LinkedIn 타임라인엔 이런 글이 넘쳐납니다. “스키마 마크업을 적용하면 AI 엔진이 당신의 콘텐츠를 더 잘 이해합니다. 단락을 300자로 제한하면 벡터 데이터베이스 청킹 방식을 제어할 수 있습니다. 이 방법으로 AI 인용률 13% 향상을 달성했습니다.” 그런데 이런 확신에 찬 처방들이 통제된 실험에서 하나씩 무너지고 있습니다.

AI 검색 전문가 Pedro Dias가 운영하는 뉴스레터 The Inference에서 GEO 업계의 과신 구조를 분석한 글입니다. Ahrefs의 대규모 통제 실험과 Google 공식 문서를 근거로, AI 검색 최적화 처방들이 실제로는 작동하지 않는다는 점을 짚었습니다.
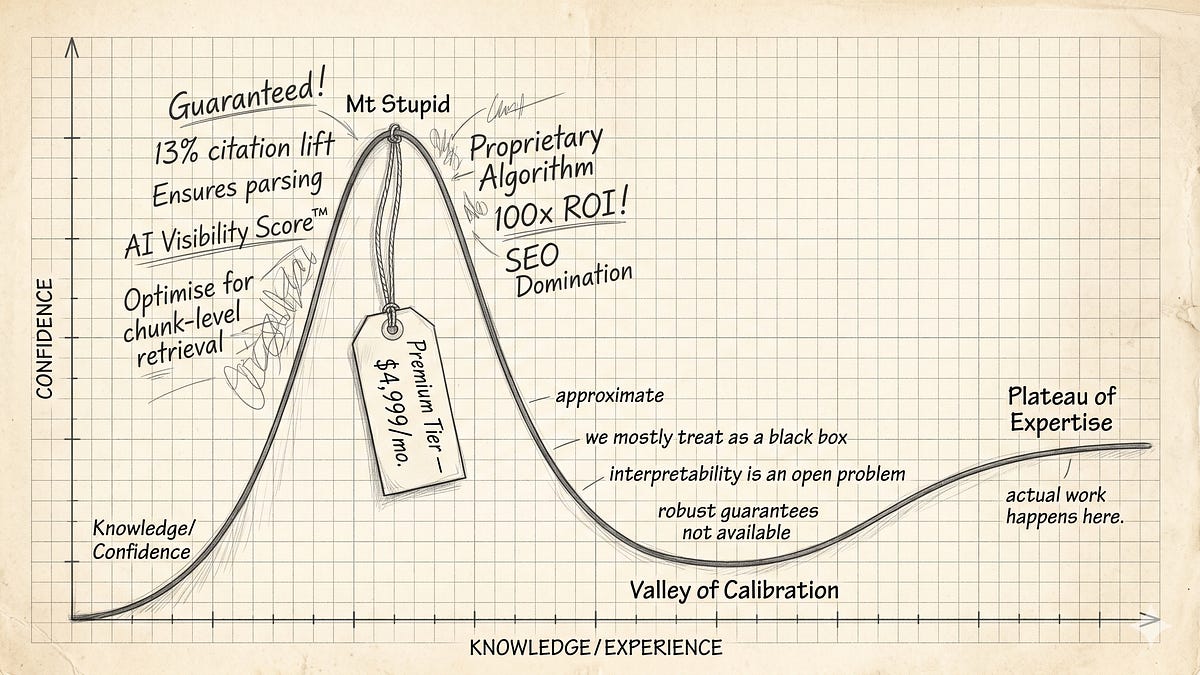
출처: Mt Stupid Has a Pricing Page – The Inference (Pedro Dias)
AI를 만든 사람들은 뭐라고 말하는가
GEO(Generative Engine Optimization) 컨설턴트들이 “AI 검색을 최적화해드립니다”라고 팔고 있는 동안, AI를 실제로 만든 사람들은 전혀 다른 말을 하고 있습니다.
Anthropic은 2024년 자사의 해석 가능성 연구에서 자기 모델에 대해 이렇게 썼습니다. “무언가가 입력되면 응답이 나오는데, 왜 다른 응답이 아닌 그 응답이 나왔는지는 명확하지 않습니다.” Google DeepMind의 기계적 해석 가능성 팀을 이끄는 Neel Nanda는 2025년 인터뷰에서, 이 분야가 원래 목표했던 수준의 강력한 보장을 제공할 수 있는 현실적인 경로가 보이지 않는다고 인정했습니다. OpenAI의 전 수석 과학자 Ilya Sutskever는 NeurIPS 2024 수상 연설에서 이렇게 말했죠. “AI가 더 많이 추론할수록, 더 예측 불가능해집니다.”
