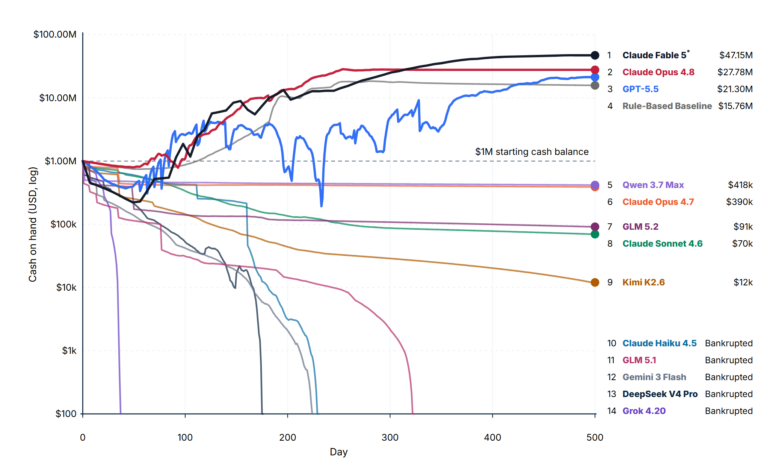
요즘 AI는 코딩이나 고객 응대 같은 개별 작업은 척척 해냅니다. 그렇다면 스타트업 경영처럼 훨씬 큰 일은 어떨까요? 가상의 회사를 통째로 맡겨 500일간 운영하게 하자, 14개 모델 중 시작 자본을 지켜낸 건 단 3개뿐이었고 나머지는 시뮬레이션이 끝나기도 전에 파산했습니다.

프린스턴 연구진(Haozhe Chen, Karthik Narasimhan, Sheng Liu)이 AI 에이전트의 장기 경영 능력을 측정하는 새 벤치마크 CEO-Bench를 공개했습니다. 가상의 구독형 소프트웨어 회사 ‘NovaMind’를 500일 동안 운영하게 한 뒤, 마지막에 남은 현금으로 성적을 매기는 방식입니다. 핵심 메시지는 분명합니다. 오늘의 AI는 개별 작업은 잘하지만, 조직 전체를 장기 목표로 끌고 가는 능력은 아직 멀었다는 것입니다.
출처: CEO-Bench: Can Agents Play the Long Game? – arXiv
CEO-Bench가 측정하려는 것, ‘방향타를 쥐는 지능’
연구진은 1997년 애플을 예로 듭니다. 파산 90일 전, 스티브 잡스는 소비자와 프로, 데스크톱과 휴대용으로 나눈 2×2 격자를 그리고 그 네 칸의 제품에만 집중하기로 결정했죠. 이후 iMac, iPod, iPhone이 따라왔습니다. 이렇게 조직을 장기 목표로 조타하는 능력을, 연구진은 개별 작업 수행과 구분되는 ‘방향타를 쥐는 지능(steering intelligence)’이라 부릅니다.
NovaMind는 고객 0명, 통장에 100만 달러를 가진 상태로 시작합니다. 잔액이 한 번이라도 0 밑으로 떨어지면 파산이고 시뮬레이션은 끝납니다. 에이전트는 34개의 도구와 19개 테이블로 된 데이터베이스를 파이썬 API로 다루는데, 단순히 명령을 하나씩 내리는 게 아니라 직접 코드를 짜고 SQL로 데이터를 조회하며 자기만의 업무 흐름을 만들어 회사를 운영합니다.
어려움의 핵심은 시간과 불확실성입니다. 비용은 즉시 빠져나가지만 매출은 청구일에야 들어오고, 잘못된 결정은 몇 주 뒤 고객 이탈이나 평판 손상으로 뒤늦게 드러납니다. 게다가 회사 상태의 상당 부분은 가려져 있습니다. 고객 만족도나 지불 의향을 직접 볼 수 없어, 취소·문의·소셜 반응 같은 잡음 섞인 신호로 추측해야 하죠. 경쟁사는 주기적으로 고객의 품질 기대치를 끌어올리고, 경기 사이클은 수요를 바꿉니다. 세상이 계속 변하는 셈입니다.
