RAG
GPT-5도 모르는 마지막 20%, 도메인 특화 검색 에이전트의 등장
기존 검색 스택의 한계와 에이전트 기반 검색으로의 전환을 소개합니다. GPT-5가 채우지 못하는 도메인 특수성과, 이를 해결할 특화 소형 모델의 등장을 정리했습니다.
Written by
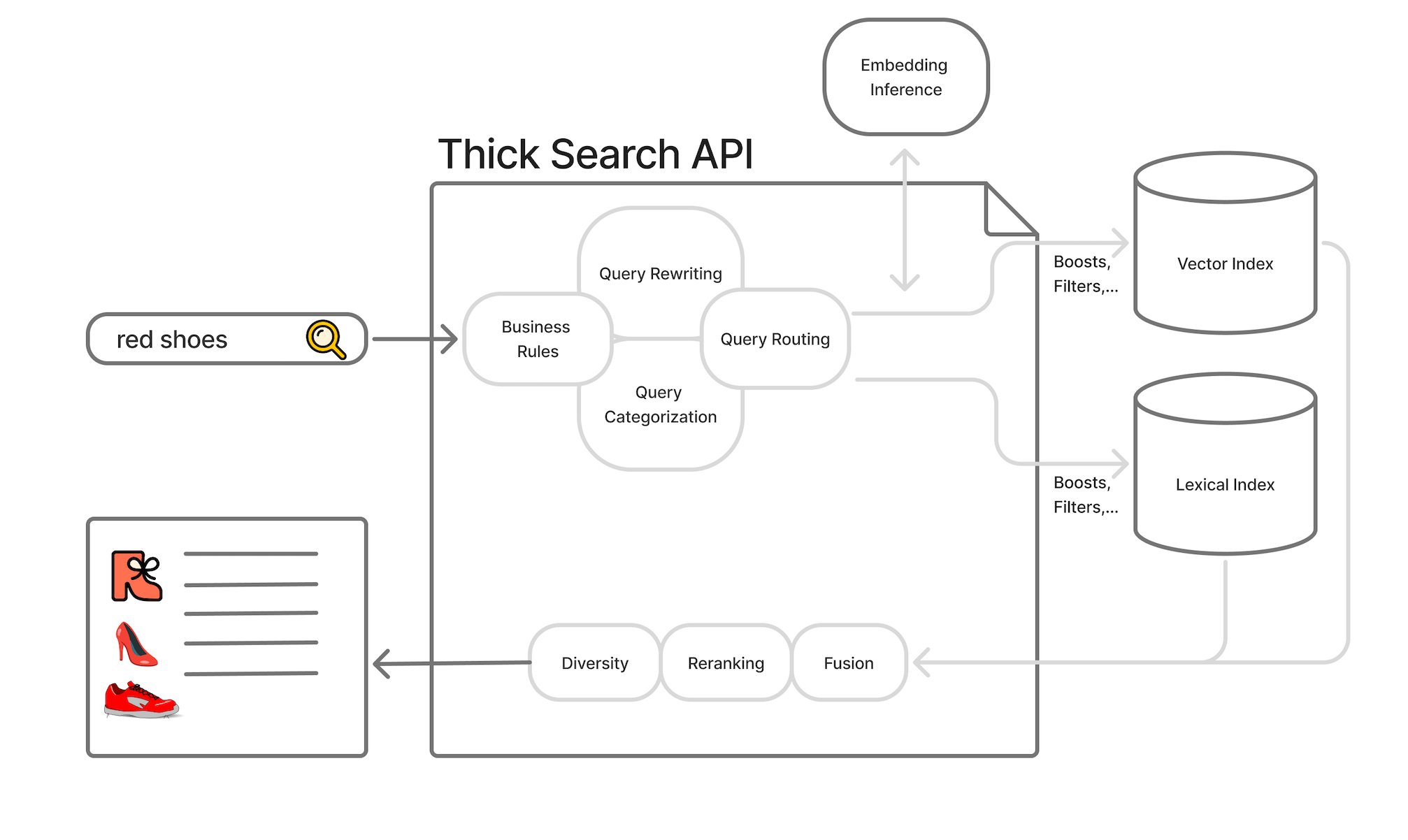
AI 검색에서 내 콘텐츠가 인용 안 되는 진짜 이유, 499 에러와 적격성
ChatGPT·Perplexity 인용에서 조용히 탈락하게 만드는 HTTP 499 에러. 콘텐츠가 아닌 인프라 속도가 AI 검색 적격성을 결정하는 구조를 설명합니다.
Written by

AI 검색은 지금 자기 환각을 인용하고 있다, 검색 오염의 실제 속도
AI 검색이 AI가 쓴 허위 콘텐츠를 실시간으로 인용하는 ‘검색 오염’ 현상 분석. 모델 재학습 없이도 크롤러 속도로 오염이 퍼지는 구조를 설명합니다.
