
최근 ChatGPT, Claude, Gemini와 같은 대형 언어 모델(Large Language Models, LLMs)은 놀라운 언어 능력을 보여주며 많은 주목을 받고 있습니다. 이러한 모델들이 어떻게 작동하는지, 특히 문맥을 어떻게 이해하고 활용하는지에 대한 이해는 AI 개발과 활용에 중요한 통찰을 제공합니다. 구글 딥마인드의 Timothy Nguyen 연구원이 최근 발표한 “Understanding Transformers via N-gram Statistics”라는 논문은 이 질문에 대한 흥미로운 답을 제시합니다.
트랜스포머 모델의 작동 원리에 대한 의문
트랜스포머 기반 언어 모델들은 놀라운 언어 능력을 보여주지만, 정확히 어떻게 작동하는지는 여전히 미스터리로 남아있습니다. 특히 모델이 다음 토큰을 예측할 때 문맥(context)을 어떻게 활용하는지에 대한 이해는 아직 완전하지 않습니다.
이 논문은 핵심적인 질문에 초점을 맞춥니다:
“트랜스포머 기반 대형 언어 모델(LLM)은 다음 토큰을 예측할 때 문맥을 어떻게 활용하는가?”
N-gram 통계를 활용한 새로운 접근법
저자는 이 질문에 답하기 위해 언어 모델의 예측을 간단한 통계적 규칙으로 설명할 수 있는지 연구했습니다. 이를 위해 N-gram 기반 통계를 활용한 규칙들을 만들고, 이 규칙들이 얼마나 잘 언어 모델의 예측과 일치하는지 분석했습니다.
 그림 1: 규칙 근사화 설명. 주어진 문맥에 대해 다양한 N-gram 기반 규칙들이 서로 다른 다음 토큰 예측 분포를 생성합니다. (출처: 원논문)
그림 1: 규칙 근사화 설명. 주어진 문맥에 대해 다양한 N-gram 기반 규칙들이 서로 다른 다음 토큰 예측 분포를 생성합니다. (출처: 원논문)
위 그림에서 문맥은 세 개의 토큰(“the”, “tired”, “dog”)으로 구성되어 있습니다. 첫 번째 규칙은 문맥의 모든 세 토큰을 사용하여 학습 데이터에서 도출된 4-gram 규칙에 기반한 예측을 수행합니다. 두 번째 규칙은 처음과 마지막 토큰만 사용하여 3-gram 규칙을 형성합니다(가운데 “tired” 토큰은 무시되므로 “slept” 토큰에 첫 번째 규칙보다 낮은 가중치가 부여됨). 세 번째 규칙은 학습 데이터에서 두 번째 토큰이 임의인 세 토큰 문맥을 집계하여 얻은 N-gram 통계를 사용하여 예측합니다(즉, 두 번째 토큰은 주변화됨). 이러한 규칙 목록이 주어지면 어떤 규칙의 예측 분포가 트랜스포머의 예측과 가장 일치하는지 알아볼 수 있습니다.
N-gram 규칙이란?
이 연구에서 사용한 N-gram 규칙은 일반적인 N-gram 모델보다 더 정교합니다. 기본적으로 N-gram 모델은 이전 (N-1)개 토큰에 기반하여 다음 토큰을 예측합니다.
논문에서 제안한 규칙들은 세 가지 기본 작업을 통해 문맥 토큰을 처리합니다:
- 유지(Keep, +): 토큰을 그대로 유지하여 정확한 일치 요구
- 제거(Discard, -): 토큰을 무시하고 규칙에서 제외
- 주변화(Marginalize, *): 와일드카드로, 해당 위치에 어떤 토큰이 와도 상관없음을 의미
이러한 방식으로, 논문은 다양한 규칙 집합을 정의합니다:
- R^suffix_M: “+” 기호만 허용하는 표준 N-gram 모델
- R^subgram_M: “+” 및 “-” 기호를 허용하는 문맥 부분집합 기반 모델
- R^all_M: “+”, “-“, “*” 모든 기호를 허용하는 가장 유연한 규칙 집합
주요 발견: 트랜스포머의 내부 동작 이해하기
이 연구를 통해 저자는 트랜스포머 모델의 작동 방식에 대한 여러 중요한 통찰을 얻었습니다.
