AI에이전트
루프가 코드를 쓰는 시대, Flask 창시자가 환영하지 못하는 이유
Flask 창시자 Armin Ronacher가 코딩 에이전트 위에 또 한 겹을 얹는 ‘루프’ 방식을 분석합니다. 어디서 통하고 어디서 위험한지, 그리고 ‘이해의 상실’이라는 우려를 짚습니다.
Written by

변호사도 Codex로 코딩한다, OpenAI가 공개한 직무 경계 붕괴 데이터
OpenAI가 공개한 1년간의 Codex 사용 데이터. 비개발자 채택이 137배 늘고, 비즈니스 직군 작업의 4분의 1이 코딩이었습니다. AI 에이전트가 직무 경계를 어떻게 허무는지 살펴봅니다.
Written by

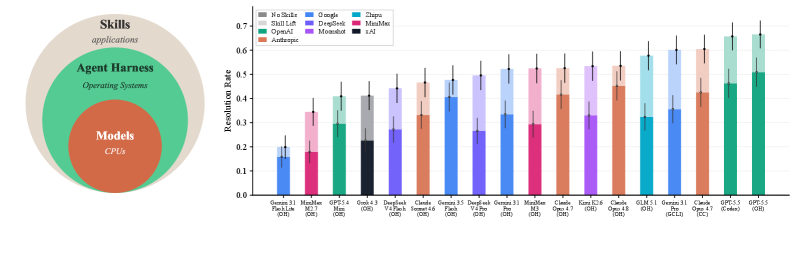
작은 AI 모델이 큰 모델을 따라잡는 방법, Skill 16.6%p의 비밀
잘 만든 Agent Skill은 AI 에이전트 정답률을 16.6%p 높이지만 모든 Skill이 도움되는 건 아닙니다. 87개 과제로 측정한 SkillsBench 연구와 좋은 Skill의 조건을 소개합니다.
