
AI 모델에 끝없는 프롬프트를 연결하는 것도 한계가 있습니다. 결국 대형 언어 모델(LLM)은 의도한 방향에서 벗어나고, 토큰 예산은 바닥나게 됩니다. 매번 조정할 때마다 불안정한 탑에 블록을 하나씩 쌓는 기분이라면, 당신만 그런 것이 아닙니다.
파인튜닝은 LLM에게 당신의 규칙, 톤, 도구 호출 능력을 직접 가르쳐서, 당신과 사용자들이 단어와 씨름하는 시간을 줄여줍니다. 이 가이드에서는 프롬프트 엔지니어링의 한계, 파인튜닝으로 업그레이드해야 할 시점, 그리고 시간과 비용을 낭비하지 않고 시작하는 단계별 방법을 알아보겠습니다.
파인튜닝이 해결하는 구체적 문제들
파인튜닝은 프롬프팅으로는 해결할 수 없는 특정하고 측정 가능한 문제들을 해결합니다.
1. 토큰 비용 폭증과 성능 저하
긴 시스템 프롬프트는 여러 문제를 야기합니다:
- 처리 시간 증가: 속도에 영향
- 토큰/GPU 사용량 증가: 비용에 영향
- 프롬프트 준수율 감소: 길이가 증가할수록 품질에 악영향
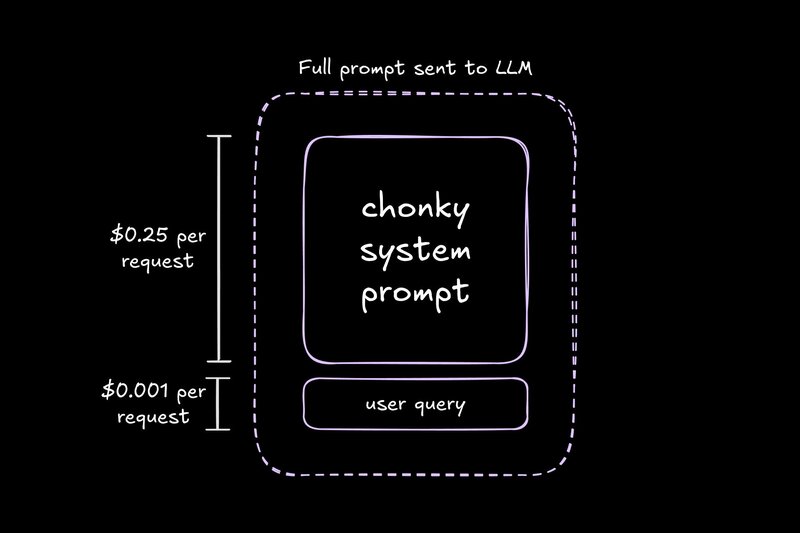
5,000토큰짜리 시스템 프롬프트를 이미 당신의 스타일을 “이해하는” 모델로 바꾼다고 상상해보세요. 매번 호출할 때마다 지침을 되풀이하는 대신, 파인튜닝된 모델은 절반의 컨텍스트로도 정확한 결과를 반환합니다.
2. 일관되지 않은 출력 형식
JSON 형식 정확도가 5% 미만에서 99% 이상으로 향상되는 것을 보았습니다. 작은 모델들은 종종 다음과 같은 문제를 보입니다:
- 유효한 JSON을 생성하지만 잘못된 스키마 (잘못된 키 이름, 누락된 필수 필드 등)
- XML, YAML, 마크다운 등 다른 형식에서도 동일한 문제 발생
3. 반복되는 엣지 케이스 오류
LLM은 예상치 못한 입력에 대해 매우 이상하게 행동할 수 있습니다. 이미 긴 프롬프트를 확장해서 각각의 새로운 엣지 케이스를 패치하는 대신, 실제 문제가 되는 사례들을 파인튜닝 훈련 세트에 포함시키세요.
4. 도구 호출의 불안정성
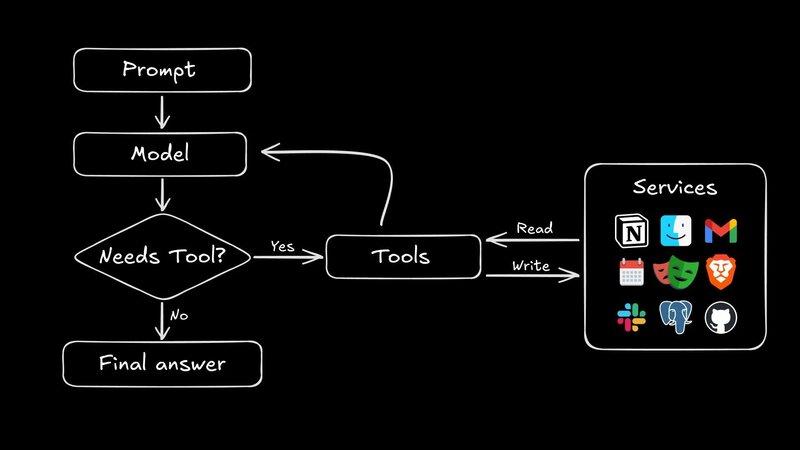
함수 호출은 챗봇을 행동하는 에이전트로 변화시킬 수 있습니다. 파인튜닝을 통해 API 시그니처를 모델의 행동에 직접 구워넣을 수 있습니다.
