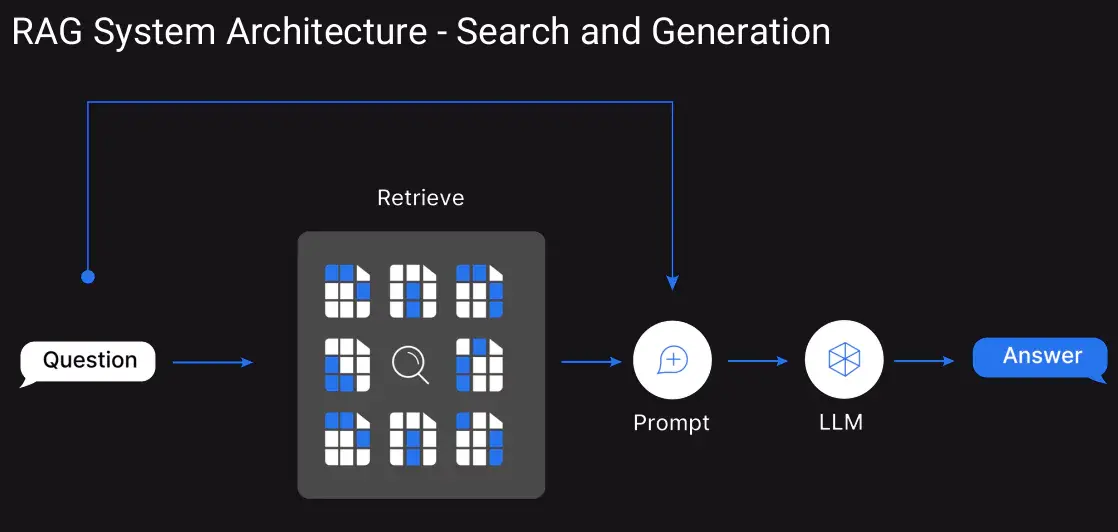

검색 증강 생성(RAG) 시스템을 운영하다 보면 한 가지 공통적인 고민에 직면하게 됩니다. 분명 관련 정보는 검색되는데, 정작 LLM이 생성하는 답변의 품질이 기대에 못 미치는 경우가 많다는 것이죠. 벡터 검색으로 상위 10개 문서를 가져왔는데, 정말 중요한 정보는 7번째나 8번째에 숨어있어서 LLM이 놓치는 상황이 발생합니다.
이런 문제를 해결하는 핵심 기술이 바로 재순위 지정(Reranking)입니다. 단순히 더 많은 문서를 검색하는 것이 아니라, 검색된 문서들 중에서 진짜 중요한 정보를 맨 앞으로 배치하는 똑똑한 방법이죠.
왜 초기 검색만으로는 부족할까요?
RAG 시스템의 첫 번째 단계는 사용자 질문과 관련된 문서를 찾는 것입니다. 대부분 벡터 유사도나 키워드 검색을 사용하죠. 하지만 이 방법들에는 근본적인 한계가 있습니다.
벡터 검색의 한계점들:
- 긴 문서를 고정된 차원의 벡터로 압축하면서 정보 손실 발생
- 짧은 쿼리나 전문 용어에 대한 이해 부족
- 근사 최근접 이웃 검색(ANN)으로 인한 정확도 저하
더 심각한 문제는 LLM의 “Lost in the Middle” 현상입니다. 연구에 따르면 LLM은 맨 앞이나 맨 뒤에 있는 정보는 잘 활용하지만, 중간에 위치한 정보는 상당히 놓치는 경향이 있습니다. 아무리 관련성 높은 문서라도 컨텍스트 중간에 배치되면 답변 품질이 크게 떨어지는 것이죠.

재순위 지정이 RAG를 혁신하는 방법
재순위 지정 모델은 이런 문제를 근본적으로 해결합니다. 기존 벡터 검색이 질문과 문서를 따로따로 인코딩하는 바이-인코더(Bi-encoder) 방식이라면, 리랭커는 질문과 문서를 함께 분석하는 크로스-인코더(Cross-encoder) 방식을 사용합니다.