1. 근사화 기준 (Approximation Criterion)
트랜스포머 모델의 예측은 다른 학습 실행(dataset shuffles)에서 일관성을 보이는 경우, 즉 모델 분산(model variance)이 낮을 때 N-gram 규칙으로 잘 근사될 수 있습니다. 특히 학습 데이터에서 충분히 높은 빈도로 나타나는 문맥에 대한 예측이 이에 해당합니다.
 그림 2: 모델 분산과 최적 규칙 거리 간의 관계. 모델 분산이 낮을수록(좌측 하단) N-gram 규칙으로 모델 예측을 잘 근사할 수 있습니다. (출처: 원논문)
그림 2: 모델 분산과 최적 규칙 거리 간의 관계. 모델 분산이 낮을수록(좌측 하단) N-gram 규칙으로 모델 예측을 잘 근사할 수 있습니다. (출처: 원논문)
2. 커리큘럼 학습 동역학 (Curriculum Learning Dynamics)
연구진은 학습 과정에서 트랜스포머 모델이 어떻게 진화하는지 분석했습니다. 놀랍게도, 모델은 처음에는 단순한 규칙을 학습하고 점차적으로 더 복잡한 규칙으로 진화하는 형태의 ‘커리큘럼 학습’을 자연스럽게 실행합니다.
 그림 3: 학습 과정에 따른 규칙 복잡성 변화. 모델은 학습이 진행됨에 따라 더 복잡한 규칙(더 많은 문맥 토큰을 사용)에 가까워집니다. (출처: 원논문)
그림 3: 학습 과정에 따른 규칙 복잡성 변화. 모델은 학습이 진행됨에 따라 더 복잡한 규칙(더 많은 문맥 토큰을 사용)에 가까워집니다. (출처: 원논문)
3. 과적합 감지 방법 (Overfitting Criterion)
N-gram 규칙 분석을 바탕으로, 저자는 별도의 검증 데이터 없이도 과적합을 감지할 수 있는 새로운 방법을 제안했습니다. 이 방법은 모델이 전체 문맥을 기억하면서 부분 문맥을 활용한 일반화 능력을 상실할 때 과적합이 발생한다는 직관을 수치적으로 정확하게 포착합니다.
 그림 4: 과적합 감지. 문맥 길이를 제한한 트랜스포머 모델은 과적합을 보이지 않는 반면, 전체 문맥을 사용하는 모델은 과적합을 보입니다. (출처: 원논문)
그림 4: 과적합 감지. 문맥 길이를 제한한 트랜스포머 모델은 과적합을 보이지 않는 반면, 전체 문맥을 사용하는 모델은 과적합을 보입니다. (출처: 원논문)
4. 근사화 강도 (Approximation Strength)
TinyStories 데이터셋에서는 모델 예측의 최대 79%를, Wikipedia 데이터셋에서는 68%를 N-gram 규칙셋으로 근사할 수 있었습니다. 이는 트랜스포머 모델의 예측이 단순한 통계적 규칙으로 상당 부분 설명될 수 있음을 시사합니다.
 그림 5: TinyStories 검증 시퀀스에 대한 규칙 선택 예시. 각 토큰 위치에서 트랜스포머 모델의 예측과 최적 규칙의 예측을 비교하여 보여줍니다. (출처: 원논문)
그림 5: TinyStories 검증 시퀀스에 대한 규칙 선택 예시. 각 토큰 위치에서 트랜스포머 모델의 예측과 최적 규칙의 예측을 비교하여 보여줍니다. (출처: 원논문)
연구의 의의와 한계
이 연구는 트랜스포머 기반 언어 모델의 예측이 어떻게 단순한 통계적 규칙으로 설명될 수 있는지에 대한 중요한 통찰을 제공합니다. 특히 모델 분산, 과적합의 통계적 특성, 커리큘럼 학습의 발생 등에 대한 새로운 발견들은 언어 모델의 작동 원리를 이해하는 데 큰 도움이 됩니다.