AI 시스템을 가장 깊이 이해하는 사람들이 갈수록 조심스러워지고 있는데, 시스템을 가장 멀리서 보는 컨설턴트들은 갈수록 확신에 차있습니다. 저자 Pedro Dias는 이 구조를 “더닝-크루거를 업계 스케일로 다시 그린 것”이라고 표현합니다.
Ahrefs 실험이 밝혀낸 것
지난달 Ahrefs가 발표한 연구 제목은 꽤 도발적입니다. “1,885개 페이지에 스키마를 추가해서 추적했더니, AI 인용률이 거의 변화 없었다.”
연구 설계는 탄탄합니다. 2025년 8월부터 2026년 3월 사이에 JSON-LD 스키마를 추가한 페이지 1,885개와 대조군 4,000개를 비교했습니다. 스키마 추가 전후 30일씩 Google AI Overviews, Google AI Mode, ChatGPT에서의 인용 변화를 차분법(difference-in-differences)으로 분석했죠. 결과는 어떤 플랫폼에서도 의미 있는 인용률 향상이 없었고, Google AI Overviews에서는 오히려 통계적으로 유의미한 소폭 하락이 나타났습니다. 이 차이가 우연일 확률은 약 2,500분의 1 수준입니다.
GEO 플레이북의 핵심 처방 중 하나가 통제된 조건에서 반증된 셈입니다.
왜 이런 결과가 나왔을까요? LLM은 구조화된 마크업을 처리하는 게 아니라 비정형 언어를 읽습니다. 스키마 마크업과 청킹 최적화는 존재하지 않는 아키텍처를 상정한 처방입니다. 마치 검색엔진 크롤러를 위한 기법을 LLM에 적용하는 것과 비슷한 범주의 오류죠.
Google이 직접 선을 그었다
같은 주 금요일, Google은 검색의 생성형 AI 기능 최적화에 관한 공식 문서를 발표했습니다. 내용은 직접적이었습니다. llms.txt 파일은 불필요하다, 콘텐츠 청킹은 필요하지 않다, AI 시스템을 위해 콘텐츠를 재작성할 필요가 없다, 특별한 스키마 마크업은 필요하지 않다, 인위적인 언급 추구는 도움이 되지 않는다. 공식 문서에서 보기 드물게 직접적인 표현으로, GEO와 AEO(Answer Engine Optimization)라는 용어를 명시적으로 언급하며 이 플레이북을 전면 부정했습니다.
2주 사이에 세 가지 독립적인 출처에서 같은 결론이 나왔습니다. 원리적 분석에서, 통제된 측정에서, 그리고 Google 자신으로부터. 그런데도 프레임워크는 계속 팔립니다.
왜 틀린 처방이 계속 팔리는가
이 질문이 더 흥미롭습니다. 저자는 구조적 이유를 지목합니다. 확신에 찬 주장을 올리는 데는 비용이 없습니다. 참여를 끌어내고, 청중을 만들고, 영업 기회를 창출합니다. 나중에 틀렸다는 게 밝혀져도 이미 다음 트렌드로 넘어간 상태입니다. 반면 반박하는 데는 비용이 따릅니다. 싸움을 걸고, 브랜드에 불리하고, 알고리즘도 보상하지 않습니다.
GEO 컨설턴트에게 “이 방법이 실제로 어떤 메커니즘으로 작동하는지, 반증 가능성은 무엇인지” 물어보면 돌아오는 답은 전문 용어입니다. “벡터 공간 정렬”, “청크 레벨 시맨틱 검색”. 머신러닝 연구에서 실제로 쓰이는 용어들을 조합했지만, 검증이 어려운 조합입니다. 기술적 지식이 없는 사람은 어떤 조합이 실제이고 어떤 게 즉흥적인지 구분할 수 없습니다.
결국 시스템을 가장 잘 이해하는 사람들이 신중해질 때, 자신감을 팔 수 있는 건 가장 멀리 있는 사람들입니다. 신중한 언어는 가격표에 맞지 않으니까요.
답글 남기기