Written by
LLM을 위키 편집자로, Karpathy의 지식 베이스 구축법
Andrej Karpathy가 공개한 LLM 기반 개인 지식 베이스 구축법. RAG와 달리 LLM이 마크다운 위키를 직접 작성·유지해 지식이 쌓이는 구조를 소개합니다.
Written by

클래식 RAG의 실패 지점, 에이전틱 RAG가 다른 이유
클래식 RAG의 단방향 파이프라인이 왜 조용히 실패하는지, 에이전틱 RAG의 루프 구조가 어떻게 다른지를 비교 분석합니다.
Written by

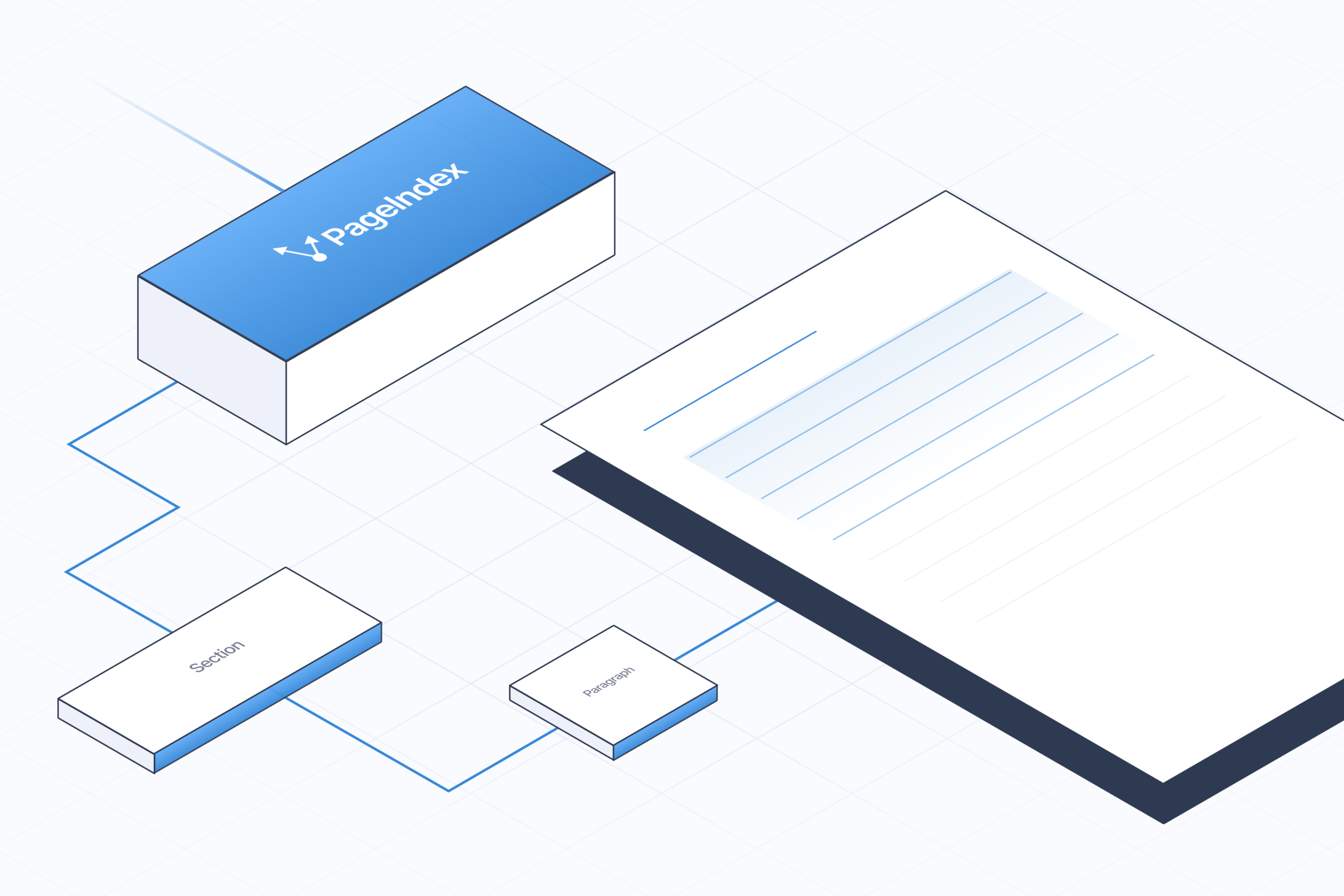
벡터 DB 없이 RAG 정확도 높이는 두 가지 방법, Vercel과 PageIndex
벡터 유사도 검색의 한계를 넘는 두 가지 접근법 소개. Vercel의 파일시스템+bash 에이전트와 PageIndex의 추론 트리 방식을 비교합니다.