재순위 지정의 핵심 장점:
- 질문과 문서 간의 상호작용을 직접적으로 분석
- 키워드 매칭을 넘어선 의미적 관련성 파악
- LLM 환각(Hallucination) 현상 대폭 감소
- 더 적은 문서로도 높은 정확도 달성
실제 작동 방식은 다음과 같습니다:
- 1단계 검색: 벡터 검색으로 후보 문서 25개 추출 (광범위한 검색)
- 재순위 지정: 리랭커가 각 문서의 관련성을 정밀 분석
- 최종 선별: 상위 3-5개 문서만 LLM에 전달 (정밀한 선별)

2025년 주목받는 재순위 지정 모델 7선
현재 시장에서 주목받는 주요 모델들을 상용/오픈소스별로 분류하여 살펴보겠습니다.
상용 모델: 즉시 사용 가능한 고성능 솔루션
1. Cohere Rerank – 기업용 최적화
Cohere Rerank는 100개 이상의 언어를 지원하는 강력한 상용 모델입니다. 특히 한국어 지원이 뛰어나며, API 기반으로 쉽게 통합할 수 있습니다.
핵심 특징:
- Rerank 3 Nimble: 속도 최적화 버전으로 실시간 서비스에 적합
- 다국어 지원: 100개 이상 언어 공식 지원
- 간편한 통합: REST API를 통한 즉시 사용 가능
from langchain_cohere import CohereRerank
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
compressor = CohereRerank(model="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=retriever
)적합한 용도: 다국어 서비스, 엔터프라이즈 환경, 빠른 프로토타이핑
2. Voyage Rerank – 최고 정확도 추구
Voyage AI의 리랭커는 벤치마크에서 최상위 성능을 보여주는 모델입니다. 정확도가 가장 중요한 애플리케이션에 적합합니다.
핵심 특징:
- voyage-rerank-2: 벤치마크 1위급 성능
- voyage-rerank-2-lite: 성능과 속도의 균형
- 정밀한 관련성 점수: 미세한 의미 차이도 구분
적합한 용도: 금융, 법률, 의료 등 정확도가 중요한 도메인
오픈소스 모델: 자유로운 커스터마이징
3. BGE-Reranker – 오픈소스의 강자
베이징 인공지능연구원(BAAI)에서 개발한 오픈소스 모델로, 상용 모델에 근접한 성능을 제공합니다.
핵심 특징:
- Apache 2.0 라이선스: 상업적 이용 가능
- 다양한 크기: Base(600M), Large(1.5B) 파라미터 버전
- 자체 호스팅: 데이터 프라이버시 완전 보장
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
from langchain.retrievers.document_compressors import CrossEncoderReranker
model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(model=model, top_n=3)적합한 용도: 예산 제약이 있는 프로젝트, 데이터 보안이 중요한 환경
4. FlashRank – 속도의 혁신
FlashRank는 속도에 최적화된 경량 모델입니다. CPU 환경에서도 빠른 처리가 가능하여 실시간 서비스에 적합합니다.
핵심 특징:
- 초고속 처리: CPU 환경에서도 밀리초 단위 응답
- 저사양 호환: 엣지 디바이스에서도 동작
- 간단한 통합: 최소한의 코드로 적용 가능
적합한 용도: 실시간 채팅봇, 리소스 제약 환경, 대용량 트래픽 처리
5. MixedBread AI – 차세대 오픈소스
2025년 주목받는 신예 모델로, 강화학습을 적용한 3단계 훈련 방식으로 SOTA 성능을 달성했다고 주장합니다.
핵심 특징:
- mxbai-rerank-large-v2: 1.5B 파라미터, 벤치마크 최고 점수
- 긴 컨텍스트 지원: 최대 32K 토큰까지 처리
- 다양한 데이터 타입: 텍스트, 코드, JSON 모두 지원
from mxbai_rerank import MxbaiRerankV2
model = MxbaiRerankV2("mixedbread-ai/mxbai-rerank-base-v2")
results = model.rank(query, documents)적합한 용도: 최신 기술 도입, 코드 검색, 긴 문서 처리
특수 목적 모델들
6. ColBERT – 대규모 데이터 전문
ColBERT는 멀티벡터 방식을 사용하여 대규모 문서 컬렉션에서 효율적인 검색을 제공합니다.
핵심 특징:
- Late Interaction: 사전 인덱싱으로 빠른 검색
- 확장성: 수백만 문서 대상 실시간 검색
- 정밀한 매칭: 토큰 단위 세밀한 비교
적합한 용도: 대규모 지식베이스, 기업 문서 검색 시스템
7. Jina Reranker – 장문서 전문가
Jina AI의 리랭커는 특히 긴 문서 처리에 강점을 보입니다.
