AI 에이전트가 모든 산업을 바꿀 거라고들 합니다. 그런데 실제 데이터를 보면, 지금 에이전트가 하는 일의 절반은 코딩입니다.

Anthropic이 Claude Code와 공개 API에서 발생한 수백만 건의 실제 인터랙션을 분석한 연구를 발표했습니다. 에이전트가 얼마나 자율적으로 작동하는지, 사람들이 어떤 방식으로 감독하는지, 그리고 어떤 분야에서 쓰이는지를 실제 데이터로 들여다본 첫 번째 대규모 연구입니다. 에이전트는 빠르게 자율화되고 있지만, 아직 소프트웨어 개발이라는 울타리 밖으로는 거의 나가지 못했습니다.
출처: Measuring AI agent autonomy in practice – Anthropic
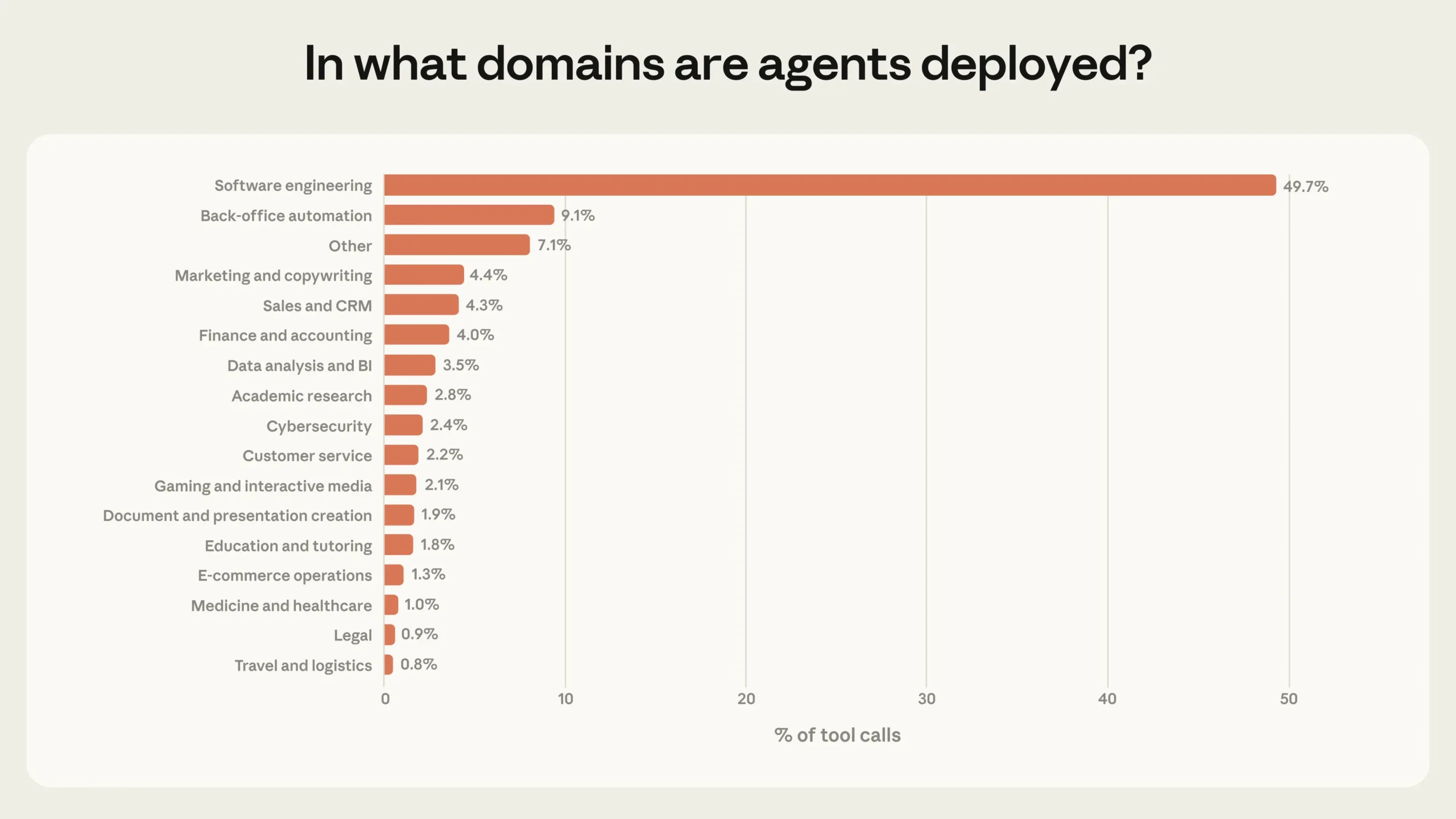
에이전트 활동의 절반은 코딩
공개 API에서 발생하는 전체 에이전트 툴 호출의 약 50%가 소프트웨어 엔지니어링에서 나옵니다. 비즈니스 인텔리전스, 고객 서비스, 영업, 금융, 이커머스가 그 뒤를 잇지만, 각각의 비중은 몇 퍼센트 수준에 머뭅니다.
