씁니다.
- 사용자/어시스턴트 메시지 삽입:
<memory>같은 HTML 태그로 메모리를 감싸 메시지에 끼워 넣습니다. 일부 모델이 태그를 그대로 출력하는 혼란이 생기기도 합니다.
주입 방식에서 투명성 문제도 따라옵니다. 메모리가 자동으로 주입될수록 사용자는 AI가 어떤 맥락을 가지고 답변하는지 알기 어렵습니다. 저자는 이 이유로 코딩 작업에는 메모리 시스템을 쓰지 않습니다. 대신 AI가 읽을 프로젝트 문서를 사람이 직접 작성해 AI의 전제를 통제합니다.
벤치마크보다 UX가 어렵다
저자의 핵심 주장은 이렇습니다. 메모리 시스템 설계에서 진짜 어려운 문제는 벤치마크 점수를 몇 포인트 높이는 게 아니라, 실제로 사람들이 쓰고 싶어하는 경험을 만드는 것이라는 겁니다. 얼마나 자주 검색할지, 얼마나 많은 메모리를 가져올지, 어디까지 사용자에게 보여줄지 — 이런 UX 판단이 기술적 선택 못지않게 중요합니다.
저자가 3년간 직접 만들고 쓰면서 도달한 결론은 단순한 저장 방식(마크다운 파일)과 사용자에 대한 투명성을 우선시하는 방향이었습니다. 각 구현 방식의 구체적인 트레이드오프와 실험 과정은 원문에서 확인할 수 있습니다.
참고자료:
- Lost in the Middle: How Language Models Use Long Contexts – arxiv.org
- Context Rot: Frontier Models Degrade as Context Grows – research.trychroma.com
- Files are all you need – letta.com
답글 남기기