매번 요청마다 함수 스키마를 주입하는 대신, 모델이 언제 어떻게 각 엔드포인트를 호출해야 하는지 알게 되어 채팅이 실제 상호작용으로 바뀝니다.
파인튜닝 도입 시점 판단하기
파인튜닝은 강력하지만, 프롬프트 수준에서 모델을 반복하는 것이 훨씬 빠릅니다. 따라서 첫 번째로 손을 뻗을 도구가 되어서는 안 됩니다.
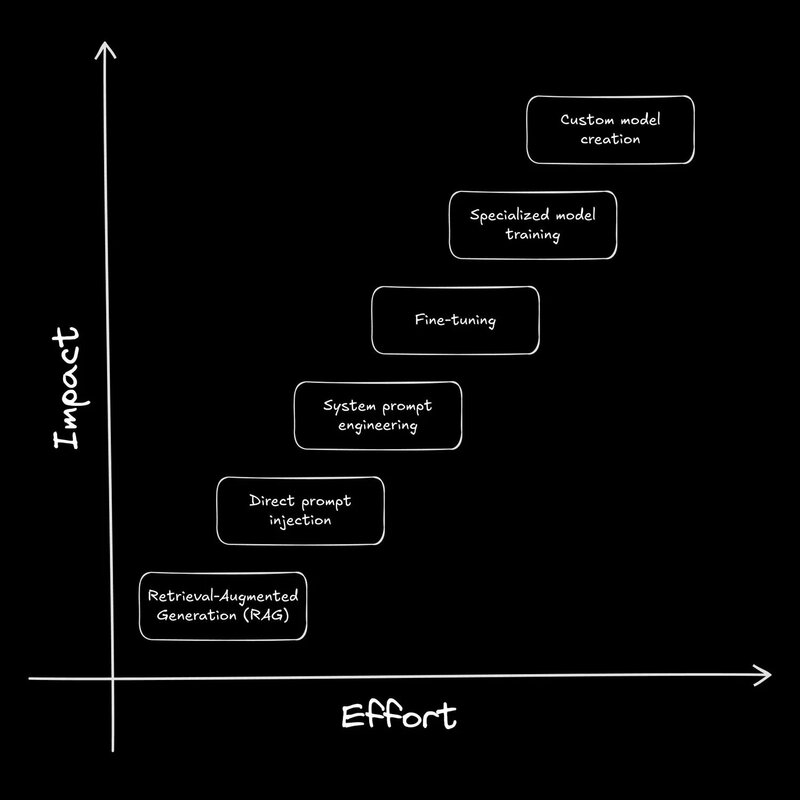
파인튜닝이 필요한 상황의 신호들
다음과 같은 신호들이 나타나면 한계에 부딪혔다는 의미입니다:
- 시스템 프롬프트 길이가 소설 수준: “항상 이렇게 해라” 지침이 소설만큼 길어졌다면, 프롬프트가 누락된 모델 행동을 보상하고 있는 것입니다
- 토큰 예산 폭발: 올바른 출력을 유도하기 위해 수백, 수천 개의 추가 토큰을 지출하고 있다면 비용과 지연시간이 문제가 됩니다
- 조정 효과 감소: 프롬프트의 작은 변경이 더 이상 의미 있는 개선을 가져오지 않고, 끝없는 “프롬프트 수정 지옥”에 빠져있습니다
- 예측 불가능한 엣지 케이스: 모델이 걸려 넘어지는 새로운 사용자 입력을 계속 발견하게 되어 프롬프트 해킹의 백로그가 쌓여갑니다
먼저 시도해볼 프롬프트 수준 해킹들
위의 상황이 맞더라도, 먼저 다음과 같은 프롬프트 엔지니어링 해킹들을 시도해보세요:
- Few-shot 예시: 2-3개의 고품질 입력/출력 쌍을 인라인으로 보여주기
- 프롬프트 체이닝: 복잡한 작업을 더 작고 순차적인 프롬프트들로 나누기
- 함수 호출 훅: 내장 도구나 API를 사용해서 모델이 로직을 조작하는 대신 오프로드할 수 있게 하기
이런 방법들로도 여전히 프롬프트를 저글링하고 있다면, 파인튜닝을 시작할 때입니다.