Anthropic은 이를 “에이전트 도입 초기 단계”로 규정합니다. 소프트웨어 개발자들이 가장 먼저 에이전트 기반 도구를 구축하고 대규모로 활용했고, 다른 산업은 이제 막 실험을 시작하는 단계라는 해석입니다. 코딩 작업이 에이전트에 특히 적합한 이유도 있습니다. 코드는 실행해보면 바로 결과가 나오기 때문에 신뢰를 쌓고 실수를 잡아내기가 상대적으로 쉽습니다. 법률, 의료, 금융처럼 결과물을 검증하는 데 전문성이 필요한 분야에서는 같은 수준의 신뢰 형성이 훨씬 더디게 진행될 수 있습니다.
가장 긴 작업, 3개월 만에 2배
Claude Code가 사람의 개입 없이 혼자 작업하는 시간은 얼마나 될까요? 중간값은 45초로 비교적 안정적이지만, 가장 긴 세션들이 눈에 띄게 늘고 있습니다. 2025년 10월부터 2026년 1월까지 3개월 동안, 상위 0.1%에 해당하는 세션의 최대 연속 작업 시간이 25분 미만에서 45분 이상으로 거의 2배 늘었습니다.
이 증가가 새 모델 출시 시점마다 급등하는 패턴이 아니라 완만하게 꾸준히 올라간다는 점도 주목할 만합니다. 모델 성능 향상만으로는 설명이 안 된다는 뜻이고, Anthropic은 그 이유를 사용자들이 쌓아가는 신뢰, 더 야심 찬 과제를 맡기는 방식의 변화, 그리고 제품 자체의 지속적인 개선이 복합적으로 작용한 결과로 봅니다.
Anthropic은 여기서 “배포 과잉(deployment overhang)”이라는 개념을 꺼냅니다. 모델이 실제로 처리할 수 있는 자율성 수준이, 현재 사람들이 실제로 허용하는 수준보다 높다는 뜻입니다. 쉽게 말하면, Claude는 더 많이 할 수 있는데 사람들이 아직 그만큼 맡기지 않고 있다는 겁니다.
숙련 사용자는 더 많이 맡기고, 더 자주 개입한다
처음 Claude Code를 쓰는 사용자의 약 20%만이 전체 자동 승인 모드를 사용합니다. 750회 정도 세션을 경험한 숙련 사용자는 이 비율이 40% 이상으로 올라갑니다. 동시에 중간에 Claude를 멈추는 개입 비율도 5%에서 9%로 높아집니다.
얼핏 모순처럼 보이지만, 이는 감독 방식이 바뀐 것입니다. 초보 사용자는 Claude가 취하는 행동 하나하나를 미리 승인하는 방식으로 통제하고, 숙련 사용자는 Claude를 자율로 돌리다가 뭔가 잘못되면 개입하는 방식으로 전환합니다. 사전 승인에서 사후 모니터링으로의 이동이죠.
공개 API에서도 비슷한 패턴이 나타납니다. 코드 한 줄을 수정하는 단순 작업의 경우 87%에서 사람이 개입하지만, 제로데이 취약점을 찾거나 컴파일러를 작성하는 복잡한 작업에서는 그 비율이 67%로 낮아집니다.
Claude가 사람보다 더 자주 스스로 멈춘다
연구에서 가장 눈에 띄는 발견 중 하나는 Claude가 스스로 작업을 멈추고 확인을 요청하는 빈도입니다. 복잡한 작업일수록 Claude가 사람보다 더 자주 멈춥니다. 가장 복잡한 작업에서 Claude의 자발적 중단은 사람의 개입보다 2배 이상 많습니다.
Claude가 멈추는 이유 중 가장 많은 건 여러 접근 방식 중 선택을 요청하는 경우(35%)였고, 진단 정보나 테스트 결과 수집(21%), 불명확한 요청 명확화(13%) 등이 뒤를 이었습니다. Anthropic은 이를 중요한 안전 메커니즘으로 봅니다. 모델이 자신의 불확실성을 스스로 인식하고 확인을 요청하도록 훈련하는 것이 외부 승인 시스템이나 인간 감독과 함께 작동하는 보완적 안전장치라는 겁니다.
에이전트가 고위험 영역으로 확장된다면
Anthropic은 에이전트 도입 초기임에도 불구하고 이미 보안, 금융, 의료 같은 고위험 영역에서의 사용이 감지된다고 밝힙니다. 아직 규모는 작지만, 소프트웨어 엔지니어링에서 다른 산업으로 확장되면서 위험과 자율성의 경계선이 점점 넓어질 거라는 전망입니다.
정책 측면에서 Anthropic은 한 가지 명확한 입장을 냅니다. 모든 에이전트 행동마다 사전 승인을 요구하는 규정은 실질적인 안전 효과 없이 마찰만 키운다는 것입니다. 중요한 건 특정 상호작용 방식을 강제하는 게 아니라, 사람이 에이전트를 효과적으로 모니터링하고 필요할 때 개입할 수 있는 위치에 있는지 여부라고 강조합니다.
에이전트가 스스로 한계를 인식하고, 사용자가 경험을 쌓으면서 적절한 감독 방식을 찾아가고, 제품이 이를 지원하는 구조로 발전하는 것—Anthropic은 이 세 가지의 상호작용이 실제 에이전트 자율성을 결정한다고 봅니다.
원문에는 위험-자율성 분포 시각화, 상세 방법론, 모델·제품·정책 개발자를 위한 권고사항도 담겨 있습니다.
답글 남기기