AI 모델이 점점 거대해지면서 강화학습(RL) 훈련의 난이도도 함께 올라가고 있습니다. 특히 수천억 개의 파라미터를 가진 MoE(Mixture of Experts) 모델을 훈련할 때는 메모리 부족, 학습-추론 환경 불일치, 느린 데이터 생성 속도 같은 문제들이 실전에서 끊임없이 발목을 잡죠.

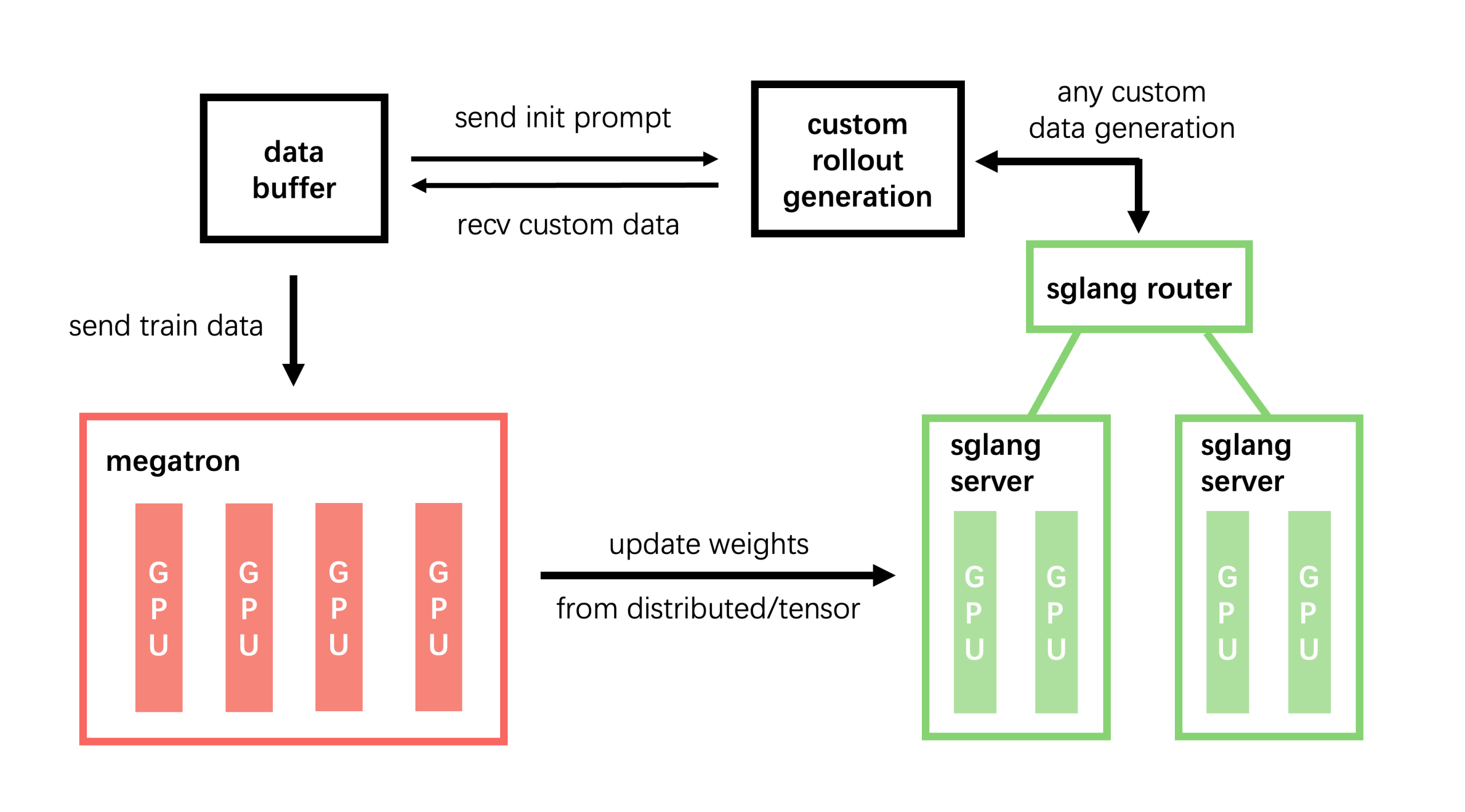
LMSYS가 대규모 MoE 모델의 강화학습 훈련을 위한 엔터프라이즈급 프레임워크 Miles를 공개했습니다. Miles는 이미 GLM-4.6(355B 파라미터) 같은 대형 모델 훈련에 사용된 경량 프레임워크 slime을 기반으로 하되, 프로덕션 환경에서 요구되는 안정성과 확장성을 대폭 강화한 버전입니다. 연구실 프로토타입이 아니라 실제로 대규모 모델을 돌려본 팀이 만든 도구라는 점에서 실용적 가치가 큽니다.