Written by
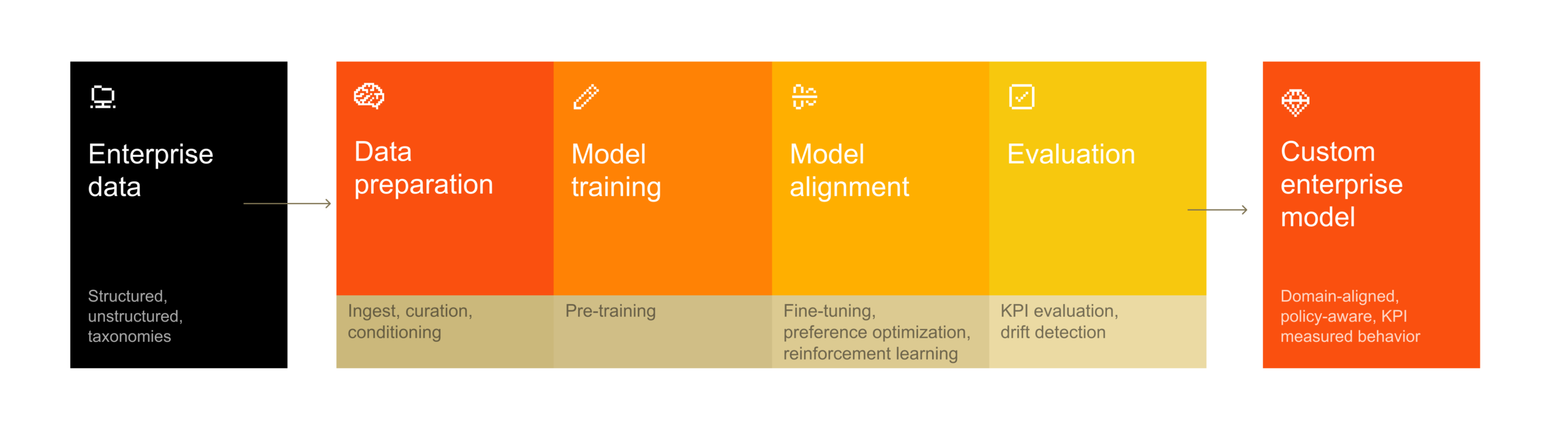
Mistral Forge, Mistral이 제안하는 기업 전용 AI 훈련 플랫폼
Mistral AI가 공개한 기업 전용 AI 모델 훈련 플랫폼 Forge. RAG·파인튜닝을 넘어 기업이 자체 데이터로 모델을 직접 소유하는 접근을 소개합니다.
Written by
Gemini Embedding 2, 텍스트·이미지·영상·오디오를 하나의 공간에 통합한 방법
Google DeepMind의 Gemini Embedding 2는 텍스트·이미지·영상·오디오·문서를 하나의 벡터 공간에 통합한 최초의 네이티브 멀티모달 임베딩 모델입니다. 멀티모달 AI 파이프라인을 단순화합니다.
Written by

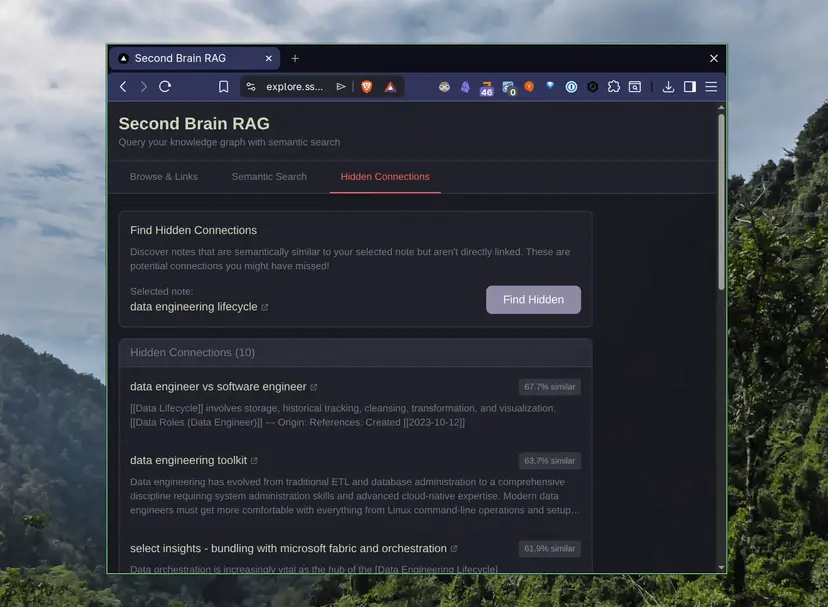
Obsidian 노트에 AI 검색을 붙인다면? DuckDB로 만드는 개인 지식 어시스턴트
Obsidian 노트 8천 개에 AI 검색을 붙인 사례. DuckDB를 벡터 DB로 활용해 의미 기반 검색과 숨겨진 연결을 찾는 방법을 소개합니다.
Written by
OpenAI의 사내 데이터 에이전트, 600페타바이트 속에서 답 찾는 법
OpenAI가 600페타바이트 데이터를 자연어로 분석하는 사내 에이전트 아키텍처 공개. 코드 크롤링, 6개 레이어 컨텍스트, 자가 수정 메커니즘 분석.
Written by