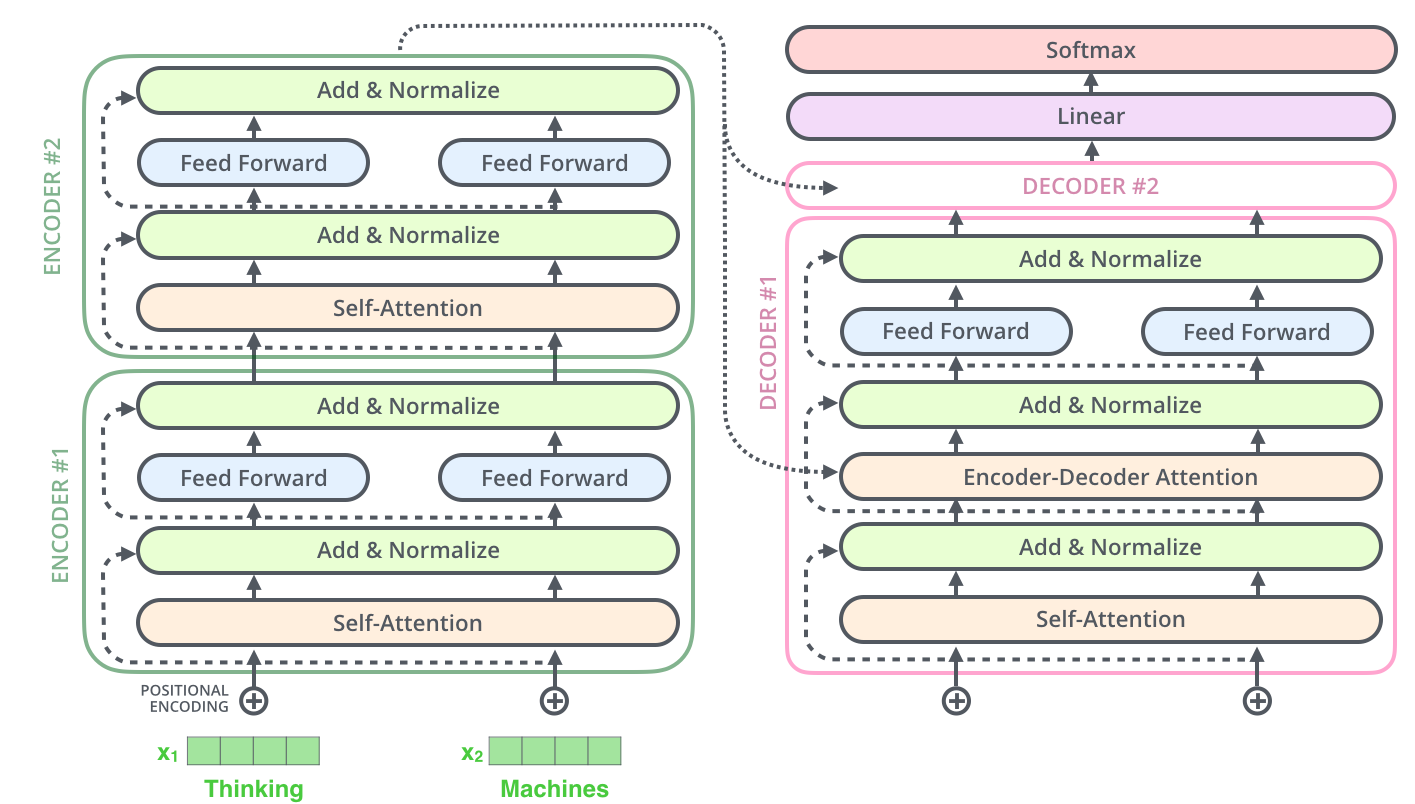
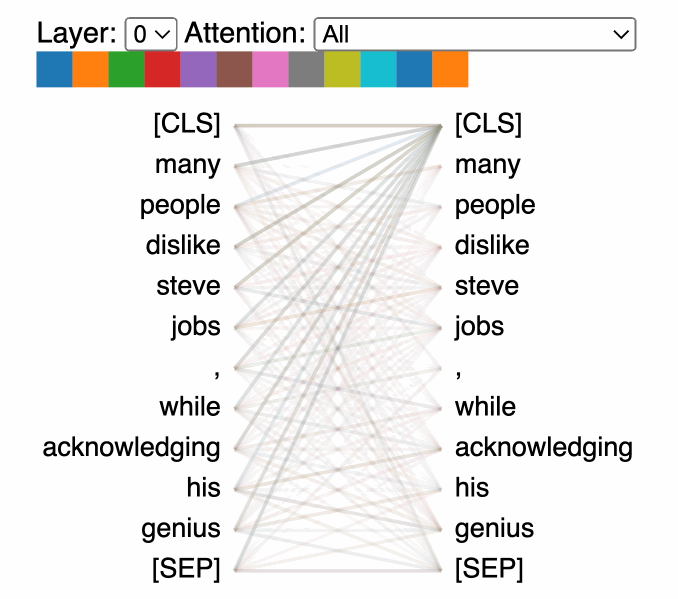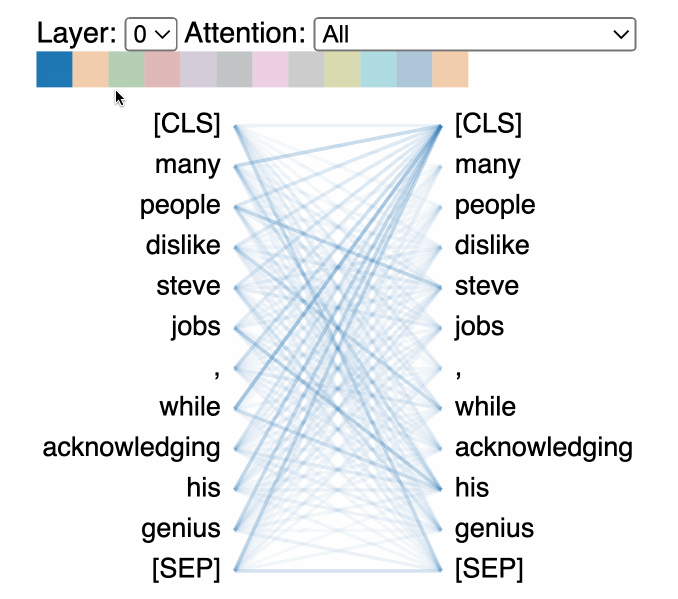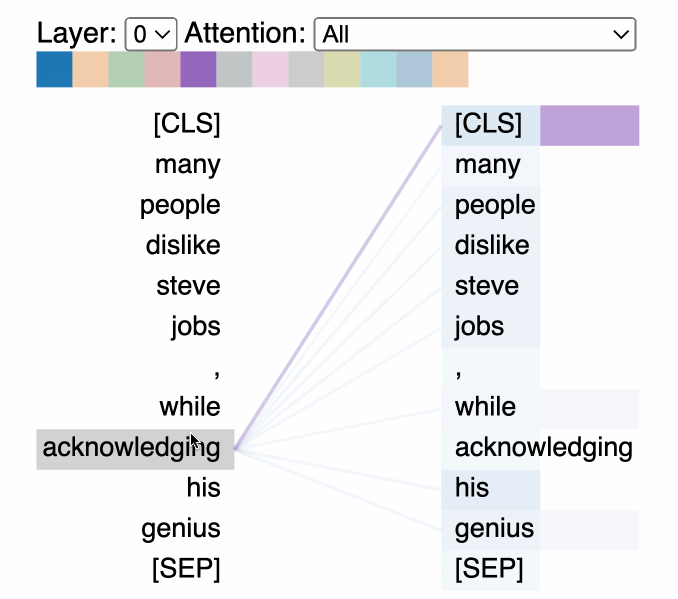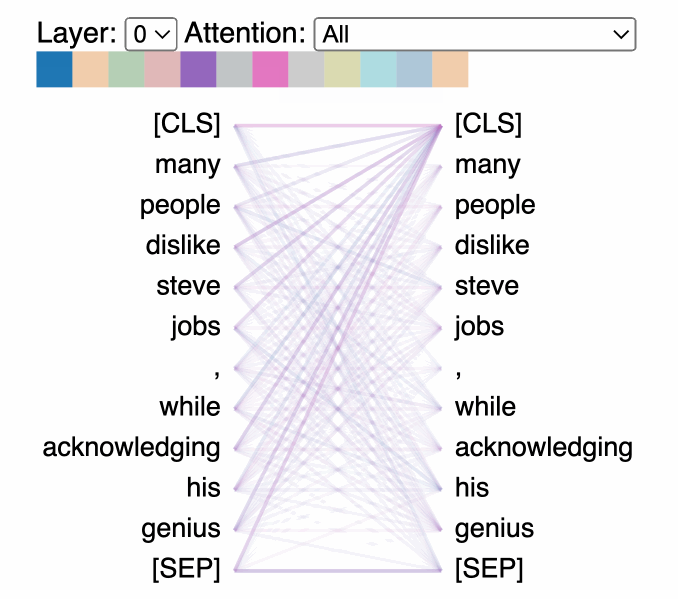 트랜스포머 모델의 어텐션 메커니즘을 시각화한 예시 (출처: Comet ML)
트랜스포머 모델의 어텐션 메커니즘을 시각화한 예시 (출처: Comet ML)
그러나 현재 최첨단 언어 모델들은 단순한 N-gram 규칙을 넘어서는 능력을 보이는 것이 사실입니다. 예를 들어, “수학에 관한 라임이 있는 30행의 시를 작성하라”와 같은 복잡한 요청에 대응하기 위해서는 단순한 토큰 수준의 연관성을 넘어서는 언어의 고수준 개념적 이해가 필요합니다.