대부분 파산, 그리고 단순 규칙 봇의 반전
거의 모든 모델이 유효한 명령과 쿼리는 만들어냈지만, 시간이 흐르는 동안 일관된 전략을 유지하지는 못했습니다. 시작 자본 100만 달러를 넘긴 건 세 모델뿐입니다. Claude Fable 5가 $47.15M, Claude Opus 4.8이 $27.8M, GPT-5.5가 $21.3M을 기록했죠. 다만 단서가 있습니다. Fable 5는 한 번의 실행이 모델 거부로 중단됐고, 나머지 두 번은 일부 요청이 Opus 4.8로 넘어갔습니다. GPT-5.5는 세 번 중 두 번 파산했습니다. (논문 초록은 Opus 4.8과 GPT-5.5만 언급하는데, 기사 본문이 Fable 5를 포함한 최신 결과를 담고 있습니다.)
가장 뼈아픈 비교는 따로 있습니다. 언어 모델을 단 한 번도 호출하지 않는 단순 규칙 기반 봇이 $15.76M을 벌었습니다. 가격과 할당량을 고정해두고, 소수 고객 세그먼트에 광고와 개발을 집중하고, 최근 사용량에 맞춰 용량만 조절하는 이 봇이 상위 세 모델을 뺀 모든 AI를 이긴 겁니다. 참고로 연구진이 추정한 달성 가능 현금의 상한선은 약 22억 달러입니다. 최고 성적도 그 근처에 못 미쳤으니, 이 시험은 아직 한참 여유가 있는 셈입니다.
무엇이 성패를 갈랐나
결정 궤적을 분석하자 차이가 또렷하게 드러났습니다. GPT-5.5와 Opus 4.8은 상황이 바뀔 때마다 새 전략을 시도했습니다. 고객 확보를 늘리거나, 요금제를 손보거나, 지원·R&D 예산을 옮기는 식이었죠. 반면 Opus 4.7은 위기에 주로 비용을 줄이고 현금을 지키는 쪽으로 대응했습니다. 덕분에 끝까지 살아남긴 했지만, 이익은 내지 못했습니다. 탐색이 신중함을 이긴 셈입니다.
성공한 두 모델이 짠 코드는 꽤 정교했습니다. Opus 4.8은 고객 집단(코호트)을 모델링해 미래 현금 흐름을 예측하는 자체 시뮬레이션을 만들었고, GPT-5.5는 데이터베이스의 협상 기록을 파고들어 숨겨진 고객 선호를 캐냈습니다. 연구진이 꼽은 성공과 연관된 네 가지 능력, 곧 숨은 정보 발굴, 미래 예측, 빠른 적응, 앞을 내다본 계획에서 두 모델은 나머지 평균을 모두 웃돌았습니다.
흥미로운 발견이 하나 더 있습니다. 연구진이 Opus 4.7에 Claude Code를, GPT-5.5에 Codex를 붙여봤더니 두 경우 모두 행동 빈도가 줄고 성적이 나빠졌습니다. 소프트웨어 개발용으로 튜닝된 시스템 프롬프트가 경영이라는 다른 종류의 장기 과제에는 오히려 발목을 잡았다는 추정입니다.
로컬 능력과 장기 전략 사이의 간극
CEO-Bench가 드러낸 것은 오늘의 AI가 가진 능력의 모양입니다. 도구를 다루고 코드를 짜는 국소적 능력은 이미 상당하지만, 그 행동들을 긴 시간에 걸쳐 하나의 일관된 전략으로 엮는 능력은 그렇지 못합니다. 시뮬레이션을 50일로 줄여도 문제는 풀리지 않았습니다. 그 짧은 기간에 이익을 낸 건 GPT-5.5 하나뿐이었죠. 단기 목표를 향한 의사결정 조율조차 대부분의 모델에겐 아직 어려운 일이라는 뜻입니다. 에이전트에게 무엇을 맡길 수 있고 무엇은 아직 이른지, 그 경계를 가늠하는 데 흥미로운 참고점이 되어줍니다.
답글 남기기