핵심 특징:
- Jina-ColBERT: 8,000 토큰까지 처리 가능
- 균형잡힌 성능: 비용 대비 우수한 성능
- 실용적 접근: 실무 환경에 최적화
적합한 용도: 기술 문서, 연구 논문, 법률 문서 검색
모델 성능 비교표
| 모델 | 타입 | 라이선스 | 강점 | 약점 | 최적 용도 |
|---|---|---|---|---|---|
| Cohere Rerank | API | 상용 | 높은 정확도, 다국어, 빠른 속도 | API 비용, 클로즈드소스 | 기업용, 다국어, 프로덕션 |
| BGE-Reranker | 오픈소스 | Apache 2.0 | 높은 정확도, 무료, 커스터마이징 | 자체 호스팅 필요 | 예산 제약, 보안 중시 |
| Voyage Rerank | API | 상용 | 최고 정확도 | 비용, 레이턴시 | 금융, 법률, 의료 |
| MixedBread | 오픈소스 | Apache 2.0 | SOTA 성능, 긴 컨텍스트, 다목적 | 상대적으로 신규 | 최신 기술, 코드 검색 |
| FlashRank | 오픈소스 | Apache 2.0 | 초고속, 경량 | 정확도 제한 | 실시간, 저사양 환경 |
| ColBERT | 오픈소스 | Apache 2.0 | 대규모 효율성 | 인덱싱 비용 | 대규모 문서 셋 |
| Jina Reranker | 혼합 | 혼합 | 균형잡힌 성능, 긴 문서 | 최고 정확도 아님 | 일반적 RAG, 긴 문서 |
재순위 지정 모델 성능 측정하기
리랭커의 효과를 제대로 측정하려면 적절한 평가 지표를 사용해야 합니다.
핵심 평가 지표들
1. Hit Rate@k
- 상위 k개 결과에 관련 문서가 포함되는 비율
- 예: Hit Rate@5 = 80%는 상위 5개 중 관련 문서가 80% 확률로 포함
2. Mean Reciprocal Rank (MRR)
- 첫 번째 관련 문서가 나타나는 순위의 역수 평균
- 높을수록 중요한 정보가 앞쪽에 배치됨을 의미
3. Normalized Discounted Cumulative Gain (NDCG)
- 순위와 관련성을 모두 고려한 종합 지표
- 0과 1 사이 값으로, 1에 가까울수록 우수
4. Precision@k / Recall@k
- 정밀도: 상위 k개 중 관련 문서 비율
- 재현율: 전체 관련 문서 중 상위 k개에 포함된 비율
실제 평가 결과 예시
AWS 한국 블로그에서 공개한 한국어 리랭커 성능 평가 결과를 보면:
| 지표 | 리랭커 미사용 | 리랭커 사용 | 개선율 |
|---|---|---|---|
| Hit Rate@5 | 0.68 | 0.84 | +23.5% |
| MRR | 0.51 | 0.71 | +39.2% |
| NDCG@5 | 0.59 | 0.78 | +32.2% |
이 결과는 리랭커 적용 시 모든 지표에서 상당한 개선을 보여줍니다.
리랭커 기술의 한계점과 단점
리랭커가 RAG 성능을 크게 향상시키는 것은 사실이지만, 도입 전에 반드시 고려해야 할 단점들도 있습니다.