출처: Introducing Miles — RL Framework To Fire Up Large-Scale MoE Training – LMSYS Org
학습과 추론, 완벽하게 일치시키기
RL 훈련에서 자주 마주치는 문제 중 하나는 학습 환경과 추론 환경이 미묘하게 달라서 모델이 이상하게 학습된다는 점입니다. 같은 입력을 넣어도 학습할 때와 실제로 사용할 때 출력이 달라지는 거죠. Miles는 이 문제를 True on-policy 방식으로 해결했습니다.
연구팀은 Flash Attention 3, DeepGEMM 같은 최신 커널과 배치 불변 커널을 활용해 학습과 추론 과정의 수치 연산을 비트 단위까지 완전히 일치시켰습니다. 그 결과 KL divergence가 정확히 0이 됐죠. 이론적으로 완벽한 on-policy 학습이 가능해진 겁니다. 그래프를 보면 학습과 추론 간 절대 차이가 거의 보이지 않을 정도로 정밀하게 맞춰졌습니다.
추론 속도를 25% 끌어올린 온라인 학습
대형 모델의 RL 훈련에서 병목은 대부분 데이터 생성, 즉 추론 단계에서 발생합니다. Miles는 speculative decoding으로 이 문제를 푸는데, 여기서 핵심은 draft 모델을 RL 과정 내내 계속 학습시킨다는 점입니다.
기존 방식은 draft 모델을 고정시켜 놓고 사용했어요. 그런데 메인 모델의 정책이 RL로 계속 바뀌는데 draft 모델은 그대로니까, 시간이 지날수록 둘 사이의 간극이 벌어지고 accept length가 줄어들죠. Miles는 RL 훈련 중에도 draft 모델에 온라인 SFT를 적용해 메인 모델을 따라가게 만듭니다. 특히 훈련 후반부에서 25% 이상의 롤아웃 속도 향상을 보여줬습니다.
메모리 관리의 실전 노하우
대규모 모델을 돌리다 보면 OOM(Out of Memory) 에러는 피할 수 없는 숙제입니다. Miles는 이 문제를 여러 각도에서 다뤘어요. 단순한 OOM은 크래시 없이 에러만 전파하도록 처리하고, NCCL 관련 OOM을 막기 위한 메모리 여유 공간(margin)을 설정했습니다. FSDP의 과도한 메모리 사용 문제도 수정했고, move 기반 및 부분 오프로딩, 호스트 메모리 피크 절약 같은 옵션도 추가했죠.
이런 기능들은 화려해 보이진 않지만, 실제로 대규모 훈련을 돌려본 사람이라면 얼마나 절실한지 알 겁니다. 며칠씩 돌리는 훈련이 OOM 하나로 날아가는 걸 막아주는 안전장치들이거든요.
실전 검증: GLM-4.6
Miles(와 그 기반인 slime)는 이미 실전에서 검증됐습니다. GLM-4.6은 총 355B 파라미터에 32B가 활성화되는 MoE 모델인데, 이 모델의 RL 훈련에 slime이 사용됐어요. 연구실에서 작은 모델로만 실험한 프레임워크가 아니라, 실제로 대규모 MoE를 돌려본 팀이 부딪힌 문제들을 해결하면서 만든 도구라는 뜻입니다.
Miles는 여기서 한 걸음 더 나아가 GB300 같은 최신 하드웨어 지원, 멀티모달 학습, SGLang spec v2 호환성, GPU 장애 대응 같은 엔터프라이즈 요구사항을 로드맵에 담았습니다.
엔터프라이즈 RL 훈련의 실용화
Miles가 의미 있는 이유는 대규모 RL 훈련을 “이론적으로 가능”한 수준에서 “실제로 돌릴 수 있는” 수준으로 끌어올렸다는 점입니다. True on-policy로 학습 품질을 보장하고, 온라인 draft 학습으로 속도를 높이고, 세심한 메모리 관리로 안정성을 확보했죠.
물론 한계도 있습니다. 여전히 대규모 GPU 클러스터가 필요하고, 설정이 복잡하며, 최신 하드웨어나 멀티모달 같은 기능은 아직 개발 중입니다. 그래도 오픈소스로 공개됐다는 점, 그리고 실제로 최전선 모델 훈련에 쓰인 경험이 녹아있다는 점은 큰 장점입니다.
자체 모델 훈련을 고민하는 팀이라면, 그리고 MoE 아키텍처에 관심 있는 연구자라면 한번 살펴볼 만한 도구입니다.
참고자료:
- slime GitHub – Miles의 기반이 된 경량 RL 프레임워크
- Miles GitHub – 엔터프라이즈급 RL 프레임워크
답글 남기기