저자는 앞으로의 연구 방향으로, 개별 토큰이 아닌 의미적 카테고리를 활용한 고수준 규칙 적용 방식을 탐구할 것을 제안합니다. 이는 현재의 설명적 근사화를 넘어 언어 모델의 작동 원리를 더 정확히 이해하는 데 도움이 될 것입니다.
결론
“Understanding Transformers via N-gram Statistics” 논문은 트랜스포머 모델이 문맥을 어떻게 이해하고 활용하는지에 대한 새로운 시각을 제공합니다. N-gram 통계에 기반한 간단한 규칙들이 모델 예측의 상당 부분을 설명할 수 있다는 사실은, AI 모델의 내부 작동에 대한 이해를 높이고 향후 더 강력하고 해석 가능한 AI 시스템을 개발하는 데 기여할 것입니다.
이러한 연구는 언어 모델이 단순한 ‘통계적 앵무새(stochastic parrots)’인지, 아니면 그 이상의 언어 이해 능력을 가지고 있는지에 대한 오랜 논쟁에도 새로운 관점을 제시합니다. 단순한 통계적 규칙으로 설명될 수 있는 부분이 상당하다는 점은 주목할 만하지만, 동시에 고수준 언어 처리 능력이 여전히 남아있다는 점도 분명합니다.
AI 기술이 계속 발전함에 따라, 이와 같은 기초적인 이해는 더 강력하고 신뢰할 수 있는 언어 모델을 개발하는 데 중요한 역할을 할 것입니다. 특히 이 연구가 제시하는 과적합 감지 방법은 AI 개발자들에게 실용적인 도구를 제공하며, N-gram 규칙으로 설명 가능한 모델 동작의 비율을 정량화하는 방법은 모델 해석에 새로운 길을 열어줄 것입니다.
답글 남기기