성능과 비용 측면의 트레이드오프
1. 응답 지연 시간 증가
- 기존 RAG: 벡터 검색 → LLM 생성 (약 500ms)
- 리랭커 적용: 벡터 검색 → 리랭킹 → LLM 생성 (약 800-1200ms)
- 실시간 챗봇이나 대화형 서비스에서는 사용자 체감 지연 발생 가능
2. 계산 비용 급증
- 상용 API: 문서 수에 비례한 API 호출 비용 (월 수백만원 추가 가능)
- 자체 호스팅: GPU 인스턴스 상시 운영 비용 (월 50-200만원)
- 대용량 트래픽 환경에서는 기존 인프라 비용의 30-50% 추가 부담
3. 인프라 복잡성 증가
# 기존 단순한 RAG 파이프라인
query → vector_search → llm_generation → response
# 리랭커 도입 후 복잡해진 파이프라인
query → vector_search → reranking_api_call → error_handling
→ fallback_logic → llm_generation → response기술적 제약사항들
4. 완벽하지 않은 성능
- 리랭커도 결국 ML 모델이므로 오판 가능성 존재
- 특히 도메인별 전문 용어나 최신 정보에 대한 이해 부족
- 때로는 리랭킹 후 오히려 관련성이 떨어지는 문서가 상위로 올라오는 경우 발생
5. 언어별 성능 편차
- 영어: 대부분 모델에서 우수한 성능
- 한국어: 일부 모델은 성능 저하 (특히 오픈소스 모델)
- 전문 도메인 한국어: 추가 파인튜닝 없이는 성능 제한적
6. 확장성 한계
- Cross-encoder 방식의 근본적 한계로 문서 수 증가 시 처리 시간 급증
- 100개 문서 리랭킹: 100ms
- 1000개 문서 리랭킹: 1000ms+ (선형적 증가)
운영상의 어려움
7. 의존성 위험
- 상용 API 서비스 장애 시 전체 시스템 마비
- 가격 정책 변경이나 서비스 중단 위험
- 특정 벤더에 대한 종속성 심화
8. 모니터링과 디버깅의 복잡성
# 문제 발생 시 원인 파악이 어려움
def debug_rag_with_reranker():
# 1. 벡터 검색 문제인가?
# 2. 리랭커 문제인가?
# 3. LLM 문제인가?
# 4. 각 단계별 성능 측정과 로깅 필요
pass9. 데이터 프라이버시 우려
- 상용 API 사용 시 민감한 문서 내용이 외부 서버로 전송
- GDPR, 개인정보보호법 등 규제 준수 복잡성 증가
- 금융, 의료 등 보안이 중요한 도메인에서는 사용 제약
도입 시기와 투자 대비 효과
10. 모든 상황에서 필요하지 않음
- 단순한 FAQ나 정형화된 질문: 리랭커 효과 미미
- 문서 수가 적은 소규모 지식베이스: 오버엔지니어링 위험
- 정확도보다 속도가 중요한 서비스: 비용 대비 효과 부족
리랭커 도입 전 체크리스트
리랭커 도입을 고려한다면 다음을 먼저 확인해보세요:
✅ 현재 RAG 성능이 정말 부족한가?
- 사용자 만족도 70% 미만
- 잘못된 답변 비율 20% 이상
- 관련 정보를 찾지 못하는 경우 30% 이상
✅ 추가 비용을 감당할 수 있는가?
- 월 운영비 30-50% 증가 가능
- 개발 및 유지보수 인력 투입 필요
- 인프라 복잡성 증가에 따른 관리 비용
✅ 응답 지연을 허용할 수 있는가?
- 실시간 대화: 500ms 추가 지연 감수 가능한지
- 배치 처리: 처리 시간 2-3배 증가 허용 가능한지
✅ 대안책을 먼저 시도했는가?
- 임베딩 모델 개선 (더 나은 모델로 교체)
- 청킹 전략 최적화 (문서 분할 방식 개선)
- 하이브리드 검색 도입 (키워드 + 벡터 검색)
프로젝트에 맞는 리랭커 선택 가이드
용도별 추천 모델
🚀 빠른 프로토타이핑이 필요하다면
- 추천: Cohere Rerank
- 이유: API 기반으로 즉시 사용 가능, 안정적인 성능
💰 예산이 제한적이라면
- 추천: BGE-Reranker Base
- 이유: 오픈소스, 상용 모델에 근접한 성능
🔧 기존 시스템 최적화를 먼저 시도한다면
- 추천: 임베딩 모델 업그레이드 + 하이브리드 검색
- 이유: 리랭커보다 저비용으로 상당한 성능 향상 가능
⚡ 실시간 응답이 절대적으로 중요하다면
- 추천: FlashRank
- 이유: 밀리초 단위 처리, CPU 환경 최적화
🎯 최고 정확도가 필요하다면
- 추천: Voyage Rerank 2 또는 MixedBread Large
- 이유: 벤치마크 최상위 성능
📚 대규모 문서 처리가 필요하다면
- 추천: ColBERT
- 이유: 확장성 뛰어남, 사전 인덱싱으로 빠른 검색
📄 긴 문서를 주로 다룬다면
- 추천: Jina-ColBERT 또는 MixedBread
- 이유: 8K-32K 토큰까지 처리 가능
선택 시 고려사항
성능 vs 비용 vs 속도 트레이드오프
| 접근법 | 성능 향상 | 추가 비용 | 지연 시간 | 복잡성 |
|---|---|---|---|---|
| 임베딩 모델 업그레이드 | +15-25% | 낮음 | 거의 없음 | 낮음 |
| 하이브리드 검색 | +20-30% | 낮음 | 미미 | 중간 |
| 경량 리랭커 (FlashRank) | +25-35% | 중간 | +50-100ms | 중간 |
| 고성능 리랭커 (Cohere) | +30-50% | 높음 | +200-500ms | 높음 |
응답 속도 요구사항별 권장사항
- 상용 모델: 높은 성능 + 운영 편의성, 하지만 지속적인 API 비용
- 오픈소스: 초기 구축 비용 + 운영 부담, 하지만 장기적으로 경제적
응답 속도 요구사항
- 실시간 채팅: FlashRank (< 10ms)
- 일반 검색: Cohere Nimble (< 50ms)
- 배치 처리: BGE-Reranker (성능 우선)
데이터 보안 수준
- 높은 보안: 자체 호스팅 오픈소스 모델 필수
- 일반적 수준: 상용 API 서비스 활용 가능
실제 구현 시 주의사항
성공적인 리랭커 도입을 위한 팁
1. 단계적 도입
# 1단계: 기존 시스템에 리랭커 추가
basic_retriever = VectorStoreRetriever(...)