Written by
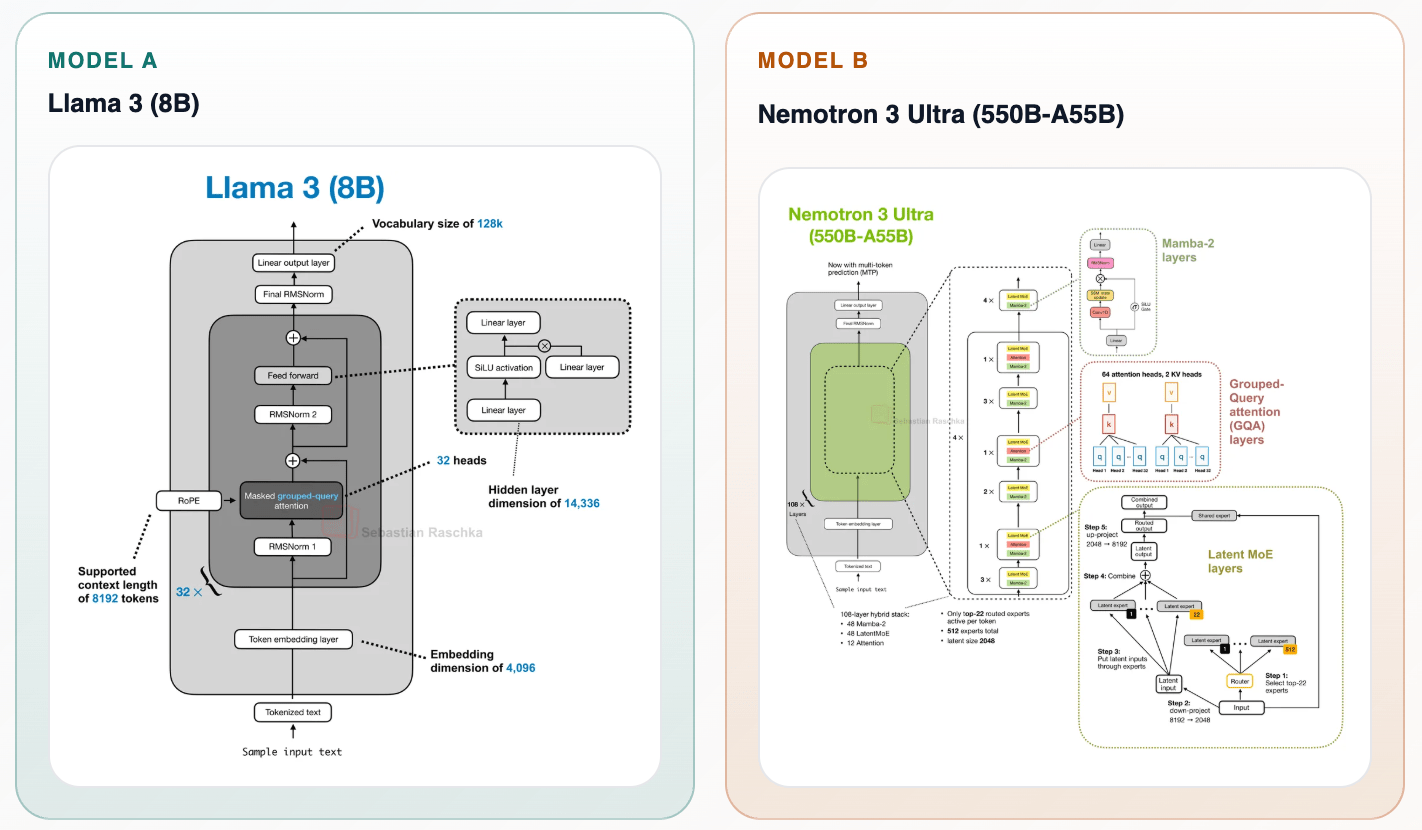
깔끔했던 Transformer가 복잡해진 이유, 그리고 에이전트의 한계
깔끔했던 Transformer가 어텐션 변종과 MoE로 복잡해진 이유, 그리고 AI 에이전트가 이 복잡성을 자동으로 풀 수 없는 까닭을 메타 출신 엔지니어 Ian Barber의 글로 풀어봅니다.
Written by
AI 에이전트는 왜 아직 사람이 필요한가, goose 팀의 자기개선 루프
“AI가 스스로 발전한다”는 유행 속에서 오픈소스 에이전트 goose 팀이 자기개선 루프에 여전히 사람을 끼워 넣는 이유. 벤치마크를 버그 리포트로 보는 관점을 소개합니다.
Written by
OpenAI Codex, 프롬프트 대신 시연으로 AI를 가르치는 Record & Replay
OpenAI가 macOS용 Codex에 Record & Replay를 추가했습니다. 작업을 한 번 시연하면 재사용 가능한 스킬로 만들어 반복하는 기능으로, 프롬프트 대신 시연으로 AI를 가르치는 방식을 소개합니다.
