지금까지 AI 모델은 역할별로 따로 써야 했습니다. 복잡한 추론이 필요하면 Magistral, 이미지 분석에는 Pixtral, 코딩 에이전트에는 Devstral. 그런데 Mistral AI가 이 세 가지를 하나로 합쳤습니다.

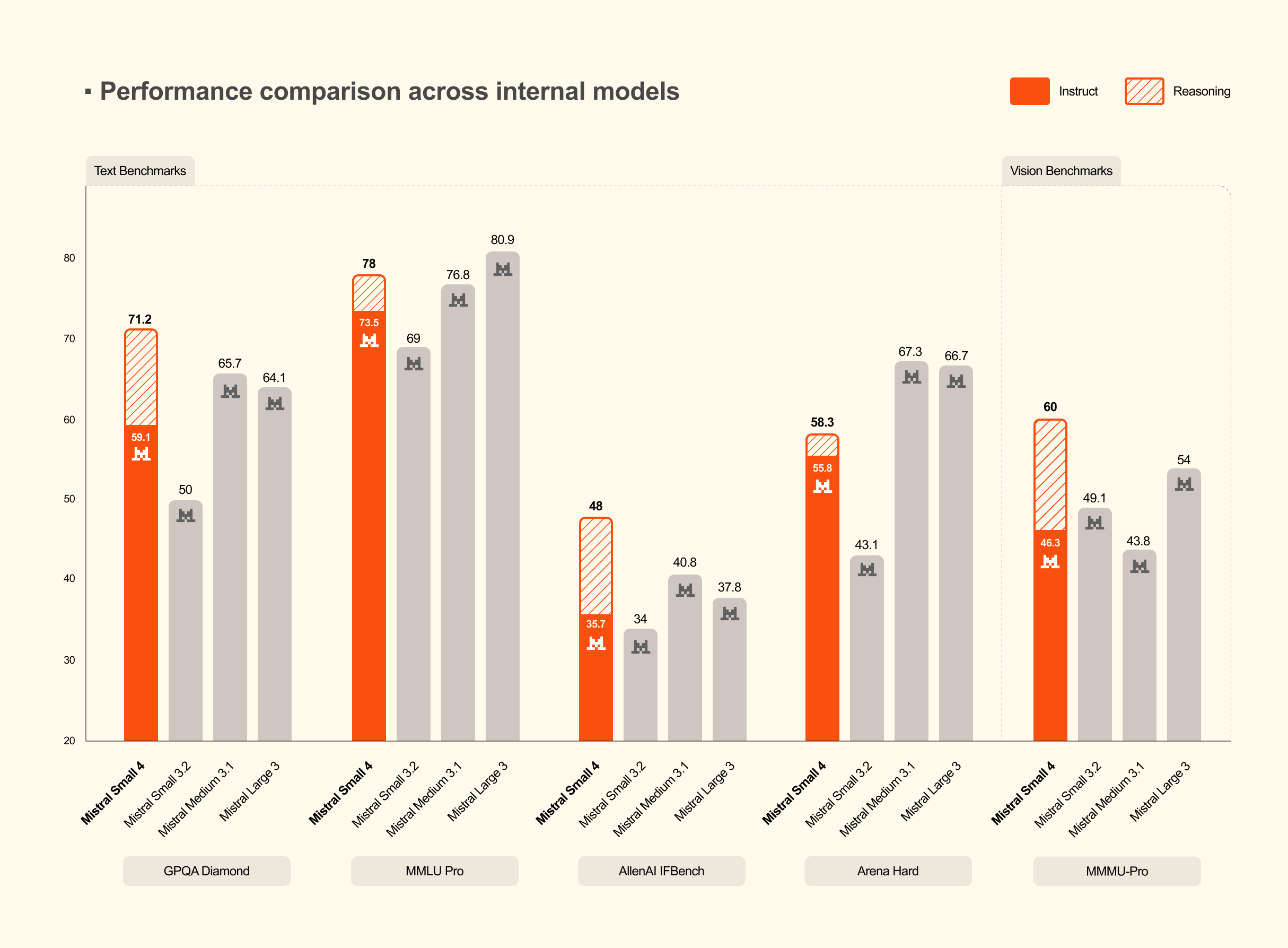
Mistral AI가 3월 16일 Mistral Small 4를 공개했습니다. 총 파라미터 119B 규모의 오픈소스 모델로, 채팅·추론·멀티모달·코딩 에이전트 기능을 단일 모델에 통합했다는 점이 핵심입니다. Apache 2.0 라이선스로 공개되어 상업적 활용과 파인튜닝 모두 가능합니다.