reranker = CohereRerank()
enhanced_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=basic_retriever
)
# 2단계: A/B 테스트로 성능 비교
# 3단계: 최적 설정 찾기2. 적절한 문서 수 설정
- 1차 검색: 20-50개 문서 (충분한 후보 확보)
- 리랭킹 후: 3-7개 문서 (LLM 컨텍스트 최적화)
- ⚠️ 주의: 문서 수가 많을수록 리랭킹 비용과 시간 급증
3. 성능 저하 시 대응 방안
class FallbackRAGSystem:
def __init__(self):
self.reranker = CohereRerank()
self.fallback_threshold = 500 # ms
def search_with_fallback(self, query, documents):
try:
start_time = time.time()
reranked = self.reranker.rerank(query, documents)
# 응답 시간이 임계치 초과 시 기본 검색으로 폴백
if (time.time() - start_time) > self.fallback_threshold:
return self.basic_search(query, documents)
return reranked
except Exception:
# API 오류 시 기본 검색으로 폴백
return self.basic_search(query, documents)4. 비용 최적화 전략
- 캐싱 활용: 동일 쿼리-문서 조합에 대한 리랭킹 결과 저장
- 배치 처리: 여러 쿼리를 묶어서 처리하여 API 호출 최소화
- 조건부 리랭킹: 단순한 쿼리는 리랭킹 생략, 복잡한 쿼리만 적용
3. 지속적인 모니터링
- 사용자 만족도 조사
- 답변 정확도 평가
- 응답 시간 모니터링
- 리랭킹 비용 추적: 월별 API 호출 수와 비용 모니터링
- 장애 대응 준비: 리랭커 서비스 장애 시 자동 폴백 시스템 구축
RAG의 미래와 재순위 지정 기술
재순위 지정 기술은 분명 RAG 시스템의 성능을 크게 향상시킬 수 있는 강력한 도구입니다. 하지만 만능 해결책은 아닙니다. 도입 전에 현재 시스템의 문제점을 정확히 파악하고, 비용 대비 효과를 신중히 검토해야 합니다.
특히 한국 시장에서는 언어적 특성과 도메인별 요구사항을 고려한 전용 모델 개발이 활발히 진행되고 있습니다. AWS, 네이버클라우드, 카카오 등 주요 클라우드 제공업체들도 한국어 최적화된 리랭킹 서비스를 지속적으로 발전시키고 있어, 앞으로는 더욱 실용적이고 경제적인 솔루션들이 등장할 것으로 예상됩니다.
리랭커 도입 결정을 위한 최종 가이드:
- 현재 시스템 진단: 기본적인 최적화부터 시작
- 점진적 도입: 일부 사용 사례부터 테스트 적용
- 성능 vs 비용 균형: 무조건 최고 성능보다는 적정 수준 목표
- 장기적 관점: 기술 발전과 비용 하락 추세 고려
리랭커는 RAG 시스템을 한 단계 발전시킬 수 있는 핵심 기술이지만, 신중한 도입 계획과 지속적인 최적화가 뒷받침되어야 진정한 가치를 발휘할 수 있습니다.
참고자료:
답글 남기기