Written by

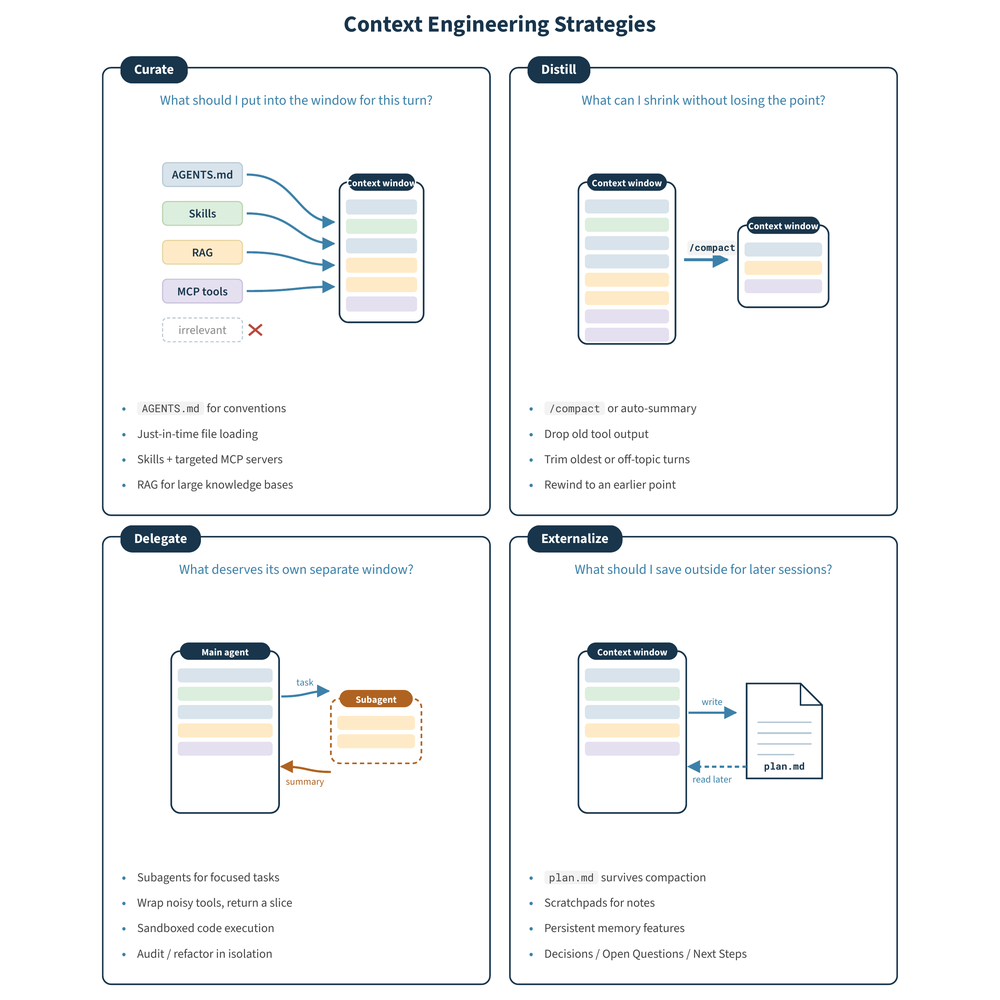
토큰 90% 절감의 함정, 컨텍스트는 줄이는 게 아니라 고르는 것
AI 에이전트의 토큰을 줄이는 두 접근을 비교합니다. 컨텍스트를 직접 선별하는 4가지 전략과, 자동 압축 도구 RTK가 가진 ‘조용한 실패’ 위험을 짚습니다.
Written by
AI 메모리는 RAG로 끝나지 않는다, 검색과 기억은 다른 문제다
“AI 메모리”는 단일 기능이 아니라 RAG·벡터·그래프 등 5개 층위입니다. 검색과 기억의 차이, 그리고 그래프 메모리가 보완하는 상태 관리 문제를 정리합니다.