출처: Introducing Mistral Small 4 – Mistral AI
128개 전문가, 한 번에 4개만 쓴다
Mistral Small 4는 MoE(Mixture of Experts) 아키텍처를 씁니다. 모델 안에 128개의 ‘전문가’ 모듈이 있고, 토큰을 처리할 때마다 그 중 4개만 선택해 활성화하는 방식이죠. 전체 파라미터는 119B이지만 실제로 연산에 쓰이는 건 6B 수준에 불과합니다.
이 구조의 장점은 규모와 효율을 동시에 잡을 수 있다는 점입니다. 파라미터 수는 대형 모델 수준이라 복잡한 작업도 처리할 수 있고, 실제 연산량은 소형 모델 수준으로 유지돼 속도와 비용 부담이 줄어듭니다. Mistral은 전작 Small 3 대비 지연 시간을 40% 줄이고 처리량을 3배 늘렸다고 밝혔습니다. 컨텍스트 창은 256k 토큰으로, 긴 문서 분석에도 충분한 수준입니다.
추론 깊이를 그때그때 조절한다
가장 눈에 띄는 기능은 reasoning_effort 파라미터입니다. API 호출 시 이 값을 "none"으로 설정하면 Mistral Small 3.2와 동일한 빠른 채팅 스타일로 응답하고, "high"로 설정하면 이전 Magistral 모델 수준의 단계적 심층 추론을 수행합니다.
즉, 같은 모델 하나로 일반 대화 요청과 수학 문제풀이, 복잡한 코드 분석을 모두 처리하면서 상황에 맞게 계산 자원 사용량을 조절할 수 있는 셈입니다. 다만 Simon Willison은 이 파라미터가 Mistral API 공식 문서에는 아직 반영되지 않았다고 지적했습니다.
짧게 쓰고도 잘 한다
Mistral Small 4가 특히 강조한 것은 출력 효율성입니다. 내부 벤치마크 세 개(LCR, LiveCodeBench, AIME 2025)에서 GPT-OSS 120B와 비슷하거나 높은 정확도를 기록하면서도, 출력 문자 수는 경쟁 모델보다 훨씬 적었습니다.
예를 들어 LCR 벤치마크에서 Mistral Small 4는 1,600자 수준의 출력으로 0.72점을 기록했는데, 비슷한 점수를 내는 Qwen 계열 모델은 5,800~6,100자를 사용했습니다. 출력이 짧다는 건 응답 속도가 빠르고 추론 비용이 낮다는 의미이기도 합니다.
오픈소스 통합 모델의 방향
Mistral Small 4는 특수 목적 모델 여럿을 유지하는 대신 하나의 범용 모델로 수렴하려는 접근을 보여줍니다. 개발자 입장에서는 코딩, 문서 이해, 멀티모달 작업에 각각 다른 모델을 관리할 필요 없이 단일 배포로 처리할 수 있다는 실용적 의미가 있습니다.
현재 Mistral API, Hugging Face, NVIDIA build.nvidia.com에서 사용할 수 있으며 vLLM, llama.cpp, SGLang 등 주요 오픈소스 추론 프레임워크도 지원합니다. 구체적인 아키텍처 상세와 벤치마크 전체 수치는 원문에서 확인할 수 있습니다.
참고자료: Introducing Mistral Small 4 – Simon Willison
답글 남기기