RAG vs 파인튜닝 선택 기준
RAG(검색 증강 생성)와 파인튜닝은 종종 혼동됩니다:
- RAG를 사용할 때: 최신 사실이 필요하거나 데이터가 자주 변경되는 경우 (제품 문서, 뉴스 피드 등)
- 파인튜닝을 사용할 때: 일관된 톤, 엄격한 출력 형식, 또는 매번 프롬프트로 안정적으로 유도할 수 없는 내재된 행동이 필요한 경우
단계별 파인튜닝 실행 가이드
1단계: 목표 설정과 평가 지표 정의
파인튜닝은 세 가지 기초 기둥으로 요약되며, 데이터 품질을 최우선으로 하는 마인드셋이 필요합니다:
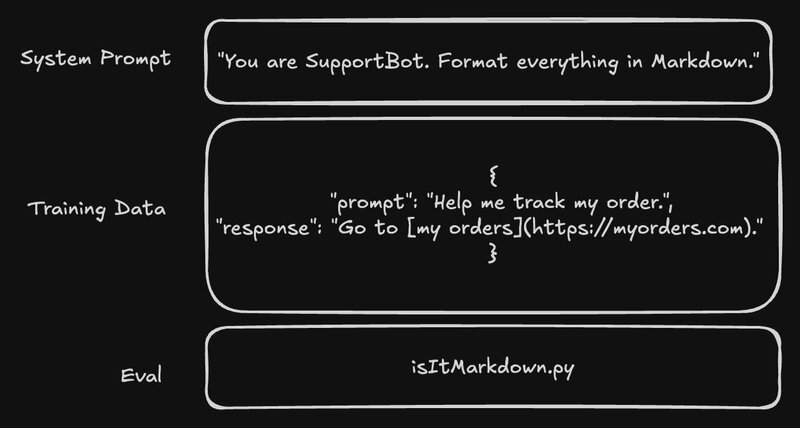
세 가지 기둥:
- 검증된 시스템 프롬프트: 모델의 행동을 고정하는 간결한 “지침” 작성
- 큐레이션된 데이터셋: 원하는 입력/출력 패턴을 보여주는 사례들을 손수 선별
- 명확한 평가 지표: 성공을 판단할 방법을 미리 정의 (토큰 사용량, 출력 유효성, 인간 평가 등)
2단계: 훈련 데이터 준비
데이터 중심 마인드셋 채택:
- 편향이나 노이즈 감사: 스타일과 모순되거나 원치 않는 행동을 도입하는 예시들을 제거
- 엣지 케이스 균형: 사용자의 10%가 이상한 버그를 유발한다면 그런 예시들을 포함하되, 데이터셋을 지배하지 않게 하기
- 반복, 축적 금지: 가지고 있는 모든 예시를 합치고 싶은 유혹이 있지만, 작게 시작하세요 (20-50개의 최고 예시), 실패 모드를 찾고, 필요한 데이터만 추가하기
데이터 형식 예시:
// 레시피 블로그 스타일 파인튜닝
{
"prompt": "CSS 박스 모델을 설명해주세요.",
"response": "아, CSS 박스 모델이군요! 할머니의 소중한 삼나무 상자가 생각나네요. 상자에는 내용물이 있고, 내용물 주변의 패딩, 튼튼한 나무 테두리, 그리고 다락방에서 차지하는 공간(마진)이 있었듯이, 모든 HTML 요소에는 콘텐츠, 패딩, 보더, 마진이 있어요. 정말 멋지죠!"
}
3단계: 모델 선택
목표에 따른 모델 선택 가이드:
- 모바일에서 로컬 실행: Gemma 3n/1B, Qwen 3 1.7B 같은 초소형 모델
- 데스크톱에서 로컬 실행: Qwen 3 4B/8B, Gemma 3 2B/4B 같은 소형 모델
- 비용 절감 또는 속도: 1B-32B 범위의 다양한 모델 크기로 품질/속도/비용 트레이드오프 비교
- 최대 품질: Llama 70b, Gemma 3 27b, Qwen3, GPT 4.1, Gemini Flash/Pro 같은 대형 모델
4단계: 하이퍼파라미터 설정
주요 설정값들:
- 학습률: 모델이 가중치를 업데이트할 때 각 단계의 크기. 너무 높으면 사전 훈련된 것을 “잊어버리거나” 불안정해짐. 너무 낮으면 변화가 거의 없음
- 배치 크기: 모델이 한 번에 학습하는 프롬프트-응답 쌍의 수
- 시퀀스 길이: 입력/출력의 최대 길이
- 에포크 수: 모델이 전체 데이터셋을 보는 횟수. 보통 3-5회면 충분
대부분의 현대적 프레임워크와 클라우드 플랫폼에서는 이런 설정을 자동으로 조정해줄 수도 있습니다.