Written by

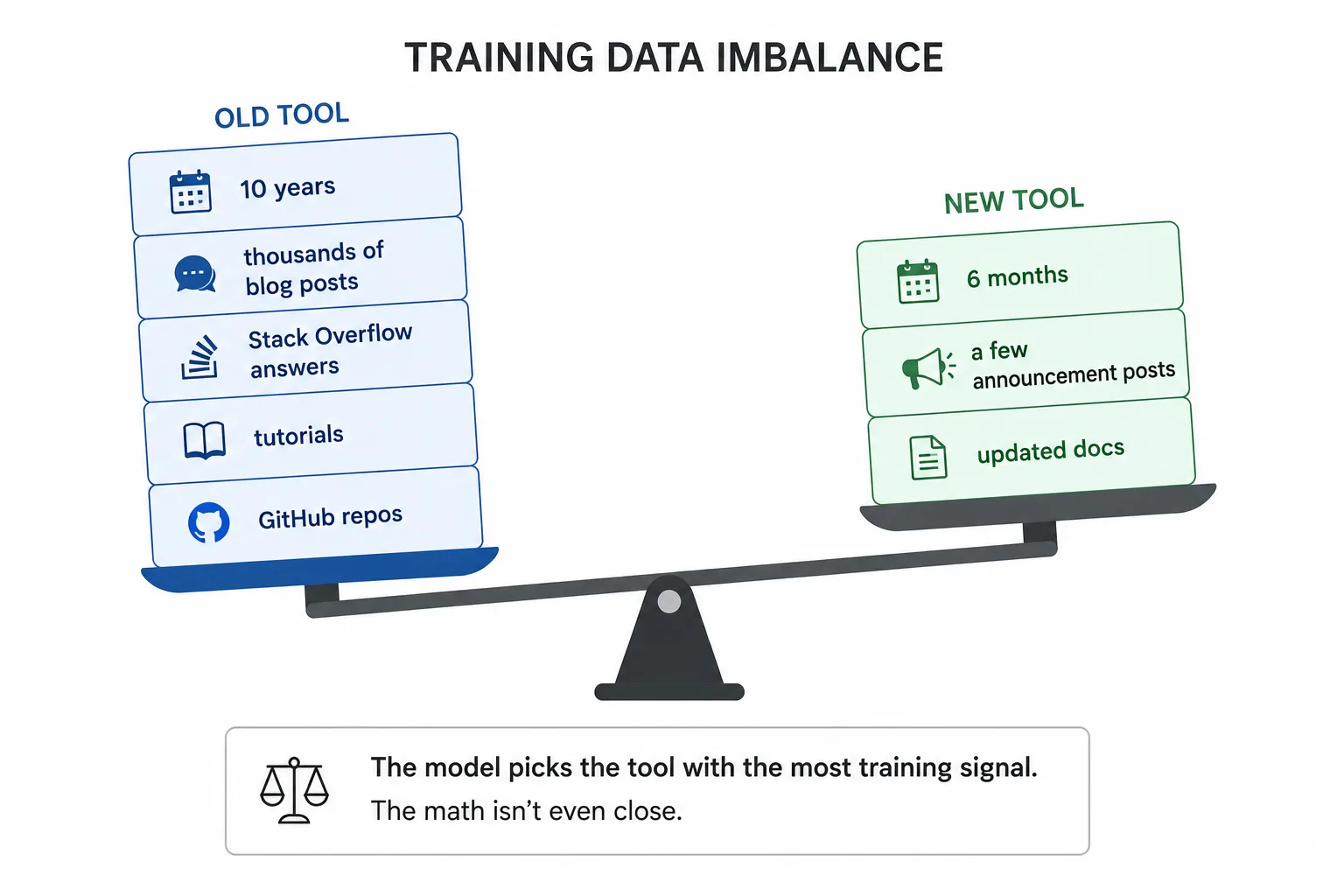
새 도구를 무시하는 AI 에이전트, 마이크로소프트가 밝힌 훈련 데이터 편향
AI 코딩 에이전트가 새 도구 대신 낡은 도구를 고집하는 이유를 마이크로소프트가 분석했습니다. 에이전트의 자신감은 최신성이 아닌 훈련 데이터 양에 비례한다는 통찰을 소개합니다.