5단계: 훈련 및 검증
검증 체크리스트:
- 미니 테스트 스위트 스크립팅: 가장 일반적이거나 중요한 프롬프트 10-20개를 모델에 실행해서 원하는 답변(형식, 톤)을 얻는지 확인
- 훈련 곡선 모니터링: 손실이 부드럽게 감소하면 좋은 신호. 갑자기 치솟거나, 평평해지거나, 사방으로 튀면 문제가 있을 수 있음
- 인간 검토: 팀원들이나 실제 사용자들에게 테스트해보도록 요청
플랫폼별 시작하기
초보자용 플랫폼
OpenAI의 관리형 플랫폼
- JSONL 데이터셋 업로드하고 단일 CLI 명령어나 웹 UI로 파인튜닝 작업 시작
- OpenAI 모델로 제한되지만 처음 파인튜닝을 시도하기에 좋은 옵션
- 훈련 비용: $25.00 / 1M 토큰
Hugging Face
- CSV/JSONL을 업로드하고, 베이스 모델을 선택하고, “Train” 버튼을 누르는 진정한 노코드 웹 인터페이스
- 오픈소스 모델 파인튜닝으로 제한되지만 시작하기에 최고의 방법
Cohere
- 명확하고 개발자 친화적인 문서와 대시보드
- GUI나 풀 스크립팅을 통해 빠른 결과 제공
- 회사에서 파인튜닝 워크플로우를 완전 자동화하기에 적합
기업용 플랫폼
Google Vertex AI
- GCP 콘솔이나 SDK를 통해 Google의 모델(예: Gemini) 파인튜닝
- 전체 및 어댑터 기반 튜닝, BigQuery와 Cloud Storage와의 긴밀한 통합
- 이미 GCP를 사용 중이라면 훌륭한 선택
AWS Bedrock
- AWS 콘솔이나 API를 통해 주요 파운데이션 모델들 파인튜닝
- S3에 데이터를 업로드하고, 구성하고, 실행하는 완전 관리형 보안 옵션
- AWS에서 작업하는 경우에 적합
실전 팁과 주의사항
비용 최적화 전략
모델 크기별 고려사항:
- 소형 모델 (1B-8B): 빠르고 저렴하지만 복잡한 작업에서는 품질 제한
- 중형 모델 (14B-32B): 좋은 균형점. 예: Qwen 14B는 GPT-4.1보다 6배 빠르고 ~3% 비용
- 대형 모델 (70B+): 최고 품질이지만 높은 비용과 느린 속도
로컬 vs 클라우드 배포:
- 로컬 배포: 추론 비용이 0이 되지만 속도 트레이드오프 예상
- 클라우드 API: 빠르고 확장 가능하지만 지속적인 비용 발생
프라이버시 고려사항: 많은 사용자들이 OpenAI나 Anthropic 같은 제공업체에 개인 데이터를 보내기를 원하지 않습니다. 파인튜닝을 통해 로컬에서 실행되는 작은 모델을 만들어 동일한 품질 지표를 유지하면서 모든 사람에게 도움이 됩니다.
결론: 파인튜닝의 실용적 가치
파인튜닝은 프롬프팅으로는 해결할 수 없는 실제 문제들을 해결합니다. 일관되지 않은 출력, 부풀어 오른 추론 비용, 또는 규칙을 따르지 않는 모델로 고생하고 있다면 투자할 가치가 있습니다.
적절한 도구를 사용하면 과정이 복잡하지 않습니다: 목표를 선택하고, 훈련 데이터를 생성하고(합성 데이터도 잘 작동), 몇 개의 후보를 훈련하고, 중요한 것을 측정하세요. 대부분의 팀들은 몇 번의 반복 내에서 의미 있는 개선을 보게 됩니다.
작게 시작하고, 데이터를 예리하게 유지하고, 작업을 테스트하고, 배운 것을 기반으로 구축하세요. 어려운 부분은 코드가 아니라 모델이 무엇을 하기를 원하는지 알고, 올바른 예시를 보여주는 것입니다.
도구는 그 어느 때보다 접근하기 쉬우니, 모델에게 한두 가지 기술을 가르쳐보고 당신(과 사용자들)을 위해 무엇을 할 수 있는지 확인해보세요.
답글 남기기