Written by
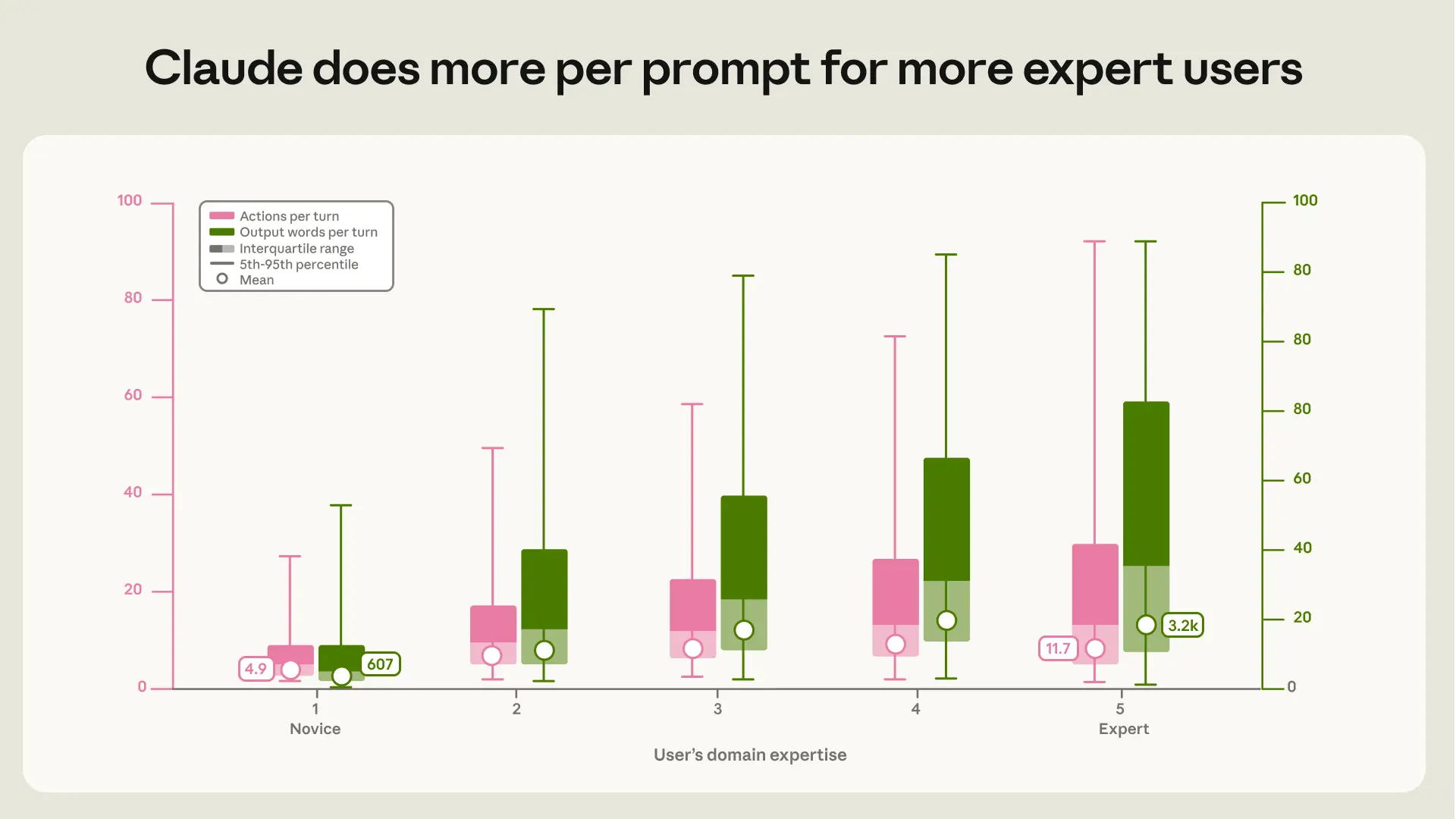
코딩 못해도 AI 에이전트는 잘 쓴다, 40만 세션이 말한 진짜 변수
약 40만 건의 Claude Code 세션 분석 결과, AI 코딩 에이전트의 성과를 가르는 변수는 코딩 실력이 아니라 도메인 전문성이었다는 Anthropic 연구를 소개합니다.
Written by